Category Archives: Data Science
Pearson vs Spearman: Choosing the Right Correlation Coefficient
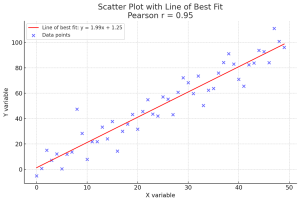
Are you as a data scientist trying to decipher relationship between two or more variables within vast datasets to solve real-world problems? Whether it’s understanding the connection between physical exercise and heart health, or the link between study habits and exam scores, uncovering these relationships is crucial. But with different methods at our disposal, how do we choose the most suitable one? This is where the concept of correlation comes into play, and particularly, the choice between Pearson and Spearman correlation coefficients becomes pivotal. The Pearson correlation coefficient is the go-to metric when both variables under consideration follow a normal distribution, assuming there’s a linear relationship between them. Conversely, the …
Pearson Correlation Coefficient: Formula, Examples
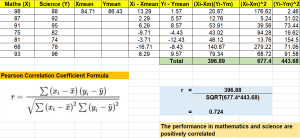
In the world of data science, understanding the relationship between variables is crucial for making informed decisions or building accurate machine learning models. Correlation is a fundamental statistical concept that measures the strength and direction of the relationship between two variables. However, without the right tools and knowledge, calculating correlation coefficients and p-values can be a daunting task for data scientists. This can lead to suboptimal decision-making, inaccurate predictions, and wasted time and resources. In this post, we will discuss what Pearson’s r represents, how it works mathematically (formula), its interpretation, statistical significance, and importance for making decisions in real-world applications such as business forecasting or medical diagnosis. We will …
t-distribution vs Normal distribution: Differences, Examples
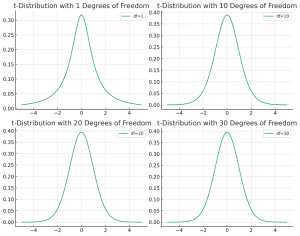
Understanding the differences between the t-distribution and the normal distribution is crucial for anyone delving into the world of statistics, whether they’re students, professionals in research, or data enthusiasts trying to make sense of the world through numbers. But why should one care about the distinction between these two statistical distributions? The answer lies in the heart of hypothesis testing, confidence interval estimation, and predictive modeling. When faced with a set of data, choosing the correct distribution to describe it can greatly influence the accuracy of your conclusions. The normal distribution is often the default assumption due to its simplicity and the central limit theorem, which states that the means …
Problems with Categorical Variables: Examples
Have you ever encountered unfamiliar words while learning a new language and didn’t know their meanings? Or tried to fit all your belongings into a suitcase, only to realize it’s too full? Or started reading a book series from the third book and felt lost? These scenarios in our daily lives surprisingly resemble some challenges we face with categorical variables in machine learning. Categorical variables, while essential in many datasets, bring with them a unique set of challenges. In this article, we’ll be discussing three major problems associated with categorical features: Let’s explore each with real-life examples and supporting Python code snippets. Incomplete Vocabulary The “Incomplete Vocabulary” problem arises when …
Central Tendency in Machine Learning: Python Examples
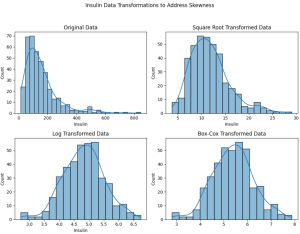
Have you ever wondered why your machine learning model is not performing as expected? Could the “average” behavior of your dataset be misleading your model? How does the “central” or “typical” value of a feature influence the performance of a machine learning model? In this blog, we will explore the concept of central tendency, its significance in machine learning, and the importance of addressing skewness in your dataset. All of this will be demonstrated with the help of Python code examples using a diabetes dataset. We will be working with the diabetes dataset which can be found on Kaggle – Diabetes Dataset. The dataset consists for multiple columns such as …
Data Analytics for Car Dealers: Actionable Insights
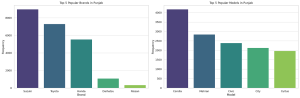
Are you starting a car dealership and wondering how to leverage data to make informed business decisions? In today’s data-driven world, analytics can be the difference between a thriving business and a failing one. This blog aims to provide actionable insights for car dealers, especially those starting new car dealer business, to excel in various business aspects. I will cover inventory management, pricing strategy, marketing and sales, customer service, and risk mitigation, all backed by data analytics. I will continue to update this blog with more methods in time to come. The data used for analysis can be found on the Kaggle.com – Ultimate Car Price Prediction Dataset. First and …
Insurance & Linear Regression Model Example
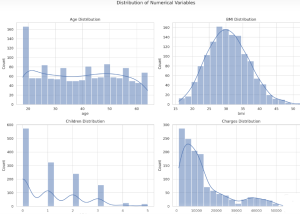
Ever wondered how insurance companies determine the premiums you pay for your health insurance? Predicting insurance premiums is more than just a numbers game—it’s a task that can impact millions of lives. In this blog, we’ll demystify this complex process by walking you through an end-to-end example of predicting health insurance premium charges by demonstrating with Python code example. Specifically, we’ll use a linear regression model to predict these charges based on various factors like age, BMI, and smoking status. Whether you’re a beginner in data science or a seasoned professional, this blog will offer valuable insights into building and evaluating regression models. What is Linear Regression? Linear Regression is …
Chi-square test – Formula, Concepts, Examples
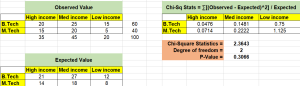
The Pearson’s Chi-square (χ2) test is a statistical test used to determine whether the distribution of observed data is consistent with the distribution of data expected under a particular hypothesis. The Chi-square test can be used to compare or evaluate the independence of two distributions, or to assess the goodness of fit of a given distribution to observed data. In this blog post, we will discuss different types of Chi-square tests, the concepts behind them, and how to perform them using Python / R. As data scientists, it is important to have a strong understanding of the Chi-square test so that we can use it to make informed decisions about …
Microsoft’s Free Courses: Data Science, Machine Learning, AI

Are you keen on diving into the world of data science, machine learning, or artificial intelligence? Have you been searching for courses that not only teach the fundamentals but are also free and accessible? Look no further! Microsoft has put together three distinct courses that will cater to your interests and ignite your passion for learning. Data Science for Beginners This course offers an ideal starting point for those new to data science, focusing on the basics and guiding through practical exercises. The course would help you demystify the complex world of data, allowing you to make informed decisions in various fields such as business, healthcare, and more. Each lesson …
Hypothesis Testing Steps & Examples
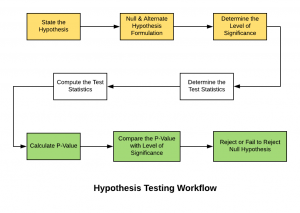
Hypothesis testing is a technique that helps scientists, researchers, or for that matter, anyone test the validity of their claims or hypotheses about real-world or real-life events in order to establish new knowledge. Hypothesis testing techniques are often used in statistics and data science to analyze whether the claims about the occurrence of the events are true, whether the results returned by performance metrics of machine learning models are representative of the models or they happened by chance. This blog post will cover some of the key statistical concepts including steps and examples in relation to what is hypothesis testing, how to formulate them and how to use them in …
7 Free MIT AI / Machine Learning Courses: Enroll Now!

Are you eager to dive into the world of machine learning and AI but worried about the costs? Are you fascinated by how data analytics can shape the future of various industries? What if you could access top-notch education from one of the leading institutions in the world, absolutely free? In the next six months, MIT is offering seven upcoming free courses designed to equip you with the knowledge and skills in machine learning, AI, and data analytics. Whether you’re a seasoned professional looking to upskill or a beginner ready to embark on a new journey, these courses provide an incredible opportunity. In this blog, we’ll delve into the details …
IIT Madras Fellowship in AI for Social Good

Are you an AI researcher driven by the passion to make a positive impact on society? Do you seek to use your knowledge in machine learning and AI to contribute to real-world issues? Are you intrigued by the idea of joining a leading interdisciplinary research center for data science in India? Then here is the opportunity to discover a unique opportunity that aligns with your aspirations and expertise at the Robert Bosch Centre for Data Science and Artificial Intelligence (RBCDSAI), IIT Madras. Apply Now for fellowship program in AI for social good. About RBCDSAI RBCDSAI is one of India’s pre-eminent interdisciplinary research academic centers specializing in Data Science and AI. …
Machine Learning Projects for Final Year Students: Examples

As aspiring data scientists, computer scientists, and statisticians, the final year of your academic journey presents a perfect opportunity to showcase your skills and knowledge in practical applications. In this blog, we will explore a diverse set of exciting machine-learning projects that are well-suited for final-year students. These projects cover various domains, including education, healthcare, crime prediction, and more. We will delve into each project’s description, problem type (classification, regression, etc.), and the methods used for analysis. Whether you are seeking inspiration for your final year project or simply eager to explore the power of machine learning in real-world scenarios, this blog has something for everyone! In case you would …
Huggingface Transformers Hello World: Python Example
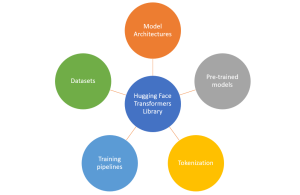
Pre-trained models have revolutionized the field of natural language processing (NLP), enabling the development of advanced language understanding and generation systems. Hugging Face, a prominent organization in the NLP community, provides the “transformers” library—a powerful toolkit for working with pre-trained models. In this blog post, we’ll explore a “Hello World” example using Hugging Face’s Python library, uncovering the capabilities of pre-trained models in NLP tasks. With Hugging Face’s transformers library, we can leverage the state-of-the-art machine learning models, tokenization tools, and training pipelines for different NLP use cases. We’ll discuss the importance of pre-trained models in NLP, provide an overview of Hugging Face’s offerings, and guide you through an example …
NPTEL’s Machine Learning & Data Science Online Courses (Jul-Nov 2023)

In the rapidly evolving domains of Machine Learning, Data Science, and Artificial Intelligence, the quest for quality education and courses has become paramount. For those familiar with the educational landscape of India, the Indian Institutes of Technology (IITs) stand out as beacons of excellence. Established by the government of India, the IITs are autonomous public technical universities that are recognized globally for their outstanding curriculum, research, and innovation. Every year, thousands of students vie for a coveted spot in these institutions, and their alumni have made significant contributions to technology and research worldwide. NPTEL (National Programme on Technology Enhanced Learning), in collaboration with these premier IITs, has curated a range …
Autoregressive (AR) Models Python Examples: Time-series Forecasting
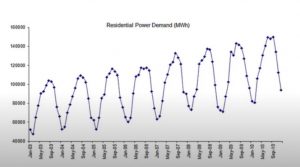
Autoregressive (AR) models, which are used for text generation tasks and time series forecasting, can be employed to predict future values predicated on previous observations. This blog post will provide the concepts of autoregressive (AR) models with Python code examples to demonstrate how you can implement an AR model for time-series forecasting. Note that time-series forecasting is one of the important areas of data science/machine learning. In subsequent blogs, we will take up the topic of how autoregressive models can be used as generative model for text generation tasks. For beginners, time-series forecasting is the process of using a model to predict future values based on previously observed values. Time-series data …
I found it very helpful. However the differences are not too understandable for me