Category Archives: Deep Learning
Mathematics Topics for Machine Learning Beginners
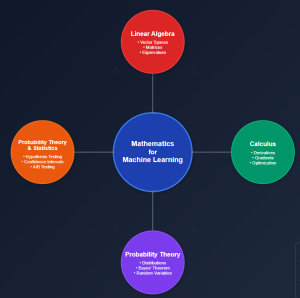
In this blog, you would get to know the essential mathematical topics you need to cover to become good at AI & machine learning. These topics are grouped under four core areas including linear algebra, calculus, multivariate calculus and probability theory & statistics. Linear Algebra Linear algebra is arguably the most important mathematical foundation for machine learning. At its core, machine learning is about manipulating large datasets, and linear algebra provides the tools to do this efficiently. Vector Spaces and Operations Matrices: Your Data’s Best Friend Eigenvalues and Eigenvectors Matrix Decompositions Calculus Machine learning is fundamentally about optimization – finding the best parameters that minimize error in the loss function. …
Sparse Mixture of Experts (MoE) Models: Examples
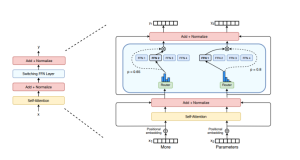
With the increasing demand for more powerful machine learning (ML) systems that can handle diverse tasks, Mixture of Experts (MoE) models have emerged as a promising solution to scale large language models (LLM) without the prohibitive costs of computation. In this blog, we will delve into the concept of MoE, its history, challenges, and applications in modern transformer architectures, particularly focusing on the role of Google’s GShard and Switch Transformers. What is a Mixture of Experts (MoE) Model? Mixture of Experts (MoE) model represents a neural network architecture that divides a model into multiple sub-components (neural network) called experts. Each expert is designed to specialize in processing specific types of …
Credit Card Fraud Detection & Machine Learning

Last updated: 26 Sept, 2024 Credit card fraud detection is a major concern for credit card companies. With credit cards so prevalent in our society, credit card companies must be able to prevent fraud happening with credit card transactions and protect their customers. Machine learning techniques can provide a powerful and effective way of detecting fraud happening with transactions done using credit cards. In this blog post we will discuss ML techniques that data scientists can use to design appropriate fraud detection solutions including algorithms such as Bayesian networks, support vector machines, neural networks and decision trees. What are different types of credit card fraud? The following are different types …
Neural Network Types & Real-life Examples
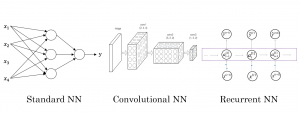
Last updated: 24th Sept, 2024 Neural networks are a powerful tool for data scientists, machine learning engineers, and statisticians. They have revolutionized the field of deep learning and have become an integral part of many real-world applications such as image and speech recognition, natural language processing (NLP), autonomous vehicles, etc. ChatGPT is a classic example how neural network applications has taken world by storm. But what exactly are they and what are their different types? Understanding the different types of neural networks and their real-life examples is crucial. In this blog post, we’ll explore different types of neural networks (ANN, CNN, RNN, LSTM, etc.) , provide real-life examples of how …
Difference: Binary vs Multiclass vs Multilabel Classification

Last updated: 13th Sep, 2024 There are three main types of classification algorithms when dealing with machine learning classification problems: Binary, Multiclass, and Multilabel. In this blog post, we will discuss the differences between them and how they can be used to solve different classification problems. Binary classifiers can only classify data into two categories, while multiclass classifiers can classify data into more than two categories. Multilabel classifiers assign or tag the data to zero or more categories. Let’s take a closer look at each type! Binary classification & examples Binary classification is used to represent classification technique in supervised machine learning in which data is classified into two mutually …
Model Parallelism vs Data Parallelism: Examples

Last updated: 24th August, 2024 Model parallelism and data parallelism are two strategies used to distribute the training of large machine-learning models across multiple computing resources, such as GPUs. They form key categories of multi-GPU training paradigms. These strategies are particularly important in deep learning, where models and datasets can be very large. What’s Data Parallelism? In data parallelism, we break down the data into small batches. Each GPU works on one batch of data at a time. It calculates two things: the loss, which tells us how far off our model’s predictions are from the actual outcomes, and the loss gradients, which guide us on how to adjust the …
Self-Supervised Learning: Concepts, Examples
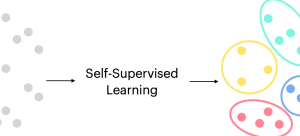
Last updated: 20th August, 2024 Self-supervised learning is an approach to training machine learning models primarily for large corpus of unlabeled dataset. It has gained significant traction due to its effectiveness in various applications related to text and image. Self-supervised learning differs from supervised learning, where models are trained using labeled data, and unsupervised learning, where models are trained using unlabeled data without any pre-defined objectives. Instead, self-supervised learning defines pretext tasks as training models to extract useful features from the data that can be later fine-tuned for specific downstream tasks. The potential of self-supervised learning has already been demonstrated in many real-world applications, such as image classification, natural language …
Autoencoder vs Variational Autoencoder (VAE): Differences, Example
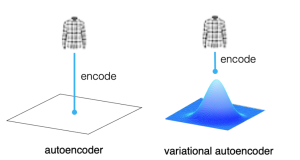
Last updated: 12th May, 2024 In the world of generative AI models, autoencoders (AE) and variational autoencoders (VAEs) have emerged as powerful unsupervised learning techniques for data representation, compression, and generation. While they share some similarities, these algorithms have unique properties and applications that distinguish them. This blog post aims to help machine learning / deep learning enthusiasts understand these two methods, their key differences, and how they can be utilized in various data-driven tasks. We will learn about autoencoders and VAEs, understanding their core components, working mechanisms, and common use cases. We will also try and understand their differences in terms of architecture, objectives, and outcomes. What are Autoencoders? …
Self-Prediction vs Contrastive Learning: Examples

In the dynamic realm of AI, where labeled data is often scarce and costly, self-supervised learning helps unlock new machine learning use cases by harnessing the inherent structure of data for enhanced understanding without reliance on extensive labeled datasets as in the case of supervised learning. Simply speaking, self-supervised learning, at its core, is about teaching models to learn from the data itself, turning unlabeled data into a rich source of learning. There are two distinct methodologies used in self-supervised learning. They are the self-prediction method and contrastive learning method. In this blog, we will learn about their concepts and differences with the help of examples. What is the Self-Prediction …
Large Language Models (LLMs): Types, Examples
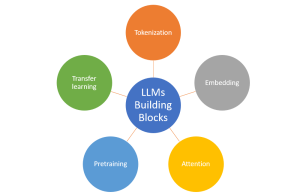
Last updated: 31st Jan, 2024 Large language models (LLMs), being the key pillar of generative AI, have been gaining traction in the world of natural language processing (NLP) due to their ability to process massive amounts of text and generate accurate results related to predicting the next word in a sentence, given all the previous words. These different LLM models are trained on a large or broad corpus of text datasets, which contain hundreds of millions to billions of words. LLMs, as they are known, rely on complex algorithms including transformer architectures that shift through large datasets and recognize patterns at the word level. This data helps the LLMs better understand …
Transfer Learning vs Fine Tuning LLMs: Differences
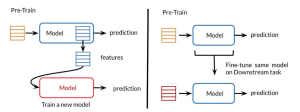
Last updated: 23rd Jan, 2024 Two NLP concepts that are fundamental to large language models (LLMs) are transfer learning and fine-tuning pre-trained LLMs. Rather, true fine-tuning can also be termed as full fine-tuning because transfer learning is also a form of fine-tuning. Despite their interconnected nature, they are distinct methodologies that serve unique purposes when training foundation LLMs to achieve different objectives. In this blog, we will explore the differences between transfer Learning and full fine-tuning, learning about their characteristics and how they come into play in real-world scenarios related to natural language understanding (NLU) and natural language generation (NLG) tasks with the help of examples. We will also learn …
Transformer Architecture in Deep Learning: Examples
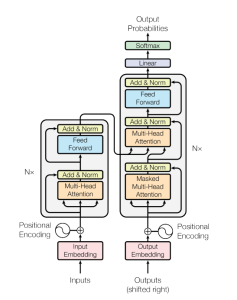
The Transformer model architecture, introduced by Vaswani et al. in 2017, is a deep learning model that has revolutionized the field of natural language processing (NLP) giving rise to large language models (LLMs) such as BERT, GPT, T5, etc. In this blog, we will learn about the details of transformer model architecture with the help of examples and references from the mother paper – Attention is All You Need. Transformer Block – Core Building Block of Transformer Model Architecture Before getting to understand the details of transformer model architecture, let’s understand the key building block termed transformer block. The core building block of the Transformer architecture consists of multi-head attention …
Instruction Fine-tuning LLM Explained with Examples

A pre-trained or foundation model is further trained (or fine-tuned) with instructions datasets to help them learn about your specific data and perform humanlike tasks. These models are called instruction fine-tuning LLMs. In this blog, we will learn about the concepts and different examples of instruction fine-tuning models. You might want to check out this book to learn more: Generative AI on AWS. What are Instruction fine-tuning LLMs? Instruction fine-tuning LLMs, also called chat or instruct models, are created by training pre-trained models with different types of instructions. Instruction fine-tuning can be defined as a type of supervised machine learning that improves the foundation model by continuously comparing the model’s …
Distributed LLM Training & DDP, FSDP Patterns: Examples

Training large language models (LLMs) like GPT-4 requires the use of distributed computing patterns as there is a need to work with vast amounts of data while training with LLMs having multi-billion parameters vis-a-vis limited GPU support (NVIDIA A100 with 80 GB currently) for LLM training. In this blog, we will delve deep into some of the most important distributed LLM training patterns such as distributed data parallel (DDP) and Fully sharded data parallel (FSDP). The primary difference between these patterns is based on how the model is split or sharded across GPUs in the system. You might want to check out greater details in this book: Generative AI on …
Transformer Architecture Types: Explained with Examples
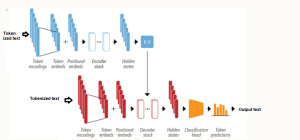
Are you fascinated by the power of deep learning large language models that can generate creative writing, answer complex questions, etc? Ever wondered how these LLMs understand and process human language with such finesse? At the heart of these remarkable achievements lies a machine learning model architecture that has revolutionized the field of Natural Language Processing (NLP) – the Transformer architecture and its types. But what makes Transformer models so special? From encoding sentences into numerical embeddings to employing attention mechanisms that capture the relationships between words, we will dissect different types of Transformer architectures, provide real-world examples, and even dive into the mathematics that governs its operation. Let’s explore …
Pre-trained Models Explained with Examples
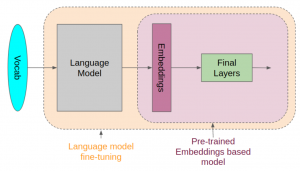
NLP has been around for decades, but it has recently seen an explosion in popularity due to pre-trained models (PTMs), also termed foundation models. This blog post will introduce you to different types of pre-trained (a.k.a. foundation) machine learning models and discuss their usage in real-world examples. Before we get into looking at different types of pre-trained models in NLP, let’s understand the concepts related to pre-trained models. What are Pre-trained Models? Pre-trained models (PTMs) are very large and complex neural network-based deep learning models, such as transformers, that consist of billions of parameters (a.k.a. weights) and have been trained on very large datasets to perform specific NLP tasks. The …

I found it very helpful. However the differences are not too understandable for me