Last updated: 25th Jan, 2025
Have you ever wondered how to seamlessly integrate the vast knowledge of Large Language Models (LLMs) with the specificity of domain-specific knowledge stored in file storage, relational databases, graph databases, vector databases, etc? As the world of LLMs continues to evolve, the need for more sophisticated and contextually relevant responses from LLMs becomes paramount. Lack of contextual knowledge can result in LLM hallucination thereby producing inaccurate, unsafe, and factually incorrect responses. This is where question & context augmentation to prompts is used for contextually sensitive answer generation with LLMs, and, the retrieval-augmented generation method, comes into the picture. For data scientists and product managers keen on deploying contextually sensitive LLMs in production, the Retrieval-Augmented Generation (RAG) pattern offers a compelling solution if they want to leverage contextual information with prompts sent by the end users. Apart from RAG, one can also go for LLM fine tuning. This blog will dive deep into the LLM RAG pattern, illustrating its power and potential with practical real-world examples. Whether you’re aiming to enhance your product’s generative AI capabilities or simply curious about the next big thing in AI / ML and LLMs, this RAG LLM tutorial is tailored just for you.
What is the Retrieval Augmented Generation (RAG) Pattern for leveraging LLMs?
The Retrieval Augmented Generation (RAG) pattern is a generative AI design pattern that combines the capabilities of large language models (LLMs) with contextual information stored in different forms of data storage such as vector databases, relational databases, graph databases etc.
Let LLM represent a Large Language Model, Question represents user questions which can be LLM-augmented, Context represents documents similar to user questions, and, Prompts represent prompts created using context and question information. The RAG pattern can be mathematically formulated as:
RAG=f(Question, Context, Prompt, LLM)
Here, f is a function that generates answers based on the prompts passed to LLM. Prompts are created using a Prompt template which takes input as context (documents) and questions.
Instead of relying solely on the pre-trained knowledge of an LLM, the RAG pattern fetches relevant contextual information (documents) from the index data stores (such as vector stores) to provide more informed and accurate responses. The following are key stages of the system implemented based on the RAG pattern:
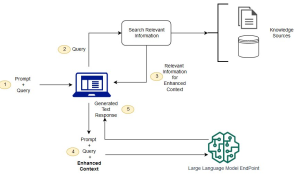
- Retrieval Phase: Given an input query (a question) or translated query, the RAG system first retrieves contextual information from different data sources using a retriever. Different search and indexing techniques such as semantic search, keyword search, metadata search, ColBERT, etc. are used to improve the search of contextual information based on the queries. The data sources as shown in the picture below can be vector databases, document storage, relational databases, graph databases, etc. This is often done using efficient dense vector space methods, like the Dense Passage Retriever (DPR), which embeds both the query and documents into a continuous vector space and retrieves documents based on similarity search methods such as cosine similarity, euclidean distance method, dot product. Once the information is retrieved, it can be ranked (as desired), and formatted in the form which can be input in the prompt template (such as LangChain PromptTemplate) to generate a prompt. The following represents the retrieval phase.
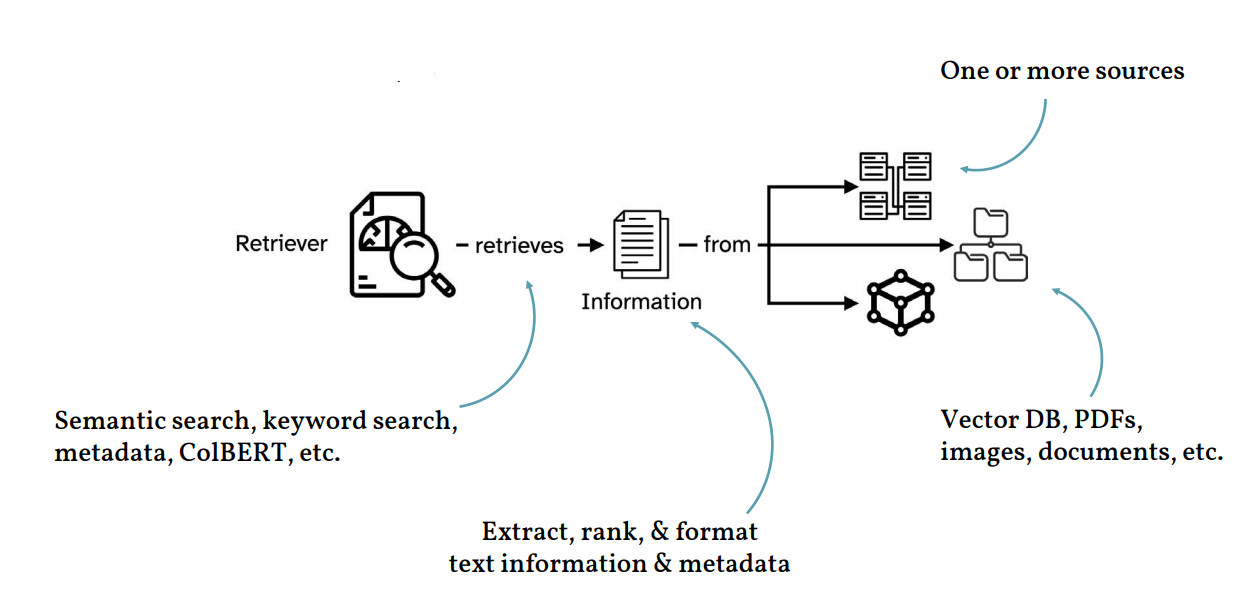
This makes it very important to ensure that the performance of the retriever is very good and fast. Retrievers can also add references to the sources and other metadata information such as dates, etc. - Generation Phase: Once the top-k relevant documents or passages are retrieved as a context, they are combined with the original question in form of a prompt and fed into an LLM. The LLM is then responsible for producing the desired output (like an answer to the question) using both the query and the retrieved passages as context.
The following picture represents a RAG LLM system while showcasing retrievers (explained above) and LLMs working together.
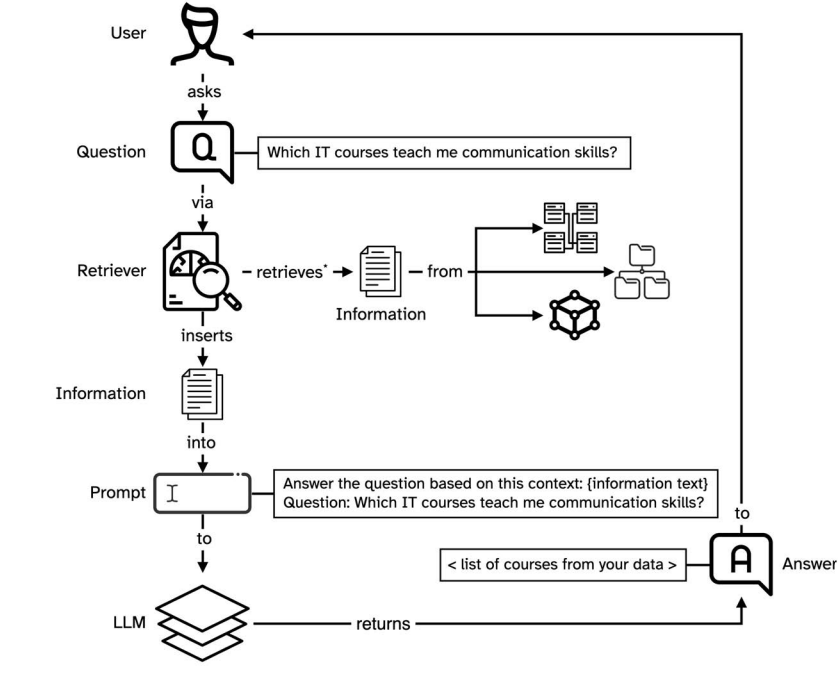
Framework such as LangChain enables query transformations or query optimization to create appropriate query which can be embedded for effective retrieval. Query translation methods such as query rewriting, step-based questions, sub-questions etc. and, query construction can be used to enhance the questions. Query translation methods are used to optimize questions by adding more information to the questions. In query construction, question is converted to appropriate query understood by the data source. For example, text-to-SQL query construction.
Can RAG & fine-tuning be used together?
RAG can be integrated with off-the-shelf foundation models or with fine-tuned and human-aligned models specific to generative use cases and domains. RAG and fine-tuning can be used together. They are not mutually exclusive.
When is RAG useful?
RAG is useful in any case where you want the language model to have access to additional data that is not contained within the LLMs learned during pretraining and fine-tuning. This could be data that did not exist in the original training data, such as proprietary information from your organization’s internal data stores.
RAG LLM Pattern Application Example
Let’s look at a real-life example to understand the RAG LLM pattern.
Imagine you have a vast database of scientific articles, and you want to answer a specific question using an LLM like GPT-4: “What are the latest advancements in CRISPR technology?”
- Without RAG: The LLM might provide a general overview of CRISPR based on its training data, which could be outdated or lack the latest research insights.
- With RAG:
- First, the system would query the database of scientific articles to retrieve the most relevant and recent articles on CRISPR advancements.
- These retrieved articles would then be used as context when posing the question to the LLM.
- The LLM, now equipped with this fresh context, would generate a response that incorporates the latest findings from the retrieved articles, offering a more up-to-date and detailed answer.
Based on the above, we can understand that the RAG pattern enhances the LLM’s capabilities by integrating real-time, external knowledge sources, ensuring that the generated responses are both contextually relevant and informed by the most current information available.
Why implement the RAG pattern?
Implementing the Retrieval Augmented Generation (RAG) pattern in generative AI applications offers a myriad of advantages, particularly for tasks that require nuanced, context-rich, and accurate responses. Here are some expanded insights from my experience:
- Scalability: The RAG LLM architecture brilliantly addresses the scalability issue faced by many generative AI applications. By bifurcating the retrieval and generation processes, the LLM RAG can access and utilize vast external data repositories, essentially extending its knowledge base far beyond what’s hardcoded in the generator. I’ve seen instances where this scalability transformed mediocre systems into robust solutions, capable of handling queries with unprecedented breadth and depth.
- Flexibility: One of the standout features of the RAG pattern is its modular design, offering unparalleled flexibility. This setup allows the retriever component to be updated or swapped out as newer, more efficient algorithms emerge or as the data landscape evolves, without necessitating a complete overhaul of the generator. This aspect is particularly valuable in dynamically changing fields like medical research or trending news, where staying current is crucial.
- Quality of Responses: The true prowess of the RAG LLM is evidenced in the quality of its outputs, especially in open-domain question-answering tasks. Traditional LLM models relying solely on pre-encoded knowledge often falter when faced with novel or niche queries. However, RAG bridges this gap by leveraging its retrieval mechanism to fetch relevant, up-to-date information, which the generator then skillfully incorporates into coherent and contextually rich responses. In my experience, RAG consistently outperforms standard models in delivering accurate and detailed answers.
- Continual Learning: Inherently, RAG supports a form of continual learning. As new information gets added to the external corpus, the LLM RAG can access this updated data during the retrieval phase, ensuring the responses remain relevant over time. This feature is a game-changer in fields where information is constantly evolving, such as legal precedents or scientific discoveries.
- Customization for Specific Domains: The RAG pattern can be tailored to specific use cases. For instance, in a legal application, the retriever can be fine-tuned to fetch data from legal documents and case law, while the generator is optimized for legalese comprehension and generation. This customization potential allows RAG to excel in niche domains, offering precise and specialized responses.
Key Steps for Implementing the LLM RAG Pattern
Let’s delve into the steps involved in leveraging the RAG pattern for LLM, supplemented with examples:
Step 1. Deploy Large Language Model (LLMs) Deploy a large language model, such as OpenAI’s GPT series. These models are trained on vast amounts of text, enabling them to generate human-like text based on the input they receive. For instance, imagine deploying GPT-4 to answer questions about world history. While LLMs can answer a wide range of questions, their responses are based solely on their training data.
Step 2. Ask a Question to LLM: Pose a question to the LLM without giving any specific context. For example, asking “Who was Cleopatra?” without specifying which Cleopatra or any other context might yield a generic response like “Cleopatra was a famous Egyptian queen.” This highlights the inherent limitations of LLMs.
Step 3. Improve the Answer by adding insightful context to the Same Question based on the RAG based. By refining the question or providing additional context, you can guide the LLM to produce a more accurate or detailed answer. For instance, asking “What was Cleopatra VII’s role in Roman history?” might generate a more specific answer such as “Cleopatra VII was known for her relationships with Roman leaders Julius Caesar and Mark Antony.”
In our quest to harness the full potential of Large Language Models (LLMs), it is recommended to use a Retrieval Augmented Generation (RAG) approach to add the above insightful context. The core idea is to utilize document embeddings to pinpoint the most pertinent documents from our expansive knowledge library. These documents are then amalgamated with specific prompts when querying the LLM. The following represents a step-by-step process to achieve RAG. The picture (courtesy: RAG on AWS) below represents the steps mentioned below.
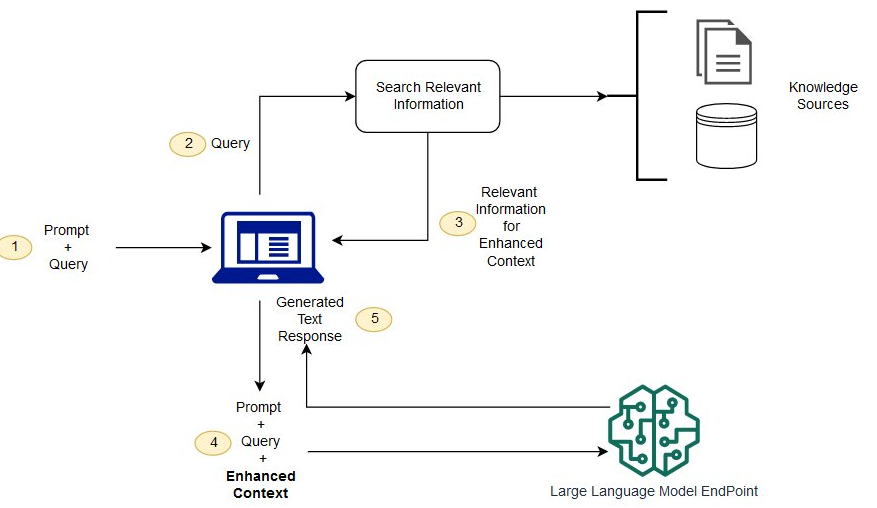
- Deploying the Model Endpoint for Embedding Model: Before you can retrieve relevant documents, you need an embedding model that can convert text into numerical vectors. Consider deploying a BERT-based model to generate embeddings for historical texts. These embedding models capture the semantic essence of documents, making them crucial for similarity-based retrieval. You can also use vector database services such as Pinecone. Pinecone can be used to store document embeddings and then query them.
- Generate Embeddings for Each Document in the Knowledge Library with the Embedding Model: Convert each document in your knowledge library into a vector representation. For instance, transforming texts about ancient civilizations into numerical vectors will serve as the foundation for indexing and retrieval. Recall that the embeddings are a way of representing text, or really any kind of data, in a numerical format, typically as dense vectors in a high-dimensional space. When it comes to text, these embeddings are generated using various Natural Language Processing (NLP) models that can capture the semantic essence of the content. The beauty of embeddings is that semantically similar items (like documents or words) will have similar embeddings, i.e., they’ll be close to each other in the embedding space.
- Index the Embedding Knowledge Library: Algorithms such as K-Nearest Neighbors (KNN) algorithm can be used to index the generated embeddings. As an example, you might be indexing embeddings of texts about Roman, Greek, and Egyptian civilizations. KNN provides a scalable and efficient way to search through large datasets, ensuring that the most relevant documents are retrieved quickly.
- Retrieve the Most Relevant Documents: Based on the query’s embedding, retrieve the top ‘k’ most similar documents from the indexed knowledge library. For a query about “Roman architecture,” you might retrieve documents discussing the Colosseum, aqueducts, and Roman temples. This ensures that the LLM has access to the most relevant external information when generating a response.
- Combine the Retrieved Documents, Prompt, and Question to Query the LLM: The final step involves feeding the LLM with the retrieved documents, the refined prompt, and the original question. For instance, combining documents about the Colosseum with the question “How did Romans use the Colosseum?” might yield a detailed answer like “Romans used the Colosseum for gladiatorial contests and public spectacles.”
The following is how we can use Pinecone for storing document embeddings and then later querying the embedding storage to get a similar text or document. This is then combined with questions and prompts and sent to LLM to get more accurate results.
- Storing Document Embeddings:
- Text to Vector: First, you need to convert your text documents into embeddings using an NLP model, like BERT, sBERT, RoBERTa, or any other model suitable for your data.
- Pinecone Initialization: Initialize Pinecone and create a new vector index to store the document embeddings.
- Uploading Vectors: Using Pinecone’s APIs, you can then batch upload your document embeddings to the created index.
- Querying for Similar Context:
- Generating Query Embedding: When you have a new query (or a document for which you want to find similar content), you first convert it into its corresponding embedding using the same NLP model you used earlier.
- Cosine Similarity Search: Pinecone allows for similarity searches based on several metrics. Cosine similarity is a popular choice for textual embeddings. By querying Pinecone with the generated embedding and specifying cosine similarity as the metric, you’ll retrieve the most similar document embeddings stored in the Pinecone index.
- Interpreting Results: The returned results will include identifiers for the matched documents and their similarity scores. You can use this information to fetch the actual content from your original document store or display relevant excerpts to the user.
Recommended Model for Embedding Data for RAG
Many times, it is asked as to what model can be used to embed the data for RAG. When it comes to embedding data for RAG, Sentence BERT (sBERT) is often recommended for almost all applications. In a RAG setup, sBERT can be used to embed both the query (from the user or the language model) and the documents in the external knowledge source. The embeddings help in efficiently retrieving the most relevant documents or pieces of information from a large corpus, which the language model can then use to generate more informed and accurate responses.
Sentence BERT (sBERT) takes a pre-trained BERT encoder model and further trains it to produce semantically meaningful embeddings. To do this, we can use a siamese/triplet network structure, where we separately embed two (or three) pieces of text with BERT, producing an embedding for each piece of text. Then, given pairs (or triplets) of text that are either similar or not similar, we can train sBERT to accurately predict textual similarity from these embeddings using an added regression or classification head. This approach is cheap/efficient, drastically improves the semantic meaningfulness of BERT embeddings, and produces a high-performing (BERT-based) bi-encoder that we can use for vector search.
A variety of open-source sBERT models are available via the Sentence Transformers library. To use these models for RAG, we simply need to split our documents into chunks, embed each chunk with sBERT, and then index all of these chunks for search in a vector database. From here, we can perform an efficient vector search (ideally, a hybrid search that also includes lexical components) over these chunks to retrieve relevant data at inference time for RAG.
Conclusion
The fusion of Retrieval Augmented Generation (RAG) with Large Language Models (LLMs) is a testament to the evolving landscape of machine learning. As we’ve explored, this synergy not only amplifies the capabilities of LLMs but also ensures that the responses generated are both contextually relevant and informed by the most current information available. By leveraging advanced embedding models and efficient search algorithms, businesses and researchers can unlock a new realm of possibilities, making AI-driven solutions more precise and insightful than ever before. Are you inspired to integrate the RAG LLM approach into your generative AI solutions? If you’ve already begun experimenting with this method, I’d love to hear about your experiences and insights.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me