Pre-trained models have revolutionized the field of natural language processing (NLP), enabling the development of advanced language understanding and generation systems. Hugging Face, a prominent organization in the NLP community, provides the “transformers” library—a powerful toolkit for working with pre-trained models. In this blog post, we’ll explore a “Hello World” example using Hugging Face’s Python library, uncovering the capabilities of pre-trained models in NLP tasks.
With Hugging Face’s transformers library, we can leverage the state-of-the-art machine learning models, tokenization tools, and training pipelines for different NLP use cases. We’ll discuss the importance of pre-trained models in NLP, provide an overview of Hugging Face’s offerings, and guide you through an example that demonstrates the simplicity and impact of leveraging pre-trained models. By the end, you’ll have a solid foundation to embark on your own NLP projects using Hugging Face’s transformative tools.
Overview of Hugging Face & Transformers Library
Applying a novel machine learning model to a new task is intricate, encompassing various steps including:
- Implementation of Model Architecture: Typically using frameworks like PyTorch or TensorFlow.
- Loading Pretrained Weights: If available, these can be loaded from a server.
- Processing Inputs and Outputs: This involves preprocessing the inputs, running them through the model, and applying task-specific postprocessing.
- Training Components: Implementation of dataloaders, loss functions, and optimizers for training.
These steps often require custom logic and can be time-consuming to adapt to new use cases. This is where Hugging Face Transformer libraries come to rescue!
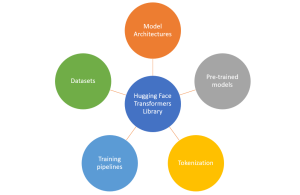
Hugging Face provides several powerful libraries and tools for natural language processing (NLP) tasks, including model architectures, pre-trained models, tokenization, training pipelines, etc.
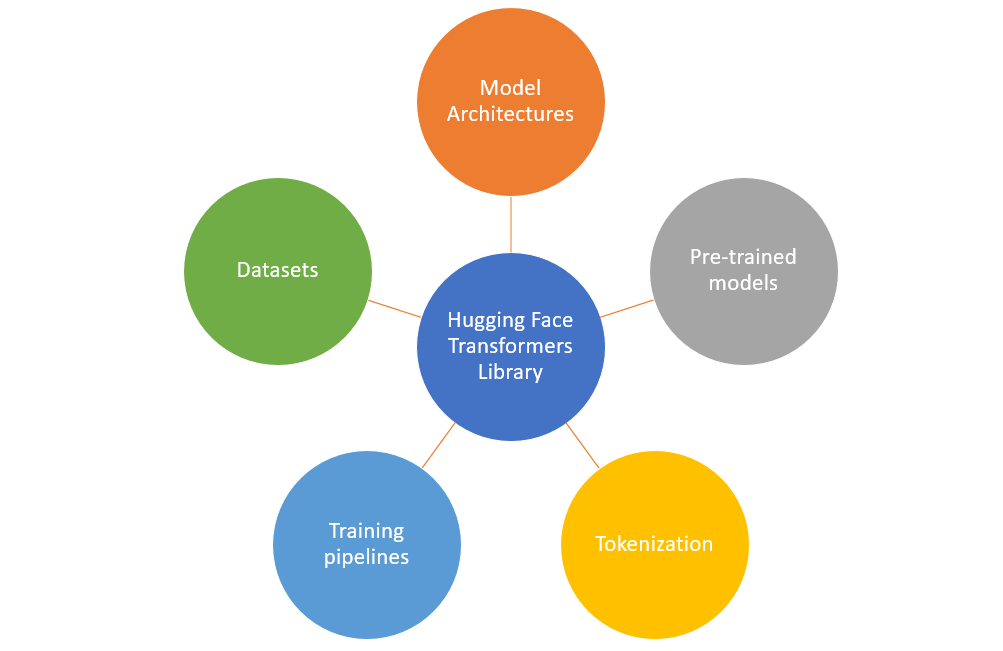
Here is a brief on each one of them:
- Model Architectures: Hugging Face offers a wide range of pre-trained models for various NLP tasks, such as text classification, named entity recognition, question answering, and more. We can choose a specific architecture (e.g., BERT, GPT, RoBERTa) and load a pre-trained model using the AutoModel class.
- Tokenization: The transformers library provides tools for tokenizing text into input representations suitable for specific models. The AutoTokenizer class can be used to automatically select and load the appropriate tokenizer for a given pre-trained model.
- Training Pipelines: Hugging Face simplifies the training process with their Trainer class , which abstracts away much of the training loop and provides easy-to-use interfaces for fine-tuning pre-trained models on your specific task. The training pipeline can be configured by specifying the model, data, optimization settings, and evaluation metrics.
- Pre-Trained Models: Hugging Face offers a vast collection of pre-trained models that have been fine-tuned on large-scale datasets. These models can be loaded using the AutoModel class and used for various NLP tasks without requiring extensive training. The following are some of the examples of popular pre-trained models provided by Hugging face:
- BERT (Bidirectional Encoder Representations from Transformers)
- GPT-2 (Generative Pre-trained Transformer 2)
- RoBERTa (Robustly Optimized BERT Pretraining Approach)
- DistilBERT (Distilled BERT)
- T5 (Text-to-Text Transfer Transformer)
- ELECTRA (Efficiently Learning an Encoder that Classifies Token Replacements Accurately)
- XLNet (Generalized Autoregressive Pretraining for Language Understanding)
- Data sets: Hugging Face Datasets is a library and repository that offers a vast array of curated datasets for various NLP tasks. Whether you’re looking for text classification, question answering, sentiment analysis, or other NLP tasks, Hugging Face Datasets provides a valuable resource for finding and working with diverse and well-structured datasets.
Setting Up the Environment for Transformers
To get started with Hugging Face’s transformers library, it’s important to set up the environment properly. First & foremost, install the transformers library using pip by executing the following command. This will install the latest version of the library and its dependencies.
# Install the transformers library
#
pip install transformers
As a next step, import the necessary modules in your Python script or Jupyter notebook. Some of the key modules include AutoModel, AutoTokenizer, AutoModelForMaskedLM, etc. The following code represents the same:
# Import the modules
#
from transformers import AutoTokenizer, AutoModelForMaskedLM
Once the above is done, you are all set.
Transformers Hello World Example – Python Code
Now that the environment is set up, let’s dive into building a “Hello World” example using Hugging Face’s transformers library. In this example, we’ll focus on the BERT model, one of the most widely used pre-trained models for NLP tasks.
In the code below, sentiment analysis, a form of text classification is demonstrated.
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# Load the tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased")
# Define the input text
input_text = "I didn't like the movie. The performances were suboptimal!"
# Tokenize the input text
inputs = tokenizer(input_text, padding=True, truncation=True, return_tensors="pt")
# Perform the classification
outputs = model(**inputs)
predicted_label = outputs.logits.argmax().item()
# Get the predicted label name
label_list = ["Negative", "Positive"] # Example label names
predicted_label_name = label_list[predicted_label]
# Print the predicted label
print("Predicted label:", predicted_label_name)
Lets understand the above code based on the following:
- First and foremost, the necessary modules from the transformers library, including AutoTokenizer and AutoModelForSequenceClassification are imported. These modules are responsible for loading the tokenizer and pre-trained model, respectively.
- As a next step, the pre-trained tokenizer and model is loaded from the “bert-base-uncased” variant. The tokenizer converts raw text into tokens, and the model performs the sequence classification task. The “bert-base-uncased” tokenizer is designed for English text and is case-insensitive.
- Then, the input text is defined. This is the text we want to classify. In this case, it represents a negative sentiment towards a movie.
- The tokenizer is applied to the input text using the tokenizer() method. the desired preprocessing options, such as padding and truncation is specified. The tokenizer returns a dictionary-like object called inputs that contains the tokenized input.
- The tokenized input is fed into the model using the model() method. The model returns outputs containing the predicted logits, which represent the model’s confidence scores for each class. We then use the argmax() method to determine the index of the predicted label.
- A list of label names is defined to map the predicted label index to its corresponding name. In this example, the labels “Negative” and “Positive” is used.
- Finally, the predicted label is printed to the console. In this case, it will display the sentiment classification prediction (“Negative”) based on the input text – “I didn’t like the movie. The performances were suboptimal!”.
Conclusion
Hugging Face’s transformers library revolutionizes NLP by offering pre-trained models, tokenization tools, and training pipelines. With practical “Hello World” example, we showcased the library’s seamless integration and effectiveness in tasks like masked language modeling and text classification. By leveraging Hugging Face’s transformers library, developers and researchers can effortlessly incorporate powerful NLP capabilities into their projects. Get started today by exploring the official documentation, accessing the Model Hub, and diving into the vast collection of pre-trained models and resources. Whether you’re a developer, researcher, or NLP enthusiast, Hugging Face provides the tools you need to unlock new possibilities in language understanding and generation.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me