Author Archives: Ajitesh Kumar
K-Fold Cross Validation in Machine Learning – Python Example
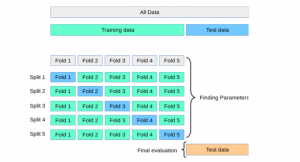
Last updated: 16th Aug, 2024 In this post, you will learn about K-fold Cross-Validation concepts used while training machine learning models with the help of Python code examples. K-fold cross-validation is a data splitting technique that is primarily used for assessing the model accuracy given smaller datasets. This technique can be implemented with k > 1 folds where k is equal number of data splits. K-Fold Cross Validation is also known as k-cross, k-fold cross-validation, k-fold CV, and k-folds. The k-fold cross-validation technique can be implemented easily using Python with scikit learn (Sklearn) package which provides an easy way to implement training of k-fold cross-validation models. It is important to learn the …
Gradient Boosting Machines (GBM): Concepts, Examples
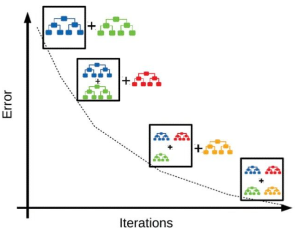
Last updated: 16th August, 2024 Gradient Boosting Machines (GBM) Algorithm is considered as one of the most powerful ensemble machine learning algorithms used for both regression and classification problems. This algorithm has been proven to increase the accuracy of predictions and is found to be extremely popular among data scientists. Let’s take a closer look at GBM and explore how it works with an example. What is a Gradient Boosting Machines Algorithm? Gradient boosting algorithm is an ensemble machine learning technique in which an ensemble of weak learners are created. In simpler words, the algorithm combines several smaller, simpler models in order to obtain a more accurate prediction than what …
Random Forest Classifier – Sklearn Python Example
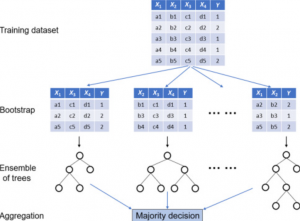
Last updated: 14th Aug, 2024 A random forest classifier is an ensemble machine learning model which is used for classification problems, and operates by constructing a multitude of decision trees during training, and, predicting the class label (of the data). In general, Random Forest is popular due to its high accuracy, robustness to overfitting, ability to handle large datasets with numerous features, and its effectiveness for both classification and regression tasks. Random Forest and Decision Tree classification algorithms are different, although Random Forest is built upon the concept of Decision Trees. In this post, you will learn about the concepts of random forest classifiers and how to train a Random …
Decision Tree Regression vs Linear Regression: Differences
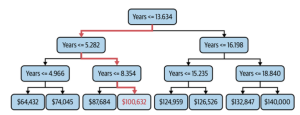
When it comes to building a regression model, one comes across the question such as whether to train the regression model using DecisionTree Regressor algorithm or linear regression algorithm? The following is the key differences you need to know in order to decide which algorithm is the most suitable one, and, why and when one can use one over the other? Linear vs Non-Linear Dataset: Which Algorithm to Use? Linear regression algorithm can be used when there exists linear relationship between the response and predictor variables in the given data set. For two or three dimensional datasets, it is as easy as draw scatter plot and find about the said …
Parametric vs Non-Parametric Models: Differences, Examples
Last updated: 11 Aug, 2024 When working with machine learning models, data scientists often come across a fundamental question: What sets parametric and non-parametric models apart? What are the key differences between these two different classes of models? What needs to be done when working on these models? This is also one of the most frequent questions asked in the interviews. Machine learning models can be parametric or non-parametric. Parametric models are those that require the specification of some parameters before they can be used to make predictions, while non-parametric models do not rely on any specific parameter settings and therefore often produce more accurate results. These two distinct approaches …
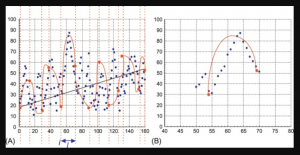
How to know if Linear Regression Model is Appropriate?
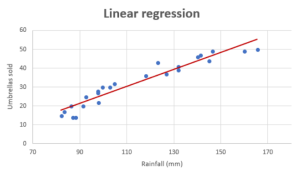
If you want to build a model for predicting a numerical value and wondering whether the linear regression model is most appropriate or valid, then creating the regression scatter plot is the most efficient way. And, this works best if the data set is two or three-dimensional. If a dataset is two-dimensional, it’s simple enough to plot the data to determine its shape. You can plot three-dimensional data too. The objective is to find whether the data set is relatively linear. When the plot is created, the data points fall roughly along a straight line as shown below. Whether Linear Regression Appropriate for High-dimension Datasets? The challenge comes when we …
Lasso Regression in Machine Learning: Python Example
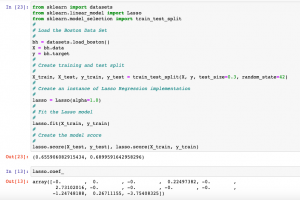
Last updated: 10th Aug, 2024 Lasso regression, sometimes referred to as L1 regularization, is a technique in linear regression that incorporates regularization to curb overfitting and enhance the performance of machine learning models. It works by adding a penalty term to the cost function that encourages the model to select only the most important features and set the coefficients of less important features to zero. This makes Lasso regression a popular method for feature selection and high-dimensional data analysis. In this post, you will learn concepts, formulas, advantages, and limitations of Lasso regression along with Python Sklearn examples. The other two similar forms of regularized linear regression are Ridge regression and …
Completion Model vs Chat Model: Python Examples

In this blog, we will learn about the concepts of completion and chat large language models (LLMs) with the help of Python examples. What’s the Completion Model in LLM? A completion model is a type of LLM that takes a text input and generates a text output, which is called a completion. In other words, a completion model is a type of LLM that generates text that continues from a given prompt or partial input. When provided with an initial piece of text, the model uses its trained knowledge to predict and generate the most likely subsequent text. A completion model can generate summaries, translations, stories, code, lyrics, etc depending on …
LLM Hosting Strategy, Options & Cost: Examples

As part of laying down application architecture for LLM applications, one key focus area is LLM deployments. Related to LLM deployment is laying down LLM hosting strategy as part of which different hosting options need to be looked at, and evaluated based on various criteria including cost and appropriate hosting should be selected. In this blog, we will learn about different hosting options for different kinds of LLM and related strategies. LLM Hosting Cost depends on the type of LLM Needed What is going to be the cost related to LLM hosting depends upon the type of LLM we need for our application. LLM Hosting Cost for Proprietary Models If …
Application Architecture for LLM Applications: Examples
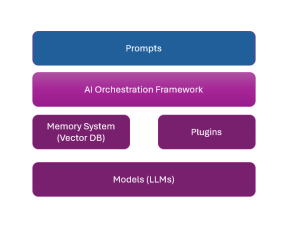
Large language models (LLMs), also termed large foundation models (LFMs), in recent times have been enabling the creation of innovative software products that are solving a wide range of problems that were unimaginable until recent times. Different stakeholders in the software engineering and AI arena need to learn about how to create such LLM-powered software applications. And, the most important aspect of creating such apps is the application architecture of such LLM applications. In this blog, we will learn about key application architecture components for LLM-based applications. This would be helpful for product managers, software architects, LLM architects, ML engineers, etc. LLMs in the software engineering landscape are also termed …
Python Pickle Security Issues / Risk

Suppose your machine learning model is serialized as a Python pickle file and later loaded for making predictions. In that case, you need to be aware of security risks/issues associated with loading the Python Pickle file. Security Issue related to Python Pickle The Python pickle module is a powerful tool for serializing and deserializing Python object structures. However, its very power is also what makes it a potential security risk. When data is “pickled,” it is converted into a byte stream that can be written to a file or transmitted over a network. “Unpickling” this data reconstructs the original object in memory. The danger lies in the fact that unpickling …
Pricing Analytics in Banking: Strategies, Examples
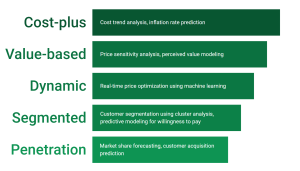
Last updated: 15th May, 2024 Have you ever wondered how your bank decides what to charge you for its services? Or, perhaps how do banks arrive at the pricing (fees, rates, and charges) associated with various banking products? If you’re a product manager, data analyst, or data scientist in the banking industry, you might be aware that these pricing decisions are far from arbitrary. Rather, these pricing decisions are made based on one or more frameworks while leveraging data analytics. They result from intricate pricing strategies, driven by an extensive array of data and sophisticated analytics. In this blog, we will learn about some popular pricing strategies banks execute to …
How to Learn Effectively: A Holistic Approach

In this fast-changing world, the ability to learn effectively is more valuable than ever. Whether you’re a student, a professional (data scientist, software engineer, or business analyst), or simply a curious individual, mastering the art of learning can open doors to new opportunities and deeper understanding. But how does one transcend from merely absorbing information to truly learning it? The key lies in a three-step process that can significantly enhance your learning efficiency and retention: Listening, Thinking, and Meditating on the topic. The three-step learning process—Listening, Thinking, and Meditating—parallels the ancient Vedantic practice of Shravana, Manana, and Nididhyasana. These are the three key pillars through which knowledge is traditionally acquired …
How to Choose Right Statistical Tests: Examples
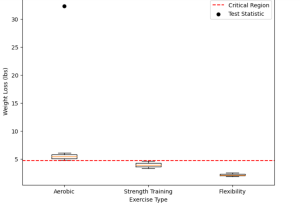
Last updated: 13th May, 2024 Whether you are a researcher, data analyst, or data scientist, selecting the appropriate statistical test is crucial for accurate and reliable hypothesis testing for validating any given claim. With numerous tests available, it can be overwhelming to determine the right statistical test for your research question and data type. In this blog, the aim is to simplify the process, providing you with a systematic approach to choosing the right statistical test. This blog will be particularly helpful for those new to statistical analysis and unsure which test to use for their specific needs. You will learn a clear and structured method for selecting the appropriate …
Data Lakehouses Fundamentals & Examples
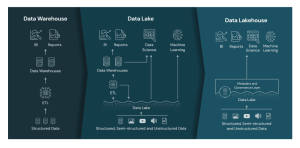
Last updated: 12th May, 2024 Data lakehouses are a relatively new concept in the data warehousing space. They combine the scalability and cost-effectiveness of cloud storage-based data lakes with the flexibility, security, and performance of traditional data warehouses to create a powerful data management solution. But what exactly is a data lakehouse, how does it work, and how might it be used in your organization? In this blog post, we’ll explore the basics of data lakehouses and provide real-world examples to illustrate their value. What is a Data Lakehouse? Simply speaking, data lakehouses combine elements from both data warehouses and data lakes — hence the name “data lakehouse” — to …
Machine Learning Lifecycle: Data to Deployment Example
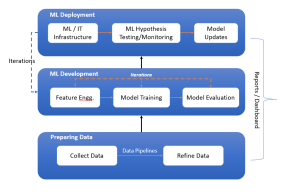
Last updated: 12th May 2024 In this blog, we get an overview of the machine learning lifecycle, from initial data handling to the deployment and iterative improvement of ML models. You might want to check out this book for greater insights into machine learning (ML) concepts – Machine Learning Interviews. The following is the diagram representing the machine learning lifecycle while showcasing three key stages such as preparing data, ML development, and ML deployment. These three stages are explained later in this blog. Stage A: Preparing Data Preparing data for training machine learning models involves collecting data, constructing data pipelines for preprocessing, and refining the data to prepare it for …

I found it very helpful. However the differences are not too understandable for me