Last updated: 12th May 2024
In this blog, we get an overview of the machine learning lifecycle, from initial data handling to the deployment and iterative improvement of ML models. You might want to check out this book for greater insights into machine learning (ML) concepts – Machine Learning Interviews.
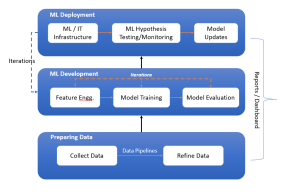
The following is the diagram representing the machine learning lifecycle while showcasing three key stages such as preparing data, ML development, and ML deployment. These three stages are explained later in this blog.
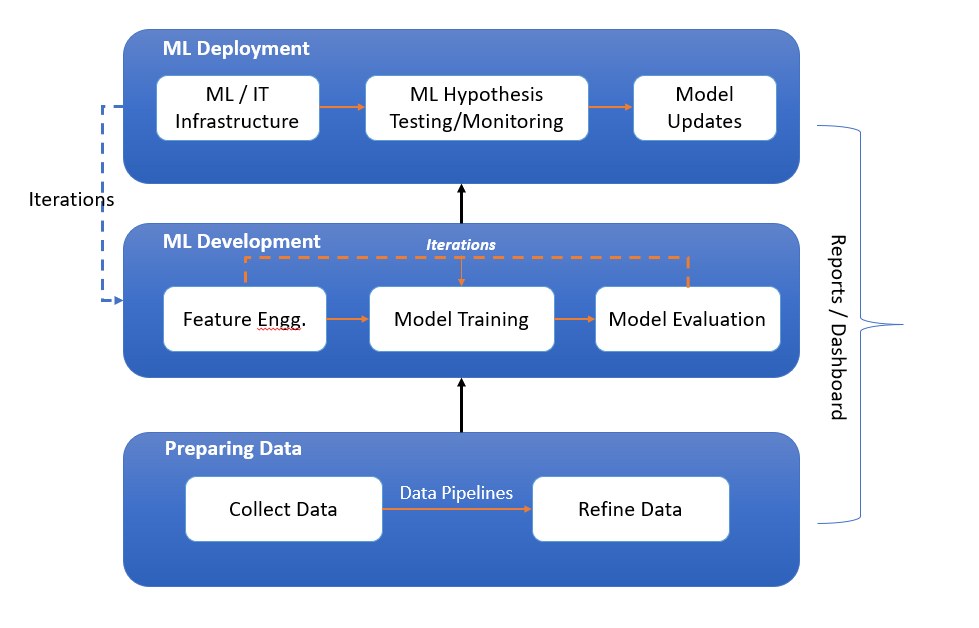
Stage A: Preparing Data
Preparing data for training machine learning models involves collecting data, constructing data pipelines for preprocessing, and refining the data to prepare it for feature engineering. This foundational stage ensures data quality and readiness for the subsequent development of machine learning models. The following are the three key phases:
Sourcing Data from Internal & External Data Sources
The genesis of any machine learning project is data. Source data is raw and unprocessed, often collected from various sensors, logs, transactions, or user activities. The data can be sourced from both the internal and external data sources. The quality and quantity of this data are foundational to the performance of the subsequent machine learning models. This stage involves ensuring that data collection methods are ethical, privacy-compliant, and robust against potential biases or errors.
Data Pipelines for Data Preprocessing / Transformation
To transform raw data into a format suitable for ML models, data pipelines are constructed. These pipelines are responsible for data cleaning, preprocessing, and transformation. They automate the flow of data and ensure that it is consistently formatted and ready for the next stage. This process often involves handling missing values, encoding categorical variables, and normalizing or standardizing numerical values.
Refining Data for Feature Engineering
Once the data has passed through the pipelines, it emerges as refined data, ready for feature engineering. This refinement process is about enhancing data quality and relevance to ensure the ML algorithms can effectively learn from it.
Stage B: Machine Learning Development
Machine Learning Development is an iterative process that revolves around crafting relevant features through feature engineering, selecting and training models using various ML algorithms, and rigorously evaluating model performance. This cyclical phase emphasizes refinement and optimization, with data scientists repeatedly tuning models and features to enhance accuracy and predictive power before moving toward deployment.
Feature Engineering
The first step in ML development is feature engineering, where data scientists create features that make machine learning algorithms work effectively. This process involves selecting the most relevant attributes or constructing new attributes from the raw data to help the algorithms better understand the patterns within.
ML Model Training
With the right features in hand, the focus shifts to selecting suitable ML algorithms and training models. This step involves experimenting with various algorithms, tuning hyperparameters, and using training data to fit the model. The choice of algorithms depends on the nature of the problem—classification, regression, clustering, etc.—and the characteristics of the data.
ML Model Evaluation
After a model is trained, it must be evaluated to ensure it performs well on unseen data. This is done through various metrics like accuracy, precision, recall, F1 score for classification problems, or mean squared error for regression problems. Cross-validation techniques are also employed to assess the model’s robustness.
Stage C: Machine Learning Deployment
Machine learning deployment marks the transition of models from development to production. It necessitates a robust IT infrastructure to support the model’s integration into real-world applications. This stage is characterized by continuous hypothesis testing and monitoring to validate model predictions and ensure consistent performance. An iterative loop of model updates is crucial to adapt to new data and maintain accuracy, with the process underpinned by constant evaluation through reports and dashboards that inform necessary adjustments and improvements to the deployed machine learning solutions.
Machine Learning / Software Infrastructure
Before deploying a model, the ML/software IT infrastructure needs to be in place. This infrastructure supports the model in a production environment, handling aspects such as scalability, security, and data flow. It ensures that the model can be accessed by end-users or applications and can operate within the existing tech stack of the organization.
ML Hypothesis Testing/Monitoring
Deployed models are continually monitored to ensure they perform as expected. This involves setting up hypothesis tests to understand the impact of the model and monitoring its predictions for any drift or performance issues. Regular checks help identify when a model may need retraining or refinement.
Model Updates
As data evolves, models may become outdated. Hence, there is a need for ongoing model updates. This iterative process requires monitoring performance, retraining models with new data, and deploying updates without disrupting the service. It’s an essential part of the lifecycle to maintain the relevancy and accuracy of ML solutions.
Throughout the machine learning lifecycle, reporting tools and dashboards provide visibility into the model’s performance, data quality, and impact on business outcomes. These tools are used to communicate with stakeholders and to make data-driven decisions about future iterations of the model.
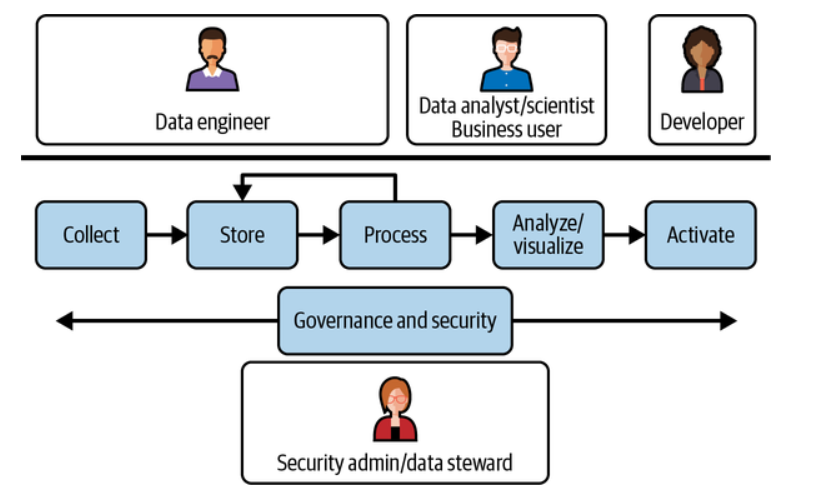
Machine Learning Lifecycle vs Teams Involved
Here is the representation of different teams involved in the machine learning lifecycle. Learn more in this book: Architecting Data & Machine Learning Platforms. You may note the involvement of data engineers, data analysts, data scientists, business analysts and software developers in creating a machine learning-based application.
Conclusion
The machine learning lifecycle is iterative and cyclical. It does not end with the deployment of a model but rather loops back to the development phase, fueled by new data and insights gained from model monitoring and reporting. This continuous loop ensures that ML solutions evolve and adapt to changing data landscapes and business requirements.
Navigating this lifecycle requires a blend of domain expertise, data science proficiency, and operational savvy. By understanding each stage and its milestones—as we have explored in this blog—teams can effectively move from raw data to deployment and beyond, creating ML systems that are not just intelligent but also impactful and enduring.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me