Author Archives: Ajitesh Kumar
Large Language Models (LLMs): Types, Examples
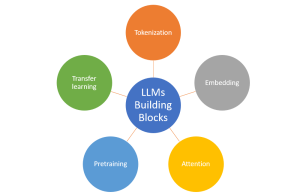
Last updated: 31st Jan, 2024 Large language models (LLMs), being the key pillar of generative AI, have been gaining traction in the world of natural language processing (NLP) due to their ability to process massive amounts of text and generate accurate results related to predicting the next word in a sentence, given all the previous words. These different LLM models are trained on a large or broad corpus of text datasets, which contain hundreds of millions to billions of words. LLMs, as they are known, rely on complex algorithms including transformer architectures that shift through large datasets and recognize patterns at the word level. This data helps the LLMs better understand …
Amazon (AWS) Machine Learning / AI Services List

Last updated: 30th Jan, 2024 Amazon Web Services (AWS) is a cloud computing platform that offers machine learning as one of its many services. AWS has been around for over 10 years and has helped data scientists leverage the Amazon AWS cloud to train machine learning models. AWS provides an easy-to-use interface that helps data scientists build, test, and deploy their machine learning models with ease. AWS also provides access to pre-trained machine learning models so you can start building your model without having to spend time training it first! You can get greater details on AWS machine learning services, data science use cases, and other aspects in this book – …
Problem, Symptoms & Root Cause Analysis (RCA) Examples
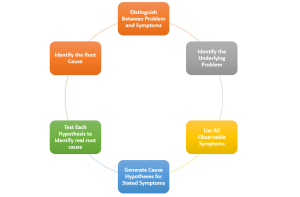
Last updated: 30th Jan, 2024 Have you found yourself stuck in a cycle of solving the same or similar problems over and over again? Ever wondered why some solutions seem to only offer a temporary fix? Have you wondered if you have identified the correct problem or if you are trying to fix one of the symptoms? The key lies in your understanding of how we define problem statements, associated symptoms, root causes, and approach to problem-solving, which is fundamentally rooted in analytical thinking and critical thinking. What exactly is the difference between a problem and its symptoms? And why is it crucial to conduct a root cause analysis to …
LLM Optimization for Inference – Techniques, Examples
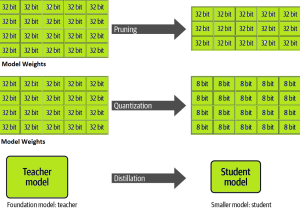
One of the common challenges faced with the deployment of large language models (LLMs) while achieving low-latency completions (inferences) is the size of the LLMs. The size of LLM throws challenges in terms of compute, storage, and memory requirements. And, the solution to this is to optimize the LLM deployment by taking advantage of model compression techniques that aim to reduce the size of the model. In this blog, we will look into three different optimization techniques namely pruning, quantization, and distillation along with their examples. These techniques help model load quickly while enabling reduced latency during LLM inference. They reduce the resource requirements for the compute, storage, and memory. …
How is ChatGPT Trained to Generate Desired Responses?
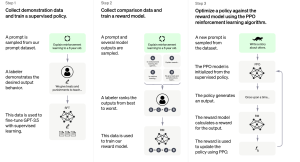
Last updated: 27th Jan, 2024 Training an AI / Machine Learning model as sophisticated as the one used by ChatGPT involves a multi-step process that fine-tunes its ability to understand and generate human-like text. Let’s break down the ChatGPT training process into three primary steps. Note that OpenAI has not published any specific paper on this. However, the reference has been provided on this page – Introducing ChatGPT. Fine-tuning Base Model with Supervised Learning The first phase starts with collecting demonstration data. Here, prompts are taken from a dataset, and human labelers provide the desired output behavior, which essentially sets the standard for the AI’s responses. For example, if the …
AI-Ready Data Explained with Examples

AI-ready data usually refers to data that has been prepared in such a way that it can be effectively used for training artificial intelligence (AI) and generative AI models. In this blog, we will learn about what are the most common attributes of AI-ready data. The following are the top most 5 attributes that AI-ready data would need to have. Data must be: Check out this Gartner paper for further details – We Shape AI, AI shapes us.
First Principles Thinking Explained with Examples

Last updated: 23rd Jan, 2024 Can innovation be taught and learned methodically? Can there be an innovation playbook using which, given a need to create a thing, product, or solve a complex problem, a set of well-defined steps be followed? How has Elon Musk been super successful time and again in creating game-changing innovative products that created tremendous value for end-users and society at large? The answers to these questions can be found with a reasoning technique called first principles thinking. The first principles thinking is often associated with Elon Musk, who uses this approach to come up with his business ideas, create innovative product designs, and build winning products …
Transfer Learning vs Fine Tuning LLMs: Differences
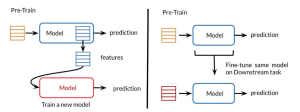
Last updated: 23rd Jan, 2024 Two NLP concepts that are fundamental to large language models (LLMs) are transfer learning and fine-tuning pre-trained LLMs. Rather, true fine-tuning can also be termed as full fine-tuning because transfer learning is also a form of fine-tuning. Despite their interconnected nature, they are distinct methodologies that serve unique purposes when training foundation LLMs to achieve different objectives. In this blog, we will explore the differences between transfer Learning and full fine-tuning, learning about their characteristics and how they come into play in real-world scenarios related to natural language understanding (NLU) and natural language generation (NLG) tasks with the help of examples. We will also learn …
AI-assisted Software Development: Tools & Processes

In the rapidly evolving landscape of software development, the integration of artificial intelligence (AI) and generative AI (Gen AI) is not just a luxury but a cornerstone for enhancing software development velocity. This blog delves into the key aspects of Gen AI and AI-assisted software development, presenting actionable takeaways for software leaders, including engineering managers, project managers, product managers, and software engineers. We will look into different tools and related processes that can be enhanced across the entire software development lifecycle. Design & Architect: Crafting the Blueprint Integrate the following tools to speed up the design process while ensuring adherence to best practices, significantly reducing design iteration times. Code & …
Generalization Errors in Machine Learning: Python Examples
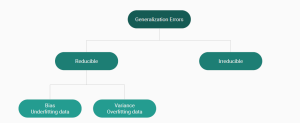
Last updated: 21st Jan, 2024 Machine Learning (ML) models are designed to make predictions or decisions based on data. However, a common challenge, data scientists face when developing these models is ensuring that they generalize well to new, unseen data. Generalization refers to a model’s ability to perform accurately on new, unseen examples after being trained on a limited set of data. When models don’t generalize well, they commit errors. These errors are called generalization errors. In this blog, you will learn about different types of generalization errors, with examples, and walk through a simple Python demonstration to illustrate these concepts. Types of Generalization Errors Generalization errors in machine learning …
Transformer Architecture in Deep Learning: Examples
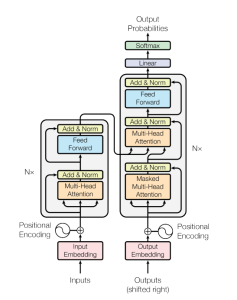
The Transformer model architecture, introduced by Vaswani et al. in 2017, is a deep learning model that has revolutionized the field of natural language processing (NLP) giving rise to large language models (LLMs) such as BERT, GPT, T5, etc. In this blog, we will learn about the details of transformer model architecture with the help of examples and references from the mother paper – Attention is All You Need. Transformer Block – Core Building Block of Transformer Model Architecture Before getting to understand the details of transformer model architecture, let’s understand the key building block termed transformer block. The core building block of the Transformer architecture consists of multi-head attention …
LLM Training & GPU Memory Requirements: Examples
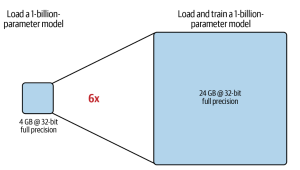
As data scientists and MLOps Engineers, you must have come across the challenges related to managing GPU requirements for training and deploying large language models (LLMs). In this blog, we will delve deep into the intricacies of GPU memory demands when dealing with LLMs. We’ll learn with the help of various examples to better understand how GPU memory impacts the performance and feasibility of training these LLMs. Whether you’re planning to train a foundation (pre-trained) model or fine-tuning an existing model, the insights are aimed to guide you through the crucial considerations of GPU memory allocation. Greater details can be found in this book: Generative AI on AWS. Understanding GPU …
Instruction Fine-tuning LLM Explained with Examples

A pre-trained or foundation model is further trained (or fine-tuned) with instructions datasets to help them learn about your specific data and perform humanlike tasks. These models are called instruction fine-tuning LLMs. In this blog, we will learn about the concepts and different examples of instruction fine-tuning models. You might want to check out this book to learn more: Generative AI on AWS. What are Instruction fine-tuning LLMs? Instruction fine-tuning LLMs, also called chat or instruct models, are created by training pre-trained models with different types of instructions. Instruction fine-tuning can be defined as a type of supervised machine learning that improves the foundation model by continuously comparing the model’s …
Distributed LLM Training & DDP, FSDP Patterns: Examples

Training large language models (LLMs) like GPT-4 requires the use of distributed computing patterns as there is a need to work with vast amounts of data while training with LLMs having multi-billion parameters vis-a-vis limited GPU support (NVIDIA A100 with 80 GB currently) for LLM training. In this blog, we will delve deep into some of the most important distributed LLM training patterns such as distributed data parallel (DDP) and Fully sharded data parallel (FSDP). The primary difference between these patterns is based on how the model is split or sharded across GPUs in the system. You might want to check out greater details in this book: Generative AI on …
Transformer Architecture Types: Explained with Examples
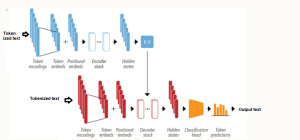
Are you fascinated by the power of deep learning large language models that can generate creative writing, answer complex questions, etc? Ever wondered how these LLMs understand and process human language with such finesse? At the heart of these remarkable achievements lies a machine learning model architecture that has revolutionized the field of Natural Language Processing (NLP) – the Transformer architecture and its types. But what makes Transformer models so special? From encoding sentences into numerical embeddings to employing attention mechanisms that capture the relationships between words, we will dissect different types of Transformer architectures, provide real-world examples, and even dive into the mathematics that governs its operation. Let’s explore …
Blueprint: Deploying Generative AI Applications
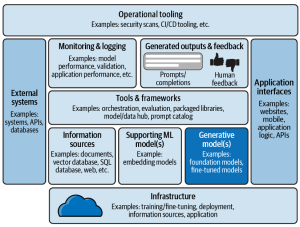
In this blog, we will learn about a comprehensive framework for the deployment of generative AI applications, breaking down the essential components that architects must consider. Learn more about this topic from this book: Generative AI on AWS. The following is a solution / technology architecture that represents a blueprint for deploying generative AI applications. The following is an explanation of the different components of this architectural viewpoint:
I found it very helpful. However the differences are not too understandable for me