Tag Archives: python
Learning Curves Python Sklearn Example
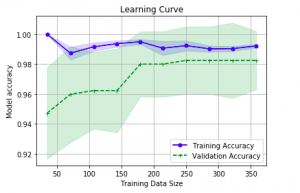
Last updated: 26th Nov, 2023 In this post, you will learn about how to use learning curves to assess the improvement in learning performance (accuracy, error rate, etc.) of a machine learning model while implementing using Python (Sklearn) packages. Knowing how to use learning curves will help you assess/diagnose whether the model is suffering from high bias (underfitting) or high variance (overfitting) and whether increasing training data samples could help solve the bias or variance problem. You may want to check some of the following posts in order to get a better understanding of bias-variance and underfitting-overfitting. Bias-variance concepts and interview questions Overfitting/Underfitting concepts and interview questions What are learning curves? …
XGBoost Classifier Explained with Python Example
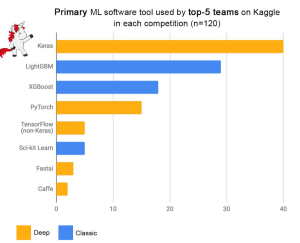
Among the myriad of machine learning algorithms and techniques available with data scientists, one stands out for its exceptional performance in classification problems: XGBoost, short for eXtreme Gradient Boosting. This algorithm has established itself as a force to reckon with in the data science community, as evidenced by its frequent use and high placements in Kaggle competitions, a platform where data scientists and machine learning practitioners worldwide compete to solve complex data problems. The following plot is taken from Francois Chollet tweet. Above demonstrates the prominence of XGBoost as one of the primary machine learning software tools used by the top-5 teams across 120 Kaggle competitions. The data points in …
Bagging Classifier Python Code Example
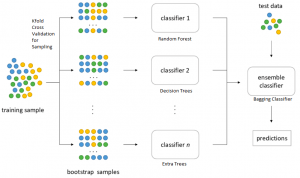
Last updated: 25th Nov, 2023 Bagging is a type of an ensemble machine learning approach that combines the outputs from many learner to improve performance. The bagging algorithm works by dividing the training set into smaller subsets. These subsets are then processed through different machine-learning models. After processing, the predictions from each model are combined. This combination of predictions is used to generate an overall prediction for each instance in the original data. In this blog post, you will learn about the concept of Bagging along with Bagging Classifier Python code example. Bagging can be used in machine learning for both classification and regression problem. The bagging classifier technique is utilized across a …
PCA Explained Variance Concepts with Python Example
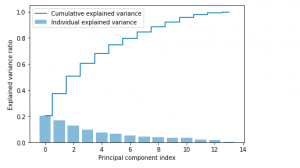
Last updated: 24th Nov, 2023 Dimensionality reduction is an important technique in data analysis and machine learning that allows us to reduce the number of variables in a dataset while retaining the most important information. By reducing the number of variables, we can simplify the problem, improve computational efficiency, and avoid overfitting. Principal Component Analysis (PCA) is a popular dimensionality reduction technique that aims to transform a high-dimensional dataset into a lower-dimensional space while retaining most of the information. PCA works by identifying the directions that capture the most variation in the data and projecting the data onto those directions, which are called principal components. However, when we apply PCA, …
Feature Scaling in Machine Learning: Python Examples

While training machine learning models, we come across the need for scaling features in order to have different features contribute to the predictions in an appropriate manner. Without scaling, features with larger numerical ranges can dominate those with smaller ranges, leading to biased or inefficient learning. In this post you will learn about this feature engineering technique namely feature scaling with Python code examples using which you could significantly improve performance of machine learning models. To demonstrate the technique, the models will be trained using Perceptron (single-layer neural network) classifier. What is Feature Scaling? Why is it needed? Feature scaling is a method used to standardize the range of independent variables …
PCA vs LDA Differences, Plots, Examples
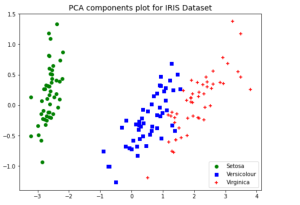
Last updated: 18th Nov, 2023 Dimensionality reduction is an important technique in data analysis and machine learning that allows us to reduce the number of variables in a dataset while retaining the most important information. By reducing the number of variables, we can simplify the problem, improve computational efficiency, and avoid overfitting. Two popular dimensionality reduction techniques are Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA). Both techniques aim to reduce the dimensionality of the dataset, but they differ in their objectives, assumptions, and outputs. But how do they differ, and when should you use one method over the other? As data scientists, it is important to get a …
Confusion Matrix Concepts, Python Code Examples
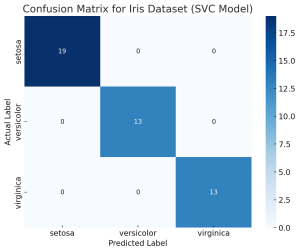
The confusion matrix is an essential tool in the field of machine learning and statistics for evaluating the performance of a classification model. It’s particularly useful when dealing with binary or multi-class classification problems. In this post, you will learn about the confusion matrix with examples and how it could be used as performance metrics for classification models in machine learning. What is Confusion Matrix? A confusion matrix is a table used to describe the performance of a classification model on a set of test data for which the true values are known. It’s most useful when you need to know more about the accuracy of the model than just …
Wilcoxon Signed Rank Test: Concepts, Examples
How can data scientists accurately analyze data when faced with non-normal distributions or small sample sizes? This is a challenge that often arises in the dynamic field of data science, where making precise inferences is crucial. Enter the Wilcoxon Signed Rank Test—a non-parametric statistical method that stands as a powerful alternative to the traditional t-test. This blog post aims to unravel the concepts and practical applications of the Wilcoxon Signed Rank Test, offering key insights for data scientists and researchers navigating complex data landscapes. The beauty of the Wilcoxon Signed Rank Test lies in its wide applicability across numerous fields. From healthcare, where it can compare the efficacy of different …
Hierarchical Clustering: Concepts, Python Example
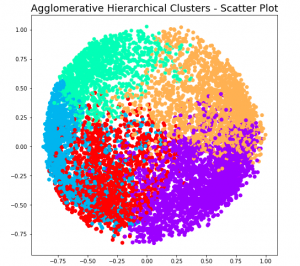
Hierarchical clustering a type of unsupervised machine learning algorithm that stands out for its unique approach to grouping data points. Unlike its counterparts, such as k-means, it doesn’t require the predetermined number of clusters. This feature alone makes it an invaluable method for exploratory data analysis, where the true nature of data is often hidden and waiting to be discovered. But the capabilities of hierarchical clustering go far beyond just flexibility. It builds a tree-like structure, a dendrogram, offering insights into the data’s relationships and similarities, which is more than just clustering—it’s about understanding the story your data wants to tell. In this blog, we’ll explore the key features that …
AIC & BIC for Selecting Regression Models: Formula, Examples
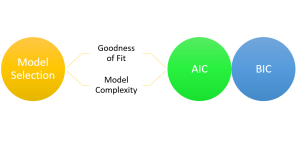
Are you grappling with the complexities of choosing the right regression model for your data? You are not alone. When working with regression models, selecting the most appropriate machine learning model is a critical step toward understanding the relationships between variables and making accurate predictions. With numerous regression models available, it becomes essential to employ robust criteria for model selection. This is where the two most widely used criteria come to the rescue. They are the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC). In this blog, we will learn about the concepts of AIC, BIC and how they can be used to select the most appropriate machine …
Problems with Categorical Variables: Examples
Have you ever encountered unfamiliar words while learning a new language and didn’t know their meanings? Or tried to fit all your belongings into a suitcase, only to realize it’s too full? Or started reading a book series from the third book and felt lost? These scenarios in our daily lives surprisingly resemble some challenges we face with categorical variables in machine learning. Categorical variables, while essential in many datasets, bring with them a unique set of challenges. In this article, we’ll be discussing three major problems associated with categorical features: Let’s explore each with real-life examples and supporting Python code snippets. Incomplete Vocabulary The “Incomplete Vocabulary” problem arises when …
Data Analytics for Car Dealers: Actionable Insights
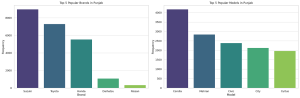
Are you starting a car dealership and wondering how to leverage data to make informed business decisions? In today’s data-driven world, analytics can be the difference between a thriving business and a failing one. This blog aims to provide actionable insights for car dealers, especially those starting new car dealer business, to excel in various business aspects. I will cover inventory management, pricing strategy, marketing and sales, customer service, and risk mitigation, all backed by data analytics. I will continue to update this blog with more methods in time to come. The data used for analysis can be found on the Kaggle.com – Ultimate Car Price Prediction Dataset. First and …
Find Topics of Text Clustering: Python Examples
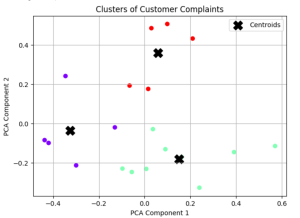
Have you ever clustered a collection of texts and wondered what predominant topics underlie each group? How can you pinpoint the essence of each cluster comprising of large volume of words? Is there a way to succinctly represent the core topic of each cluster using Python? Text clustering is a powerful technique in natural language processing (NLP) that groups documents into clusters based on their content. Once you’ve clustered your data, a natural follow-up question arises: “What are these clusters about?” In this article, we’ll discuss two different methods to find the dominant topics of text clusters using Python. Meanwhile, check out my post on text clustering – Text Clustering …
OpenAI Python API Example for NLP Tasks

Ever wondered how you can leverage the power of OpenAI’s GPT-3 and GPT-3.5 (from Jan 2024 onwards) directly in your Python application? Are you curious about generating human-like text with just a few lines of code? This blog post will walk you through an example Python code snippet that utilizes OpenAI’s Python API for different NLP tasks such as text generation. Check out my other post on how to use Langchain framework for text generation using OpenAI GPT models. OpenAI Python APIs The OpenAI Python API is an interface that allows you to interact with OpenAI’s language models, including their GPT-3 model. The following are different popular models that you …
LLM Chain OpenAI Python Example
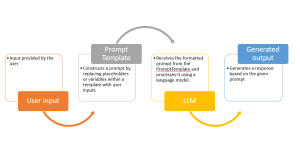
Have you ever wondered how to fully utilize large language models (LLMs) in our natural language processing (NLP) applications, like we do with ChatGPT? Would you not want to create an application such as ChatGPT where you write some prompt and it gives you back output such as text generation or summarization. While learning to make a direct API call to an OpenAI LLMs is a great start, we can build full fledged applications serving our end user needs. And, building prompts that adapt to user input dynamically is one of the most important aspect of an LLM app. That’s where LangChain, a powerful framework, comes in. In this blog, …
Langchain ChatGPT Hello World Python Example
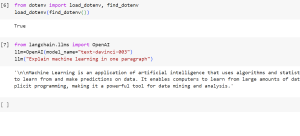
Have you ever wondered how to build applications that not only utilize large language models (LLMs) but are also capable of interacting with their environment and connecting to other data sources. If so, then LangChain is the answer! In this blog, we will learn about what is LangChain, what are its key aspects, how does it work. We will also quickly review the concepts of prompt, tokens and temperature when using the OpenAI API. We will the learn about creating a ‘Hello World’ Python program using LangChain and OpenAI’s Large Language Models (LLMs) such as GPT-3 models. What is LangChain Framework? LangChain is a dynamic framework specifically designed for the …
I found it very helpful. However the differences are not too understandable for me