Have you ever clustered a collection of texts and wondered what predominant topics underlie each group? How can you pinpoint the essence of each cluster comprising of large volume of words? Is there a way to succinctly represent the core topic of each cluster using Python? Text clustering is a powerful technique in natural language processing (NLP) that groups documents into clusters based on their content. Once you’ve clustered your data, a natural follow-up question arises: “What are these clusters about?” In this article, we’ll discuss two different methods to find the dominant topics of text clusters using Python. Meanwhile, check out my post on text clustering – Text Clustering Python Examples – Steps, Algorithms.
We will look into the following two techniques for finding the topics of the text clusters:
- Finding topics using text aggregation and keywords extraction
- Finding topics by summing TF-IDF Scores by clusters
Creating Text Clusters using K-Means
Before getting into techniques for finding the topics, lets create text clusters for a bunch of documents (customer_complaints_1.csv) using K-Means Algorithm
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import PCA
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# Load the data again (Google Collab)
df = pd.read_csv('/content/customer_complaints_1.csv')
# Create TF-IDF embeddings
tfidf_vectorizer = TfidfVectorizer(max_df=0.85, max_features=1000, stop_words='english')
tfidf_matrix = tfidf_vectorizer.fit_transform(df['text'])
# Reduce dimensionality using PCA
pca = PCA(n_components=2)
reduced_tfidf = pca.fit_transform(tfidf_matrix.toarray())
# Cluster using KMeans with 3 clusters (as determined previously)
kmeans = KMeans(n_clusters=3, random_state=42)
clusters = kmeans.fit_predict(reduced_tfidf)
# Plot the clusters
plt.figure(figsize=(10, 6))
plt.scatter(reduced_tfidf[:, 0], reduced_tfidf[:, 1], c=clusters, cmap='rainbow')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=200, c='black', marker='X', label='Centroids')
plt.xlabel('PCA Component 1')
plt.ylabel('PCA Component 2')
plt.title('Clusters of Customer Complaints')
plt.legend()
plt.grid(True)
plt.show()
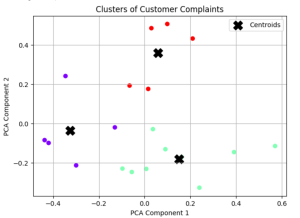
The above code will cluster the text (19 rows in the file) in three different clusters as shown below. You can find the code related to Elbow method in this blog – Text Clustering Python Examples to arrive at K = 3.
Now that we have created text clusters, lets find the topics for these clusters.
Finding Topics using Text Aggregation & Keywords Extraction: Python Example
One of the simplest and most intuitive ways to find out the dominant topic of a text cluster is to aggregate all the texts within the cluster and then extract the most frequent terms or keywords. Here are the steps:
- Text Aggregation: Combine or concatenate all the texts (in our case, customer complaints) within each cluster into a single text.
- Keyword Extraction: From this aggregated text, identify and extract the most frequent terms or keywords. Tools like the Python Counter class or TF-IDF vectorization can assist in this.
- Output: List the top terms for each cluster. These terms give an insight into the main themes or topics of that cluster.
Here is the Python Code for finding topics using text aggregation and keywords extraction.
from collections import Counter
import re
def extract_keywords(text, num_keywords=5):
"""Extract the most frequent keywords from a given text."""
# Tokenize the text into words and filter out short and non-alphabetic tokens
words = [word for word in re.findall(r'\w+', text.lower()) if len(word) > 2 and word.isalpha()]
# Count the frequency of each word
word_freq = Counter(words)
# Return the most common words as keywords
return [word for word, freq in word_freq.most_common(num_keywords)]
# Aggregate texts for each cluster
cluster_texts = df.groupby(clusters)['text'].apply(' '.join)
# Extract top keywords for each cluster
cluster_keywords = cluster_texts.apply(extract_keywords)
cluster_keywords
The following will get printed:
0 [the, and, out, internet, that]
1 [the, and, for, they, contract]
2 [the, you, service, and, they]
Name: text, dtype: object
Based on the above keywords, we can arrive at the following topics:
- Cluster 0:
- Keywords: service, customer
- Possible topic: Customer service issues
- Cluster 1:
- Keywords: contract
- Possible topic: Contract-related complaints
- Cluster 2:
- Keywords: internet, out
- Possible topic: Internet outage or connectivity issues
Finding Topics by Summing TF-IDF Scores by Clusters: Python Example
Another more sophisticated approach involves using the Term Frequency-Inverse Document Frequency (TF-IDF) statistic, a popular technique in information retrieval. The idea here is to quantify the importance of each term not just within a document, but across the entire corpus. Here are the steps:
- Create TF-IDF Matrix: For your collection of texts, compute the TF-IDF scores for every term in each document, resulting in a matrix where rows are documents and columns are terms.
- Split by Cluster: Filter this matrix to focus on the rows/documents that belong to a particular cluster.
- Sum TF-IDF Scores: For each term, sum its TF-IDF scores across all documents in the cluster. This aggregate score indicates the term’s overall importance or significance within the cluster.
- Output: List the terms with the highest aggregate scores. These are the terms most representative of each cluster’s content.
Here is the Python code that can be used to implement the above:
def get_top_terms_by_summing_tfidf(cluster_id, matrix, vectorizer, n_terms=5):
"""Get the top terms for a given cluster by summing the TF-IDF scores."""
# Filter the matrix to only include documents from the given cluster
cluster_matrix = matrix[clusters == cluster_id]
# Sum the TF-IDF scores
summed_tfidf = cluster_matrix.sum(axis=0)
# Convert to numpy array for easier indexing
summed_tfidf = summed_tfidf.A1
# Get the top term indices
top_term_indices = summed_tfidf.argsort()[-n_terms:][::-1]
# Convert indices to actual terms
top_terms = [vectorizer.get_feature_names_out()[index] for index in top_term_indices]
return top_terms
# Extract top terms for each cluster using the new method
cluster_top_terms_by_sum = {cluster_id: get_top_terms_by_summing_tfidf(cluster_id, tfidf_matrix, tfidf_vectorizer) for cluster_id in range(3)}
cluster_top_terms_by_sum
The following will get printed:
{0: [‘internet’, ‘comcast’, ‘cable’, ‘tech’, ‘security’],
1: [‘contract’, ‘speed’, ‘mbps’, ‘xfinity’, ‘customer’],
2: [‘rude’, ‘service’, ‘customer’, ‘adding’, ‘boxes’]}
The following can be recommended as the topic by looking at the words:
- Cluster 0:
- Top terms: ‘internet’, ‘comcast’, ‘cable’, ‘tech’, ‘security’
- Suggested topics: Issues related to internet service
- Cluster 1:
- Top terms: ‘contract’, ‘speed’, ‘mbps’, ‘xfinity’, ‘customer’
- Suggested topics: Issues related to contracts and equipment
- Cluster 2:
- Top terms: ‘rude’, ‘service’, ‘customer’, ‘adding’, ‘boxes’
- Suggested topic: Poor customer service
Conclusion
With a large volume of documents we encounter in today’s data-driven world, understanding the core essence of clustered texts is more crucial than ever. As we’ve seen, Python offers robust methods, from straightforward keyword extraction to the more intricate TF-IDF analysis, to suggest possible topics of our clusters.
Whether you’re diving into customer feedback, analyzing scholarly articles, or exploring any large text dataset, these methods provide valuable insights, transforming clusters from mere groups of texts into meaningful categories with distinct themes. As you continue your journey in text analytics, remember that the true power of clustering lies not just in grouping similar documents, but in comprehending and conveying the stories they tell.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me