Have you ever wondered how to build applications that not only utilize large language models (LLMs) but are also capable of interacting with their environment and connecting to other data sources. If so, then LangChain is the answer! In this blog, we will learn about what is LangChain, what are its key aspects, how does it work. We will also quickly review the concepts of prompt, tokens and temperature when using the OpenAI API. We will the learn about creating a ‘Hello World’ Python program using LangChain and OpenAI’s Large Language Models (LLMs) such as GPT-3 models.
What is LangChain Framework?
LangChain is a dynamic framework specifically designed for the development of applications that can leverage LLMs . The unique aspect of LangChain is that it encourages the creation of applications that are “data-aware” and “agentic”.
- Data-aware apps: “Data-aware” applications have the ability to connect and interact with various data sources. This feature allows them to incorporate and process external data, thereby enhancing their functionality and adaptability.
- Agent-based apps: On the other hand, “agentic” applications are designed to interact with their environment. They can respond to changes, make decisions, and take actions based on the context they operate in, making them more dynamic and interactive.
LangChain is built around several core modules, each offering standard, extendable interfaces. These modules include Models, Prompts, Memory, Indexes, Chains, Agents, and Callbacks, which are considered the building blocks of any LLM-powered application.
LangChain is versatile and can be used in a wide range of scenarios, including autonomous agents, agent simulations, personal assistants, question answering, chatbots, querying tabular data, code understanding, interacting with APIs, extraction, summarization, and evaluation.
Setting up the Environment for LangChain Apps
To get started with LangChain on Google Colab, there are several key steps you’ll need to follow:
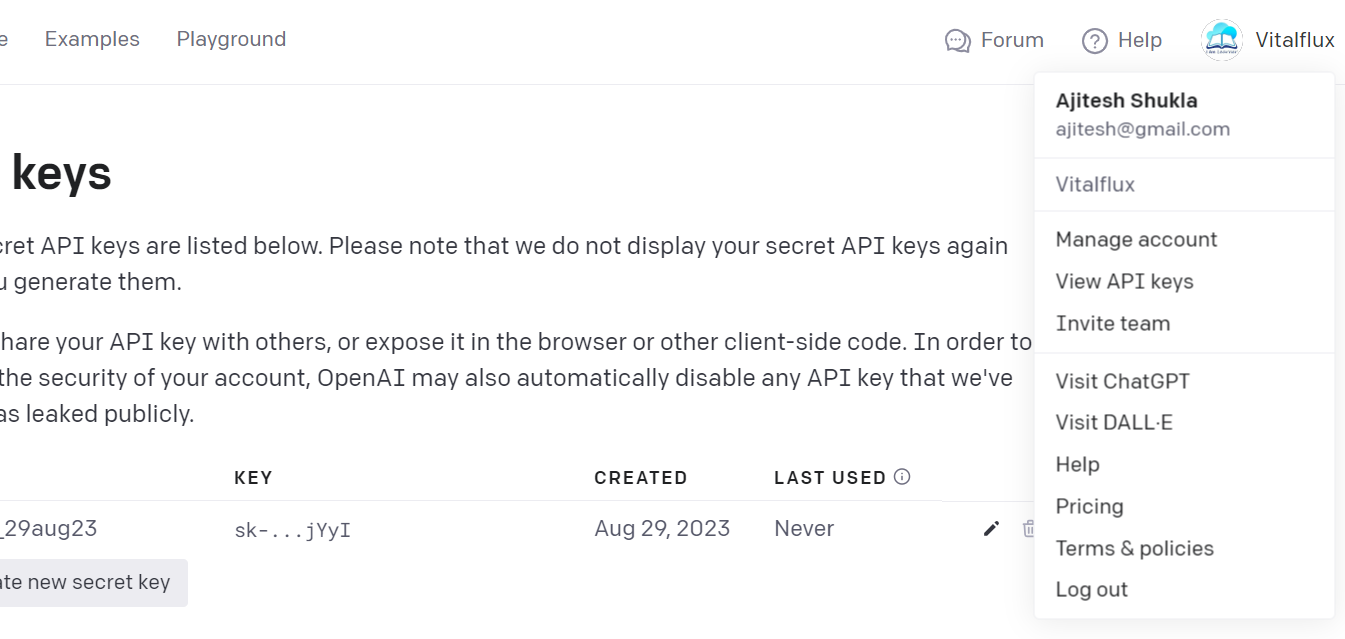
- Generate API Keys: You first need to create API key for OpenAI. To do this, visit OpenAI and follow their instructions to generate your key. You can click your user profile, then click “View API Keys” and then create your key. The picture below represents the page where you can create the API keys.
- Store API Keys: Once you have your keys, you’ll need to store them in a file named .env using the following format:
OPENAI_API_KEY="xxxxxxxxxxx"
Replace the ‘xxxxxxxxxxx’ with your actual API keys. Once your .env file is ready, upload it to the file folder in your Google Colab environment.
- Install Necessary Python Libraries: Next, you need to install the necessary Python libraries. You can do this by creating a requirements.txt file with the following content. On the day of writing the blog, the latest version of Langchain found is 0.0.174
python-dotenv==1.0.0
langchain==0.0.275
openai
azure-core
Once you’ve created this file, upload it to your Google Colab file folder. Then, run the following command in a code cell to install the libraries. Note that we need to install azure-core library for working with langchain version 0.0.174. Otherwise, you will get a warning message or error.
!pip install -r requirements.txt
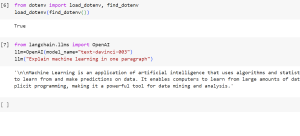
- Check Your Environment: After installing the necessary libraries, you can check if your environment is set up correctly by executing the following commands:
from dotenv import load_dotenv, find_dotenv
load_dotenv(find_dotenv())
If your environment is set up correctly, this should output True
Executing ‘Hello World’ Program using LangChain
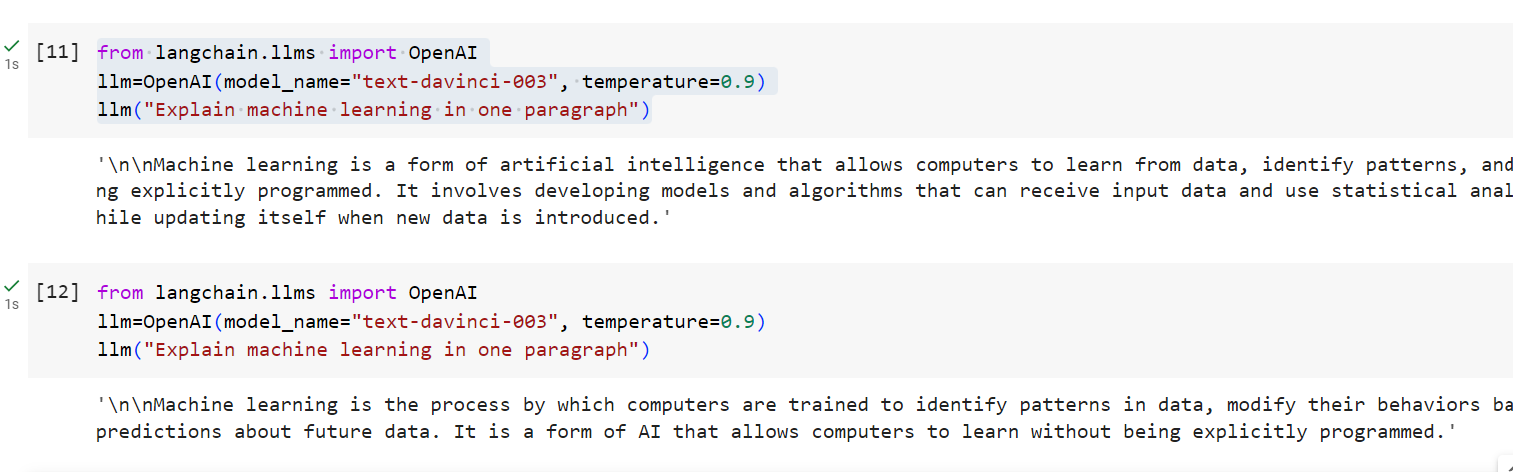
Now that your environment is ready, you can run your first LangChain command. Create a new code cell and enter/execute the following code:
from langchain.llms import OpenAI
llm=OpenAI(model_name="text-davinci-003", temperature=0.9)
llm("Explain machine learning in one paragraph")
The above Python code is using the LangChain library to interact with an OpenAI model, specifically the “text-davinci-003” model. The line, llm=OpenAI(model_name=”text-davinci-003″, temperature=0.9), is creating an instance of the OpenAI class, called llm, and specifying “text-davinci-003” as the model to be used. “text-davinci-003” is the name of a specific model provided by OpenAI. You can access information about other libraries from this page on OpenAI GPT-3 models.
If everything is set up correctly, you should see a response from the LangChain model to your prompt. Here is the screenshot representing the output:
What’s Prompt?
In the context of Large Language Models (LLMs) apps such as ChatGPT, a “prompt” is an initial input string or sequence of tokens that serves as a cue for the model to generate a response or complete a task. The prompt essentially instructs the model on what is expected, whether it’s answering a question, summarizing text, generating code, or any other task. The model uses the information encapsulated in the prompt to access its trained parameters and produce an output that is contextually relevant and coherent. Understanding how to craft effective prompts is crucial for extracting meaningful and specific responses from LLMs.
In the above picture, the prompt is “Explain machine learning in one paragraph”.
What’s Temperature?
Note the usage of the function argument, temperature. The value of temperature varies from 0 to 1. The value near 0 would ensure that LLM is as accurate as it can get. A value near 1 would allow LLM to be as creative as possible. Thus, when you set the value of temperature to be close to 0, the output is mostly same or similar while ensuring accuracy of the information. However, when you set the value close to 1 such as 0.9, you can expect different outputs with every execution.
What’s Token?
Natural language is complex and laden with nuances like slang, idioms, and grammatical rules. Machines do not understand text in the way humans do. For a machine, a text is just a sequence of characters. Tokenization is a way to convert this human-understandable text into a format that is easier for machines to understand. By breaking down text into smaller pieces or “tokens,” algorithms can more easily perform tasks such as language modeling, text summarization, translation, etc.
In the context of NLP and machine learning, a token is essentially a unit of text that the machine reads in during the process of text analysis. The term “token” is used to describe pieces of the text such as words, phrases, or other sequences, which the algorithms then process, analyze, or manipulate.
There are following three different types of tokens:
- Word Tokens: Tokens can be entire words.
- Subword Tokens: Tokens can be parts of a word.
- Character Tokens: Tokens can be individual characters.
Let’s understand the concepts of different types of tokens with example – “ChatGPT is amazing”.
| Type | Example Tokens from “ChatGPT is amazing!” |
|---|---|
| Word Tokens | ["ChatGPT", "is", "amazing", "!"] |
| Subword Tokens | ["Chat", "GPT", " is", " amazing", "!"] |
| Character Tokens | ["C", "h", "a", "t", "G", "P", "T", ...] |
When working with tokens via OpenAI APIs, the tokens are counted for both input prompt and output or response and pricing is calculated accordingly.
Another Method for LangChain Hello World
You can also quickly get started based on the following instructions:
- Set up the environment
!pip install langchain==0.0.275
!pip install openai
!pip install azure-core
- Execute the following code to get your response from ChatGPT
import os
os.environ["OPENAI_API_KEY"] = "abc-k9le9xyzabFGWAbcdEfgHijKTdAPmFnlaD123BvNO" #paste your key here
from langchain.llms import OpenAI
llm = OpenAI(temperature=0.9)
text = "Explain the concept of machine learning in one paragraph"
print(llm(text))
Conclusion
We have set up your Google Colab environment, installed and configured LangChain, and executed our first LangChain program using OpenAI’s language model. This ‘Hello World’ example is just the tip of the iceberg when it comes to the powerful capabilities of LangChain. By now, you should have a solid foundation to explore more complex tasks and dive deeper into the world of LangChain. Experiment with different prompts, play around with various settings, and continue learning.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me