Category Archives: Big Data
CEP vs Traditional Database Examples
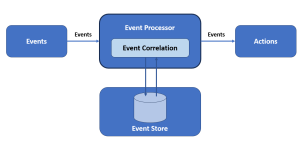
In this blog, we will learn about the differences between complex event processing (CEP) and traditional database querying with the help of examples. We will learn about how these two methodologies tackle data to extract meaningful insights but in fundamentally different ways. In complex event processing, data flows dynamically which is then matched with pre-defined patterns thereby generating insights in real-time. Traditional Database Querying In a conventional database querying scenario, the data is stored first, and then queries are run against this stored data to find patterns or retrieve information. This process is reactive, in that the query is formulated based on a need to find out something specific about …
AI-Ready Data Explained with Examples

AI-ready data usually refers to data that has been prepared in such a way that it can be effectively used for training artificial intelligence (AI) and generative AI models. In this blog, we will learn about what are the most common attributes of AI-ready data. The following are the top most 5 attributes that AI-ready data would need to have. Data must be: Check out this Gartner paper for further details – We Shape AI, AI shapes us.
NLP Corpus Types (Text & Multimodal): Examples

At the heart of NLP lies a fundamental element: the corpus. A corpus, in NLP, is not just a collection of text documents or utterances; it’s at the core of large language models (LLMs) training. Each corpus type serves a unique purpose in terms of training language models that serve different purposes. Whether it’s a collection of written texts, transcriptions of spoken words, or an amalgamation of various media forms, each corpus type holds the key to leveraging different aspects of language to generate value. In this blog, we’re going to explore the significance of these different corpora types in NLP. From the traditional text corpora consisting of written content …
Data Science & Big Data Career Paths
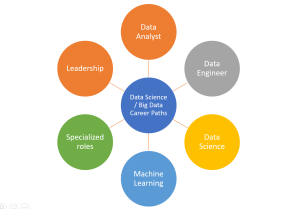
Navigating the world of data science can be as complex as the data sets that these professionals work with. As the field continues to evolve at a rapid pace, the array of job roles and career paths have expanded, encompassing a multitude of specializations ranging from Data Analysts and Machine Learning Engineers to Data Scientists. This dynamic landscape offers a wealth of opportunities, but it can also create confusion for those looking to embark on or advance their careers in data science. In this blog, we aim to demystify these career paths in data science, offering clarity on the progression of roles, responsibilities, and skills needed for each. Whether you …
Most Common Machine Learning Tasks
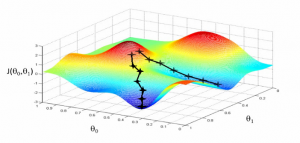
This article represents some of the most common machine learning tasks that one may come across while trying to solve machine learning problems. Also listed is a set of machine learning methods that could be used to resolve these tasks. Please feel free to comment/suggest if I missed mentioning one or more important points. Also, sorry for the typos. You might want to check out the post on what is machine learning?. Different aspects of machine learning concepts have been explained with the help of examples. Here is an excerpt from the page: Machine learning is about approximating mathematical functions (equations) representing real-world scenarios. These mathematical functions are also referred …
NoSQL Databases List & Examples
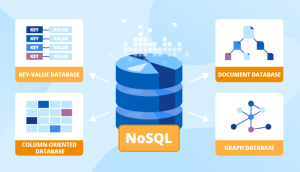
With the proliferation of big data, there has been a corresponding increase in the number of NoSQL databases. For those who are new to the term, NoSQL databases are non-relational databases that are designed to handle large amounts of data. In this blog post, we will take a look at some of the most popular NoSQL databases. NoSQL databases are a newer alternative to traditional relational databases that are designed to provide more flexibility and scalability. NoSQL databases are often used for big data applications that require real-time analysis or for applications that need to be able to handle a large amount of concurrent users. While NoSQL databases can offer …
Data Analyst Technical & Soft Skills

Do you want to become a data analyst? It’s a great career choice! Data analysts are in high demand these days. Companies rely on data analysts to help them make better decisions by turning data into insights. In order to be successful, data analysts need a mix of technical skills and soft skills. Technical skills include expertise in analyzing data. Soft skills include communication and problem-solving skills. Data analysts must be able to take data and turn it into insights that help their company make better decisions. They also need to be able to effectively communicate those insights to people who may not have a technical background. In this blog …
Building Data Analytics Organization: Operating Models
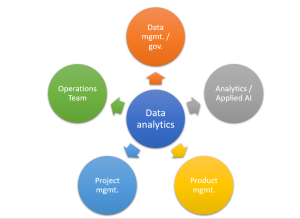
Most businesses these days are collecting and analyzing data to help them make better decisions. However, in order to do this effectively, they need to build a data analytics organization. This involves hiring the right people with the right skills, setting up the right infrastructure and creating the right processes. In this article, we’ll take a closer look at what it takes to set up a successful data analytics organization. We’ll start by discussing the importance of having the right team in place. Then we’ll look at some of the key infrastructure components that need to be put in place. Finally, we’ll discuss some of the key process considerations that …
85+ Free Online Books, Courses – Machine Learning & Data Science

This post represents a comprehensive list of 85+ free books/ebooks and courses on machine learning, deep learning, data science, optimization, etc which are available online for self-paced learning. This would be very helpful for data scientists starting to learn or gain expertise in the field of machine learning / deep learning. Please feel free to comment/suggest if I missed mentioning one or more important books that you like and would like to share. Also, sorry for the typos. Following are the key areas under which books are categorized: Data science Pattern Recognition & Machine Learning Probability & Statistics Neural Networks & Deep Learning Optimization Data mining Mathematics Here is my post …
Spark – How does Apache Spark Work?
This blog represents concepts on how does apache spark work with the help of diagrams. Following are some of the key aspects in relation with Apache Spark which is described in this blog: Apache Spark – basic concepts Apache Spark with YARN & HDFS/HBase Apache Spark with Mesos & HDFS/HBase Apache Spark – Basic Concepts The following represents basic concepts in relation with Spark: Apache Spark with YARN & HBase/HDFS Following are some of the key architectural building blocks representing how does Apache Spark work with YARN and HDFS/HBase. Spark driver program runs on client node. YARN is used as cluster manager. As part of YARN setup, there would be multiple nodes running …
HBase Architecture Components for Beginners
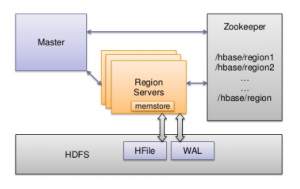
This blog represents high-level concepts on HBase architecture components. Following diagram represents the same: HBase Architecture Components – Key Building Blocks Following diagram represents the same: Pay attention to some of the following in relation to above diagram: HMaster: Responsible for coordinating the region servers including assigning regions on startup as well as recovery, and, monitoring region servers using Zookeeper Region Servers: Manages one or more regions Zookeeper: Zookeeper is used as a distributed coordination service for maintaining the server state of the cluster. Regions: Records in HBase tables are split horizontally based on the key range. Each of these splits can be called as Regions. A region contains all rows in …
When a Spark application starts on Spark Standalone Cluster?
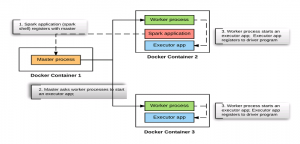
This article represents detailed view on what happens when a driver program (spark application) is started on one of the worker node when working with Spark standalone cluster. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key points described later in this article: Snapshot into what happens when Spark Standalone Cluster Starts? Snapshot into what happens when a spark application (Spark Shell) starts on one of the worker nodes? Snapshot into what happens when a spark application (Spark Shell) stops on the worker node? Snapshot into what happens when Spark Standalone Cluster Starts? In our …
Hello World with Apache Spark Standalone Cluster on Docker
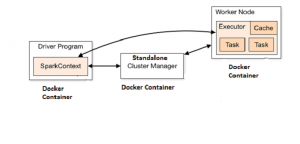
This article presents instructions and code samples for Docker enthusiasts to quickly get started with setting up Apache Spark standalone cluster with Docker containers. Thanks to the owner of this page for putting up the source code which has been used in this article. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key points described later in this article: Basic concepts on Apache Spark Cluster Steps to setup the Apache spark standalone cluster Code sample for Setting up Spark Code sample for Docker-compose to start the cluster Code sample for starting the Driver program using Spark …
Dockers – How to Get Started with Spark on Windows
This article represents tips on how to get started with Apache Spark on Windows using Dockers. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. If you are familiar with Dockers, the instructions below would help you get started with Spark in no time. Download the Spark from https://spark.apache.org/downloads.html page. Remember to select a package type with option such as “Pre-built…”. Once the zipped files are downloaded, unzip the files under the location “C:\Users\<Username>” Build Java8 image and start the container. Follow the instructions on this page, http://vitalflux.com/dockers-how-to-get-started-with-java8-dev-environment/. Once the container is started, go to the folder where you …
9 Linux Foundation Projects for IOT, Cloud, Big Data
This article represents top Linux foundation projects in relation with IOT, Cloud and Big Data. With the convergence of these three technology domains, it becomes of utmost important to keep a track of news/announcements happening in these areas. The reference of all the projects could be found on this page. Following are the key linux foundation projects in relation with IOT, Cloud and Big Data. IOT (Internet of Things) AllSeen Alliance: A cross-industry consortium dedicated to enabling interoperability of billions of devices, services and apps that comprise the internet of things (IOT). Bookmark announcements and news for latest information. IoTivity: An open-source software framework enabling seamless device-to-device connectivity to address …
Top 5 Pages listing Big Data Conferences in 2016

This article represents top 5 pages listing global big data conferences coming up in 2016. Please feel free to comment/suggest if I missed to mention any other important pages. Also, sorry for the typos. Following are the top 5 pages: Global Big Data Conference KDNuggets List of Meetings/Conferences on Analytics, Big Data, Data Mining, Data Science Important Big Data events coming up in 2016 Big Data conference directory listing big data conferences happening around the world. O’Reilly List of conferences of on various topics including Big Data
I found it very helpful. However the differences are not too understandable for me