Are you fascinated by the power of deep learning large language models that can generate creative writing, answer complex questions, etc? Ever wondered how these LLMs understand and process human language with such finesse? At the heart of these remarkable achievements lies a machine learning model architecture that has revolutionized the field of Natural Language Processing (NLP) – the Transformer architecture and its types.
But what makes Transformer models so special? From encoding sentences into numerical embeddings to employing attention mechanisms that capture the relationships between words, we will dissect different types of Transformer architectures, provide real-world examples, and even dive into the mathematics that governs its operation. Let’s explore the Encoder-only Transformer, Decoder-only Transformer, and Encoder-Decoder Transformer architectures, uncovering their potential applications. To get a good understanding of this topic, you might want to check this book – Natural Language Processing with Transformers – Revised Edition. Before getting started, let’s quickly look at some of the applications of different types of transformer architectures explained in later sections.
| Architecture Types | Examples | Use cases |
|---|---|---|
| Encoder-only transformers | BERT (Google) | Sentence classification, named entity recognition, extractive question answering |
| Encoder-decoder transformers | T5 (Google) | Summarization, translation, question answering |
| Decoder-only transformers | GPT Series (OpenAI) | Text generation |
You might also want to check out this book which has explained the transformer concepts in a great manner: Generative Deep Learning.
Encoder-Decoder Transformer Architecture
The Transformer architecture was initially introduced by Vaswani et al. in 2017 for sequence-to-sequence tasks, particularly machine translation. The original transformer architecture was based on the encoder-decoder architecture for performing tasks such as machine translation. However, one or both of these components form different types of transformer architecture discussed later in this blog. The following are key components of any transformer architecture including encoder-decoder architecture.
- Encoder Block: The encoder’s primary job is to understand and represent the input sequence. It translates the raw input tokens into a form that the model can work with, often referred to as the hidden state or context. The following are key steps that happen in the encoder:
- Tokenization: Splits the input text into individual tokens, such as words and sub-words.
- Token embeddings: Maps each token to a continuous vector space using pre-trained embeddings.
- Positional embeddings: Adds information about the order of the tokens in the sequence.
- Multiple Layers of Transformation: Applies multiple layers of attention and feed-forward neural networks to create the final hidden state.
- Decoder Block: The decoder uses the encoder’s hidden state to generate an output sequence iteratively, translating the internal representation into the target language or format. The following represents key steps that happen in the decoder:
- Initialization: Starts with an initial token, like the beginning-of-sentence token.
- Iterative Generation: Generates one token at a time, considering both the previous tokens and the encoder’s hidden state.
- Attention Mechanism: Uses attention to focus on relevant parts of the encoder’s hidden state, aligning with the target sequence.
- Termination: Stops generating when a specific end token is produced or a maximum length is reached.
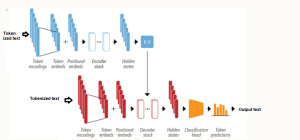
The following is the high-level transformer architecture representing input tokens, embeddings, encoder, decoder, and the softmax output which helps the model choose the next token to generate from a probability distribution across the entire token vocabulary. Greater details can be found in this book – Generative AI on AWS. The input prompt is stored in a construct called the input “context window“. It’s measured by the number of tokens it holds. The size of the context window varies widely from model to model. Each input token in the input context window is mapped to an embedding. The encoder encodes sequences of input tokens into a vector space that represents the structure and meaning of the input. The output of the encoder is attention weights which are passed through the decoder. The decoder uses the attention-based contextual understanding of the input tokens to help generate new tokens, which ultimately “completes” the provided input. The softmax output layer generates a probability distribution across the entire token vocabulary in which each token is assigned a probability that it will be selected next. Typically, the token with the highest probability will be generated as the next token
The following picture represents another viewpoint covering the encoder-decoder transformer architecture. Watch out for the encoder and decoder stack whose components are explained in the encoder-only and decoder-only transformer architecture section.
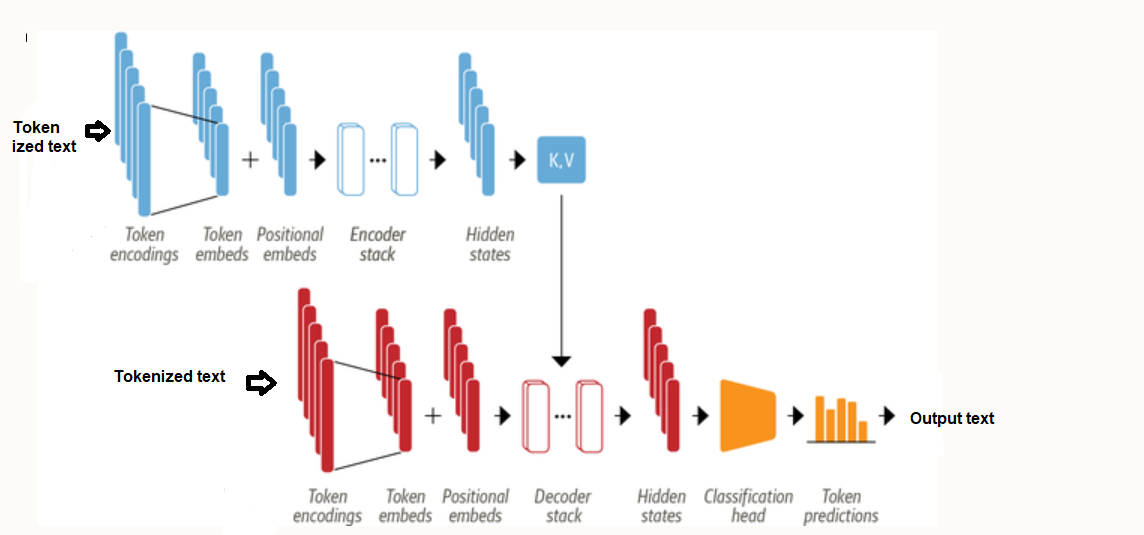
The original transformer model was able to translate between languages, such as English to German, by encoding the input sentence in the source language and decoding it in the target language. Over time, researchers recognized that the individual components of the Transformer (i.e., the Encoder and Decoder blocks) could be used separately, each having unique applications.
Encoder-only Transformer Architecture
The Encoder-only architecture is often employed in tasks like text classification, sentiment analysis, and embedding generation. BERT (Bidirectional Encoder Representations from Transformers) is a widely used Encoder-only model. It has been pre-trained on a large corpus of text and can be fine-tuned for specific NLP tasks.
Why do we need encoder-only transformer architecture?
Traditional models, such as Bag-of-Words (BoW) or simple word embeddings like Word2Vec, often lose the contextual information of words in a sentence. Consider the sentence “Apple is a tech company, not a fruit in this context.” Traditional word embeddings might represent the word “Apple” in the same way, regardless of whether it refers to the fruit or the technology company. This lack of context can lead to misinterpretation or loss of specific meaning.
To solve the above limitation of traditional models such as BoW, encoder-only architecture comes to the rescue.
Encoder-only transformers maintain the context by paying attention to all the words in the sentence simultaneously. It achieves this with multi-head self-attention, bidirectional understanding, and positional embedding. Let’s use the same sentence, “Apple is a tech company, not a fruit in this context.” An encoder-only transformer like BERT would analyze the relationships between “Apple” and other words like “tech” and “company” in the sentence. By doing so, it understands that “Apple” here refers to the technology company and not the fruit.
Components of Encoder-only Transformer Architecture
The following represents key components of encoder-only architecture:
- Multiple Encoder Layers: Typically contains several layers of encoders, each comprising multi-head self-attention and feed-forward neural networks. The picture below represents the same.
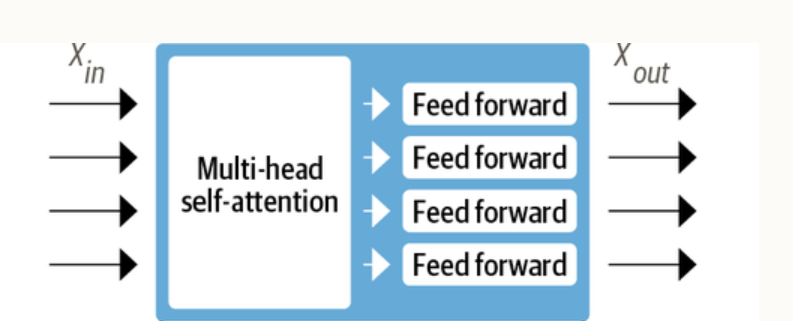
- Positional Embedding: Adds positional information to the input tokens to understand the sequence of words in a sentence.
- Self-Attention Mechanism: This enables the model to consider other words in the input when encoding a particular word.
Decoder-only Transformer Architecture
Generating text that is both coherent and contextually consistent is a significant challenge in many NLP tasks, such as text generation, machine translation, and content summarization. Decoder-only transformer architectures have been designed to address this problem. GPT (Generative Pre-trained Transformer) models such as GPT-2 and GPT-3 utilize a Decoder-only structure to generate coherent and contextually relevant text.
In a text generation task, a model might be required to write a paragraph about “solar energy.” A traditional model may generate disconnected sentences, losing coherence, and sometimes contradicting itself, such as stating both “Solar energy is renewable” and “Solar energy is non-renewable” in the same paragraph.
Decoder-only transformer models address this problem by generating text sequentially and considering the context of previous words. Decoder-only models generate text one word at a time, taking into account all the previously generated words. For example, if the model is generating a story that starts with “Once upon a time,” it remembers this beginning and ensures that the subsequent text aligns with a fairy-tale theme. By using attention mechanisms, the model focuses on different parts of the previously generated text, ensuring that the next word fits within the existing context. For example, in translating a complex sentence from English to French, the model considers the entire source sentence, maintaining grammatical and thematic consistency in the translation.
Components of Decoder-only Transformer Architecture
The following represents key components of decoder-only architecture:
- Multiple Decoder Layers: Composed of several layers, each with masked multi-head self-attention, encoder decoder attention, and feed-forward neural networks. The following represents decoder blocks.
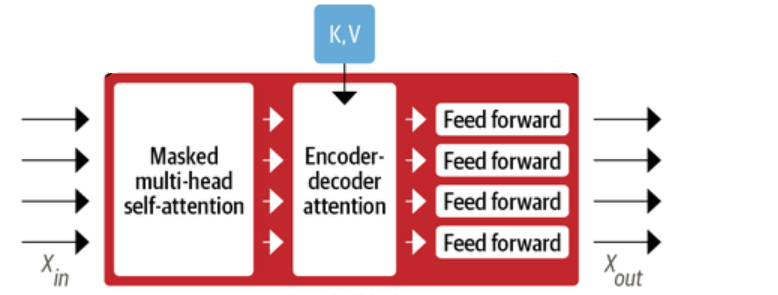
- Positional Embedding: Similar to the Encoder-only model, adding information about the order of words.
- Masked Multi-Head Self-Attention Layer: Masked multi-head self-attention layer found in each decoder block ensures that the tokens generated at each time step are based only on the current token and the past output.
- Encoder-decoder attention layer: The encoder-decoder attention layer enables the decoder to consider the entire input sequence (from the encoder) and the partially decoded sequence simultaneously. This assists in tasks that require understanding the relationship between two different sequences, such as translation between two languages.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me