Last updated: 23rd Jan, 2024
Two NLP concepts that are fundamental to large language models (LLMs) are transfer learning and fine-tuning pre-trained LLMs. Rather, true fine-tuning can also be termed as full fine-tuning because transfer learning is also a form of fine-tuning. Despite their interconnected nature, they are distinct methodologies that serve unique purposes when training foundation LLMs to achieve different objectives. In this blog, we will explore the differences between transfer Learning and full fine-tuning, learning about their characteristics and how they come into play in real-world scenarios related to natural language understanding (NLU) and natural language generation (NLG) tasks with the help of examples. We will also learn about a popular strategy within transfer learning called parameter-efficient fine-tuning (PEFT).
What is Transfer Learning?
Transfer Learning is an LLM concept that refers to the utilization of pre-trained LLMs on a new but related task. It involves using existing foundation LLMs from the LLM family such as BERT (NLU), GPT (NLG), etc that were trained on a particular task (source task – NLU or NLG) and adapting it for a different but related task (target task). We can call the target task a domain adaptation of the source task. The primary goal is to leverage the knowledge gained from the source task to achieve better performance on the target task, especially when there is limited labeled data for the target task. Note that in transfer learning, you don’t pre-train the model from scratch.
The training scope for transfer learning is that only the latter layers (including parameters) of the model are trained (or fine-tuned) to specialize for the new task. The early layers (and associated parameters) are often frozen because they capture universal features like edges and textures that are useful for many tasks. This training method is also called parameter-efficient fine-tuning (PEFT). PEFT techniques freeze most of the parameters of the pre-trained model and fine-tune a smaller set of parameters. Having talked about PEFT, note that transfer learning encompasses a wider range of strategies, including but not limited to parameter-efficient fine-tuning (PEFT) methods.
The following is how transfer learning works:
- Identify Pre-Trained LLM: Start with a model that has already been trained on a large dataset, often related to a general domain. Let’s say a BERT or LLAMA 2 model trained with English text to understand nuances of the English language.
- Determine target task: Identify the new task you want the model to perform. This task should be related to the source task in some way. For example, classify the contract documents in procurement. Or, for that matter, classify the resumes for recruitment teams.
- Perform domain adaptation as a result of transfer learning: The pre-trained model is then used as a starting point for the target task. Depending on the problem, some layers of the model might be frozen (i.e., their parameters are not updated).
Example illustrating how transfer learning works
Task 1: Training a Model for Predicting Next Words (Auto-regressive model – NLG – GPT Family)
This step can be skipped completely if we want to use an existing LLM. For transfer learning, a pre-trained GPT model can be taken as a starting point. The following is just a reference of how pre-training LLM can be created if it does not exist.
- Problem: Predicting the next words based on the previous words. This can also be called pre-training.
- Data: A large dataset containing millions of words from sources such as Wikipedia.
- Model: A large language model (LLM) such as GPT trained on this data.
- Outcome: The trained model can now accurately predict the next words based on the previous words.
Task 2: Adapt the Pre-trained LLM to In-domain Corpus (New Domain)
- Problem: Now, we want to adapt the model to predict the next words in the target corpus, e.g., book reviews. This can also be called domain adaptation.
- Solution: Transfer Learning.
- Step 1: Take the pre-trained LLM from Task 1 (Pre-trained on Wikipedia corpus).
- Step 2: Remove the layer(s) that are specific to predicting the next words.
- Step 3: Add a new layer(s) specific to next-word prediction in book reviews.
- Step 4: Train the modified model on the smaller book review text.
- Outcome: The model can now predict words in the target corpus, e.g., book reviews.
Why It Works
- The early layers of LLM trained for predicting the next words often learn to detect generic features.
- These features are common to many of the next-word prediction tasks.
- By keeping these early layers and only retraining the later, task-specific layers, we can transfer the knowledge the model has gained from predicting words in English to the new task of predicting the next words in the target corpus.
Advantages of Transfer Learning
The following are some of the advantages of transfer learning:
- Efficiency: Reduces the need for extensive data in the target task given a pre-trained model is already created.
- Speed: Minimizes the training time, as the model has already learned relevant features based on pre-training.
- Performance: Often leads to better performance, especially when the target task has limited labeled data.
What is Fine-tuning or Full Fine-tuning Task?
Fine-tuning, also called full fine-tuning, involves taking a pre-trained model that has been trained on a large dataset (usually for a related task) and adapting it for a specific task by continuing the training process on a smaller, task-specific dataset. At a high level, with full fine-tuning, you’re updating every model parameter through supervised learning. Here is the process in brief:
- Start with a pre-trained LLM.
- Determine the task.
- Perform fine-tuning. During fine-tuning, all of the weights of the pre-trained model are adjusted to better perform on the new task.
Full fine-tuning often requires a large amount of GPU RAM, which quickly increases your overall computing budget and cost. Transfer learning / PEFT reduces the compute and memory requirements by freezing the original foundation model parameters and only fine-tuning a small set of new model parameters.
Example illustrating how fine-tuning works
Extending the example in the transfer learning section, here is how the fine-tuning task will look like:
Task 3: Classify the sentiments of book reviews
In this step, the LLM adapted to book reviews can be fine-tuned with a classification layer for the target task (e.g., classifying the sentiment of book reviews). This step can be called fine-tuning.
Differences between Transfer Learning & Fine Tuning
The following is a detailed comparison between transfer learning and fine-tuning, highlighting the differences between the two concepts along with examples for each point:
| Aspects | Transfer Learning | Full Fine-tuning |
| Definition | In transfer learning, only a small subset of the model’s parameters or a few task-specific layers are trained while keeping the majority of the pre-trained model’s parameters frozen. One of the popular transfer learning strategies is PEFT. | In full fine-tuning, all the parameters of a pre-trained model are updated during the training process. This means the weights of every layer in the model are adjusted based on the new training data. This approach can lead to significant changes in the model’s behavior and performance, tailored to the specific task or dataset at hand. |
| Objective | The goal is to adapt the pre-trained model to a new task with minimal changes to its parameters. This approach seeks to find an optimal balance between retaining the general knowledge acquired during pre-training and making enough task-specific adjustments to perform well on the new task. | The goal is to comprehensively adapt the entire pre-trained model to a new task or dataset. The aim is to maximize performance on that specific task. |
| Model Architecture | Utilizes existing architecture; Freezes most of the layers. Only a small set of parameters are fine-tuned. | With full fine-tuning, every parameter of the LLM gets updated. |
| Training Process | May involve only training a new top layer while keeping other layers fixed. In some cases, the number of newly trained parameters is just 1–2% of the original LLM weights. | Involves adjusting specific layers and parameters for the new task. |
| Data Requirement | Smaller dataset with fewer examples | Requires task-specific large data set for fine-tuning. |
| Computational Complexity | This approach is generally more resource-efficient, as only a small portion of the model is being updated. It requires less memory and processing power and often leads to faster training times. This makes it more accessible for situations with limited computational resources or for quick experimentation. | Since it involves updating all the parameters, full fine-tuning is typically more computationally intensive and time-consuming. It requires more memory and processing power, as well as potentially longer training times, especially for large models. Full fine-tuning often requires a large amount of GPU RAM. |
| Storage requirements | Reduced storage requirements | Increased storage requirements model |
| Model performance | Performance can be similar, but often a bit lower than full fine-tuning | Typically results in higher performance |
| Inference hosting Requirements | What is needed is to host original LLM and additional model weights for inference | Each fine-tuned model must be hosted |
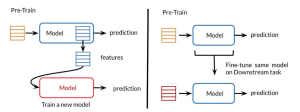
The following picture represents the difference between transfer learning and fine-tuning or full fine-tuning. The left one represents transfer learning and the right one represents fine tuning.
Conclusion
- Transfer Learning: Focuses on transferring general knowledge from one domain to another. It often involves using the same objective function and may freeze certain layers to retain general features.
- Fine-Tuning: Goes a step further by specializing the model to a particular task. This may involve modifying the objective function, adjusting specific layers, and unfreezing parts of the model for targeted training.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Agentic Reasoning Design Patterns in AI: Examples - October 18, 2024
- LLMs for Adaptive Learning & Personalized Education - October 8, 2024
- Sparse Mixture of Experts (MoE) Models: Examples - October 6, 2024
I found it very helpful. However the differences are not too understandable for me