
A pre-trained or foundation model is further trained (or fine-tuned) with instructions datasets to help them learn about your specific data and perform humanlike tasks. These models are called instruction fine-tuning LLMs. In this blog, we will learn about the concepts and different examples of instruction fine-tuning models. You might want to check out this book to learn more: Generative AI on AWS.
What are Instruction fine-tuning LLMs?
Instruction fine-tuning LLMs, also called chat or instruct models, are created by training pre-trained models with different types of instructions. Instruction fine-tuning can be defined as a type of supervised machine learning that improves the foundation model by continuously comparing the model’s output for a given input (e.g., instruction prompt with dialogue) to the ground truth label (e.g., human baseline summary). The weights of the foundation LLM are updated accordingly based on the comparison. This process is continued for each instruction prompt.
A pre-trained model can be fine-tuned with your custom dataset, such as conversations between your customer support agents and your customers to create instruction fine-tuned LLM specific to your needs.
For example, take a pre-trained LLM such as Llama-2-70b and train with specific instructions such as some of the following to create instruction fine-tuning LLM.
- Summarize the following text: …
- Rate this review: …
- Translate into Python code: …
- Identify the places: …
The following image represents the same:
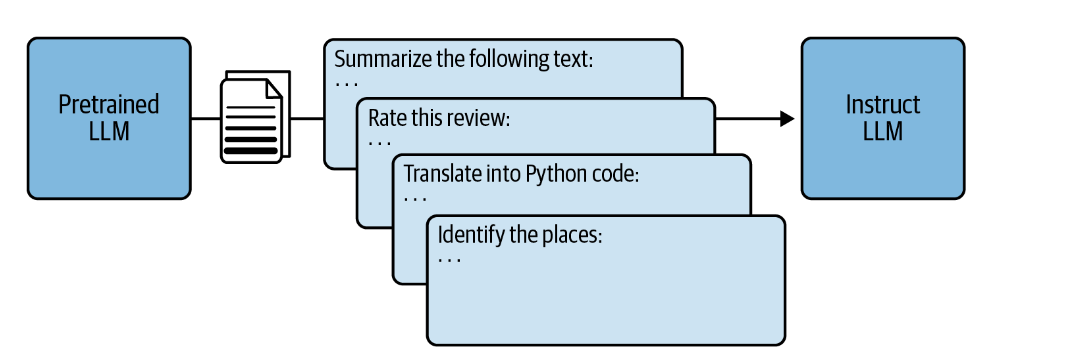
You would need a lot many instructions like the above. The instructions can be related to some of the following tasks:
- Commonsense reasoning, question generation, closed-book question answering (QA), adversarial QA, extractive QA
- Natural language inference, code instruction generation, code repair, dialogue context generation, and summarization
- Arithmetic reasoning, commonsense reasoning, explanation generation, sentence composition, and implicit reasoning
- Cause/effect classification, commonsense reasoning, named entity recognition, toxic language detection, and question-answering
By training the model on a mixed-instruction dataset such as those related to the above tasks, the performance of the model can be improved on many tasks simultaneously thereby avoiding the issue of catastrophic forgetting, and maintaining the model’s ability to generalize to multiple tasks.
Examples of Instruction Fine-tuning LLM
The following are some examples of instruction fine-tuned LLMs:
- Llama 2-Chat: The Llama-2-70b-chat is an instruction fine-tuned variant of the larger Llama-2-70b foundation model. Many practical applications and examples throughout the field, including prompt engineering techniques discussed in educational materials, utilize the Llama 2 family, particularly its ‘chat’ variant. This model is tailored to understand and engage in conversational exchanges, often employed in settings that require nuanced understanding and generation of dialogue.
- Falcon-Chat: The variant of Falcon-180b such as Falcon-180b-chat is another example of instruction fine-tuning LLM. It is fine-tuned with a diverse set of instructional tasks, enhancing its capability to perform a wide array of activities and respond accurately to a variety of prompts.
- FLAN-T5: FLAN-T5 is instruction fine-tuned generative LLMs and serves as the instruct variant of the base T5 model. The FLAN instruction dataset, currently on version 2, is a collection of 473 different datasets across 146 task categories and nearly 1,800 fine-grained tasks. One of the datasets in the FLAN collection, samsum, contains 16,000 conversations and human-curated summaries.
How do we build an instruction dataset from a given dataset?
Prompt templates can be used to build an instruction dataset from a given dataset by formatting the text as instructions. Examples of prompt templates can be found on this page – Prompt template. Here is a glimpse of it:
("Multi-choice problem: {context}\n{options_}", "{answer}"),
("Complete the passage.\n\n{context}\n{options_}", "{answer}"),
("How does this following sentence end (see "
"options)?\n\n{context}\n{options_}", "{answer}"),
("What is the most logical completion for the following text (see "
"options)?\n\n{context}\n{options_}", "{answer}"),
("Multi-choice problem: How does this text "
"end?\n\n{context}\n{options_}", "{answer}"),
("Choose from the options on what happens "
"next.\n\n{context}\n{options_}", "{answer}"),
("Complete the following sentence.\n\n{context}\n{options_}",
"{answer}"),
("Choose from options: Fill in the remainder of the "
"sentence.\n\n{context}\n{options_}", "{answer}"),
("What is the next event listed in the options is "
"correct?\n\n{context}\n{options_}\nA:", "{answer}"),
("Complete the rest of the sentence by choosing from "
"options.\n\n{context}\n{options_}", "{answer}"),
There is a great chapter in this book, Generative AI on AWS, including how you could go about training your instruction fine-tuning LLM using Amazon Sagemaker Studio.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me