Tag Archives: python
Free Online Books – Machine Learning with Python

This post lists down free online books for machine learning with Python. These books covers topiccs related to machine learning, deep learning, and NLP. This post will be updated from time to time as I discover more books. Here are the titles of these books: Python data science handbook Building machine learning systems with Python Deep learning with Python Natural language processing with Python Think Bayes Scikit-learn tutorial – statistical learning for scientific data processing Python Data Science Handbook Covers topics such as some of the following: Introduction to Numpy Data manipulation with Pandas Visualization with Matplotlib Machine learning topics (Linear regression, SVM, random forest, principal component analysis, K-means clustering, Gaussian …
Gradient Boosting Regression Python Examples
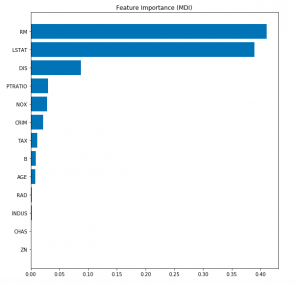
In this post, you will learn about the concepts of Gradient Boosting Regression with the help of Python Sklearn code example. Gradient Boosting algorithm is one of the key boosting machine learning algorithms apart from AdaBoost and XGBoost. What is Gradient Boosting Regression? Gradient Boosting algorithm is used to generate an ensemble model by combining the weak learners or weak predictive models. Gradient boosting algorithm can be used to train models for both regression and classification problem. Gradient Boosting Regression algorithm is used to fit the model which predicts the continuous value. Gradient boosting builds an additive mode by using multiple decision trees of fixed size as weak learners or …
Keras CNN Image Classification Example
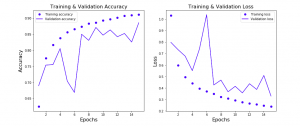
In this post, you will learn about how to train a Keras Convolution Neural Network (CNN) for image classification. Before going ahead and looking at the Python / Keras code examples and related concepts, you may want to check my post on Convolution Neural Network – Simply Explained in order to get a good understanding of CNN concepts. Keras CNN Image Classification Code Example First and foremost, we will need to get the image data for training the model. In this post, Keras CNN used for image classification uses the Kaggle Fashion MNIST dataset. Fashion-MNIST is a dataset of Zalando’s article images—consisting of a training set of 60,000 examples and a …
Keras Neural Network for Regression Problem
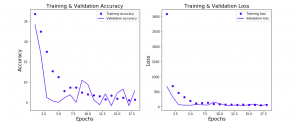
In this post, you will learn about how to train neural network for regression machine learning problems using Python Keras. Regression problems are those which are related to predicting numerical continuous value based on input parameters / features. You may want to check out some of the following posts in relation to how to use Keras to train neural network for classification problems: Keras – How to train neural network to solve multi-class classification Keras – How to use learning curve to select most optimal neural network configuration for training classification model In this post, the following topics are covered: Design Keras neural network architecture for regression Keras neural network …
Keras Multi-class Classification using IRIS Dataset
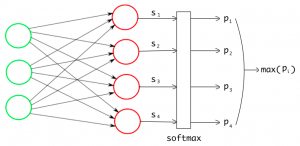
In this post, you will learn about how to train a neural network for multi-class classification using Python Keras libraries and Sklearn IRIS dataset. As a deep learning enthusiasts, it will be good to learn about how to use Keras for training a multi-class classification neural network. The following topics are covered in this post: Keras neural network concepts for training multi-class classification model Python Keras code for fitting neural network using IRIS dataset Keras Neural Network Concepts for training Multi-class Classification Model Training a neural network for multi-class classification using Keras will require the following seven steps to be taken: Loading Sklearn IRIS dataset Prepare the dataset for training and testing …
Python – How to Add Trend Line to Line Chart / Graph

In this plot, you will learn about how to add trend line to the line chart / line graph using Python Matplotlib.As a data scientist, it proves to be helpful to learn the concepts and related Python code which can be used to draw or add the trend line to the line charts as it helps understand the trend and make decisions. In this post, we will consider an example of IPL average batting scores of Virat Kohli, Chris Gayle, MS Dhoni and Rohit Sharma of last 10 years, and, assess the trend related to their overall performance using trend lines. Let’s say that main reason why we want to …
Python Sklearn – How to Generate Random Datasets
In this post, you will learn about some useful random datasets generators provided by Python Sklearn. There are many methods provided as part of Sklearn.datasets package. In this post, we will take the most common ones such as some of the following which could be used for creating data sets for doing proof-of-concepts solution for regression, classification and clustering machine learning algorithms. As data scientists, you must get familiar with these methods in order to quickly create the datasets for training models using different machine learning algorithms. Methods for generating datasets for Classification Methods for generating datasets for Regression Methods for Generating Datasets for Classification The following is the list of …
Adaptive Linear Neuron (Adaline) Python Example
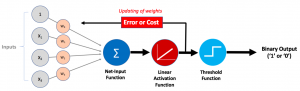
In this post, you will learn the concepts of Adaline (ADAptive LInear NEuron), a machine learning algorithm, along with Python example.As like Perceptron, it is important to understand the concepts of Adaline as it forms the foundation of learning neural networks. The concept of Perceptron and Adaline could found to be useful in understanding how gradient descent can be used to learn the weights which when combined with input signals is used to make predictions based on unit step function output. Here are the topics covered in this post in relation to Adaline algorithm and its Python implementation: What’s Adaline? Adaline Python implementation Model trained using Adaline implementation What’s Adaptive …
Python Implementations of Machine Learning Models
This post highlights some great pages where python implementations for different machine learning models can be found. If you are a data scientist who wants to get a fair idea of whats working underneath different machine learning algorithms, you may want to check out the Ml-from-scratch page. The top highlights of this repository are python implementations for the following: Supervised learning algorithms (linear regression, logistic regression, decision tree, random forest, XGBoost, Naive bayes, neural network etc) Unsupervised learning algorithms (K-means, GAN, Gaussian mixture models etc) Reinforcement learning algorithms (Deep Q Network) Dimensionality reduction techniques such as PCA Deep learning Examples that make use of above mentioned algorithms Here is an insight into …
Python – Extract Text from HTML using BeautifulSoup

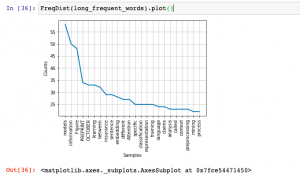
In this post, you will learn about how to use Python BeautifulSoup and NLTK to extract words from HTML pages and perform text analysis such as frequency distribution. The example in this post is based on reading HTML pages directly from the website and performing text analysis. However, you could also download the web pages and then perform text analysis by loading pages from local storage. Python Code for Extracting Text from HTML Pages Here is the Python code for extracting text from HTML pages and perform text analysis. Pay attention to some of the following in the code given below: URLLib request is used to read the html page …
Python – Extract Text from PDF file using PDFMiner
In this post, you will get a quick code sample on how to use PDFMiner, a Python library, to extract text from PDF files and perform text analysis. I will be posting several other posts in relation to how to use other Python libraries for extracting text from PDF files. In this post, the following topic will get covered: How to set up PDFMiner Python code for extracting text from PDF file using PDFMiner Setting up PDFMiner Here is how you would set up PDFMiner.six. You could execute the following command to get set up with PDFMiner while working in Jupyter notebook: Python Code for Extracting Text from PDF file …
RANSAC Regression Explained with Python Examples
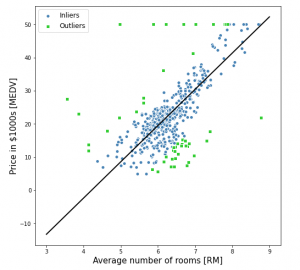
In this post, you will learn about the concepts of RANSAC regression algorithm along with Python Sklearn example for RANSAC regression implementation using RANSACRegressor. RANSAC regression algorithm is useful for handling the outliers dataset. Instead of taking care of outliers using statistical and other techniques, one can use RANSAC regression algorithm which takes care of the outlier data. In this post, the following topics are covered: Introduction to RANSAC regression RANSAC Regression Python code example Introduction to RANSAC Regression RANSAC (RANdom SAmple Consensus) algorithm takes linear regression algorithm to the next level by excluding the outliers in the training dataset. The presence of outliers in the training dataset does impact …
K-means Clustering Elbow Method & SSE Plot – Python
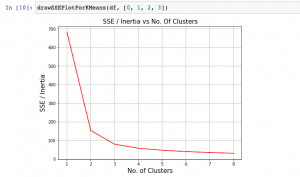
In this plot, you will quickly learn about how to find elbow point using SSE or Inertia plot with Python code and You may want to check out my blog on K-means clustering explained with Python example. The following topics get covered in this post: What is Elbow Method? How to create SSE / Inertia plot? How to find Elbow point using SSE Plot What is Elbow Method? Elbow method is one of the most popular method used to select the optimal number of clusters by fitting the model with a range of values for K in K-means algorithm. Elbow method requires drawing a line plot between SSE (Sum of Squared errors) …
Adaboost Algorithm Explained with Python Example
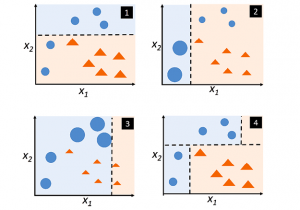
In this post, you will learn about boosting technique and adaboost algorithm with the help of Python example. You will also learn about the concept of boosting in general. Boosting classifiers are a class of ensemble-based machine learning algorithms which helps in variance reduction. It is very important for you as data scientist to learn both bagging and boosting techniques for solving classification problems. Check my post on bagging – Bagging Classifier explained with Python example for learning more about bagging technique. The following represents some of the topics covered in this post: What is Boosting and Adaboost Algorithm? Adaboost algorithm Python example What is Boosting and Adaboost Algorithm? As …
Hard vs Soft Voting Classifier Python Example
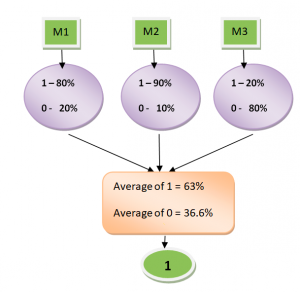
In this post, you will learn about one of the popular and powerful ensemble classifier called as Voting Classifier using Python Sklearn example. Voting classifier comes with multiple voting options such as hard and soft voting options. Hard vs Soft Voting classifier is illustrated with code examples. The following topic has been covered in this post: Voting classifier – Hard vs Soft voting options Voting classifier Python example Voting Classifier – Hard vs Soft Voting Options Voting Classifier is an estimator that combines models representing different classification algorithms associated with individual weights for confidence. The Voting classifier estimator built by combining different classification models turns out to be stronger meta-classifier that balances out the individual …
PyTorch – How to Load & Predict using Resnet Model

In this post, you will learn about how to load and predict using pre-trained Resnet model using PyTorch library. Here is arxiv paper on Resnet. Before getting into the aspect of loading and predicting using Resnet (Residual neural network) using PyTorch, you would want to learn about how to load different pretrained models such as AlexNet, ResNet, DenseNet, GoogLenet, VGG etc. The PyTorch Torchvision projects allows you to load the models. Note that the torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision. Here is the command: The output of above will list down all the pre-trained models available for loading and prediction. You may …
I found it very helpful. However the differences are not too understandable for me