
In this post, you will learn about how to use Python BeautifulSoup and NLTK to extract words from HTML pages and perform text analysis such as frequency distribution. The example in this post is based on reading HTML pages directly from the website and performing text analysis. However, you could also download the web pages and then perform text analysis by loading pages from local storage.
Python Code for Extracting Text from HTML Pages
Here is the Python code for extracting text from HTML pages and perform text analysis. Pay attention to some of the following in the code given below:
- URLLib request is used to read the html page associated with the given URL. In this example, I have taken URL from CNN.com in relation to Trump returns from hospital to White house inspite of him suffering from Covid-19 and hospitalised for special care.
- Once the HTML is obtained using urlopen(html).read() method, the HTML text is obtained using get_text() method of BeautifulSoup. In some of the NLP books, NLTK.clean_html() method is suggested. However, NLTK.clean_html method is deprecated in latest NLTK implementation. Using NLTK.clean_html method throws exception message such as To remove HTML markup, use BeautifulSoup’s get_text() function.
- NLTK.word_tokenize method can be used to retrieve words / punctuations once HTML text is obtained.
- Once can then apply word filtering techniques to further filter different words meeting the criteria such as word length etc.
- One can also create NLTK Text instance to use NLTK APIs such as FreqDist for creating frequency distribution.
from __future__ import division
import nltk, re, pprint
from urllib import request
from bs4 import BeautifulSoup
from nltk.probability import FreqDist
#
# Assign URL of the web page to be processed
#
url = "https://edition.cnn.com/2020/10/06/politics/donald-trump-coronavirus-white-house-biden/index.html"
#
# Read the HTML from the URL
#
html = request.urlopen(url).read()
#
# Get text (clean html) using BeautifulSoup get_text method
#
raw = BeautifulSoup(html).get_text()
#
# Tokenize or get words
#
tokens = nltk.word_tokenize(raw)
#
# HTML Words
#
htmlwords = ['https', 'http', 'display', 'button', 'hover',
'color', 'background', 'height', 'none', 'target',
'WebPage', 'reload', 'fieldset', 'padding', 'input',
'select', 'textarea', 'html', 'form', 'cursor',
'overflow', 'format', 'italic', 'normal', 'truetype',
'before', 'name', 'label', 'float', 'title', 'arial', 'type',
'block', 'audio', 'inline', 'canvas', 'margin', 'serif', 'menu',
'woff', 'content', 'fixed', 'media', 'position', 'relative', 'hidden',
'width', 'clear', 'body', 'standard', 'expandable', 'helvetica',
'fullwidth', 'embed', 'expandfull', 'fullstandardwidth', 'left', 'middle',
'iframe', 'rgba', 'selected', 'scroll', 'opacity',
'center', 'false', 'right']
#
# Get words meeting criteria such as words having only alphabets,
# words of length > 4 and words not in htmlwords
#
words = [w for w in tokens if w.isalpha() and len(w) > 4 and w.lower() not in htmlwords]
#
# Create NLTK Text instance to use NLTK APIs
#
text = nltk.Text(words)
#
# Create Frequency distribution to see frequency of words
#
freqdist = FreqDist(text)
freqdist.plot(30)
Here is how the frequency distribution would look like for the HTML page retrieved from CNN website. Note that frequency distribution indicates that the page is about politics, Trump etc.
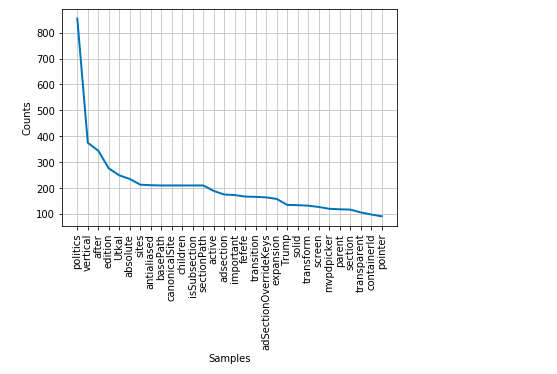
Here is how the cumulative frequency distribution plot would look like. All you need to do is pass cumulative = True to freqdist.plot method.
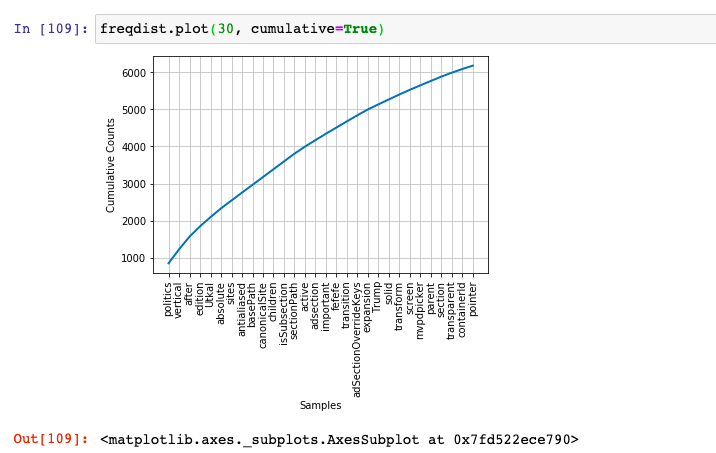
Conclusions
Here is the summary of what you learned in this post regarding extracting text from HTML pages using BeatiffulSoup and processing using NLTK APIs.
- URLLib request APIs can be used to read HTML pages
- BeautifulSoup get_text method can be used to get clean HTML
- NLTK word_tokenize method can be used to create tokens
- NLTK APIs such as FreqDist (nltk.probability) can be used to creat frequency distribution plots.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me