In this post, you will learn about some useful random datasets generators provided by Python Sklearn. There are many methods provided as part of Sklearn.datasets package. In this post, we will take the most common ones such as some of the following which could be used for creating data sets for doing proof-of-concepts solution for regression, classification and clustering machine learning algorithms. As data scientists, you must get familiar with these methods in order to quickly create the datasets for training models using different machine learning algorithms.
- Methods for generating datasets for Classification
- Methods for generating datasets for Regression
Methods for Generating Datasets for Classification
The following is the list of methods which can be used to generate datasets which could be used to train classification models.
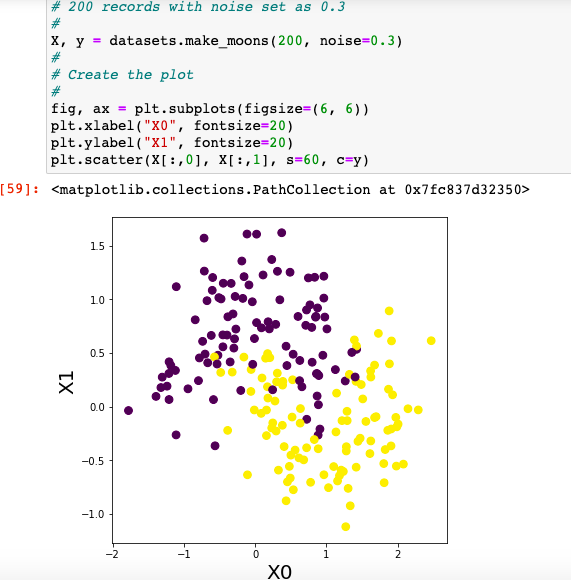
- make_moons & make_circles: If you would like to create a 2-dimensional dataset for creating a binary classifier (binary classification problem), you may want to use the methods such as make_moons or make_circles. A 2-dimensional dataset can be seen as dataset that would represent two features. Thus, in order to create dataset having two features and binary classes, you could either use make_moons or make_circles. Here is the sample code for creating datasets using make_moons method. The dataset created is not linearly separable. You could see the same in the plot as a straight line can not be drawn to separate the two classes.
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
#
# 200 records with noise set as 0.3
#
X, y = datasets.make_moons(200, noise=0.3, random_state=42)
#
# Create the plot
#
fig, ax = plt.subplots(figsize=(6, 6))
plt.xlabel("X0", fontsize=20)
plt.ylabel("X1", fontsize=20)
plt.scatter(X[:,0], X[:,1], s=60, c=y)
Here is the plot for the above dataset.
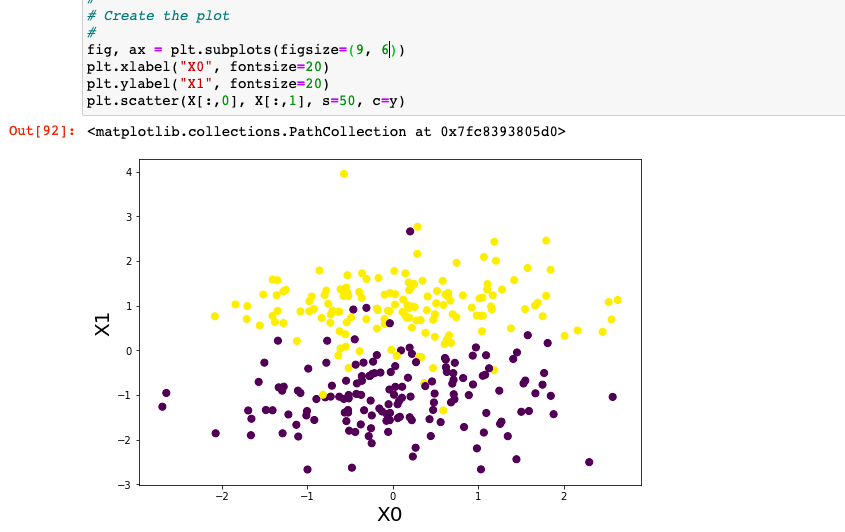
- make_classification: Sklearn.datasets make_classification method is used to generate random datasets which can be used to train classification model. This dataset can have n number of samples specified by parameter n_samples, 2 or more number of features (unlike make_moons or make_circles) specified by n_features, and can be used to train model to classify dataset in 2 or more classes. Other parameters that need to be carefully defined in case you have 3 or more classes / labels are weights and n_clusters_per_class. You can create features of three different types such as informative features (n_informative), redundant features (n_redundant) and duplicate features (n_repeated). They are created in the order of informative first followed by redundant and then the repeated features. Here is a sample code.
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
#
# 200 records, 5 features, number of classes = 3
# weights for each class (proportions of samples assigned to each class)
#
X, y = datasets.make_classification(n_samples=300, n_features=5, n_classes=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.5, 0.3, 0.2], random_state=42)
#
# Create the plot
#
fig, ax = plt.subplots(figsize=(9, 6))
plt.xlabel("X0", fontsize=20)
plt.ylabel("X1", fontsize=20)
plt.scatter(X[:,0], X[:,1], s=50, c=y)
The output of above will show up the following plot:
The data set can as well be used for different purposes such as training model. Here is the sample code which demonstrates how a LogisticRegression model is fit on the random dataset generated using make_classification method:
import numpy as np
from sklearn import datasets
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
#
# 200 records, 5 features, number of classes = 3
# weights for each class (proportions of samples assigned to each class)
#
X, y = datasets.make_classification(n_samples=300, n_features=5, n_classes=2, n_redundant=0,
n_clusters_per_class=1, weights=[0.5, 0.3, 0.2], random_state=42)
#
# Training / test split
#
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
#
# Create pipeline
#
pipeline = make_pipeline(StandardScaler(), LogisticRegression())
#
# Fit the model
#
pipeline.fit(X_train, y_train)
#
# Score the model
#
pipeline.score(X_test, y_test), pipeline.score(X_train, y_train)
Methods for Generating Datasets for Regression
The following is the list of methods which can be used to generate datasets which could be used to train regression models.
- make_regression: Sklearn.datasets make_regression method can be used to generate datasets which could be used to solve train regression models using different regression algorithms. Some of the important attributes which can be fed into make_regression methods are n_samples (number of records), n_features (number of features), n_informative (number of informative features) etc. Here is the sample code which represents how the make_regression method is used to generate random datasets (200) with 5 features while having 2 informative features.
import pandas as pd
import seaborn as sns
#
# Create regression datasets
#
X, y = datasets.make_regression(n_samples=200, n_features=5, n_informative=2, random_state=42)
#
# Create Pandas Dataframe and processes correlation
# You could also use numpy corrcoef method for same
#
df = pd.DataFrame(X)
df.columns = ['ftre1', 'ftre2', 'ftre3', 'ftre4', 'ftre5']
df['target'] = y
#
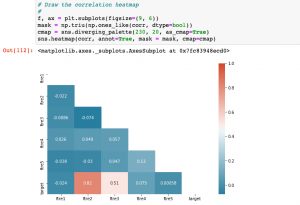
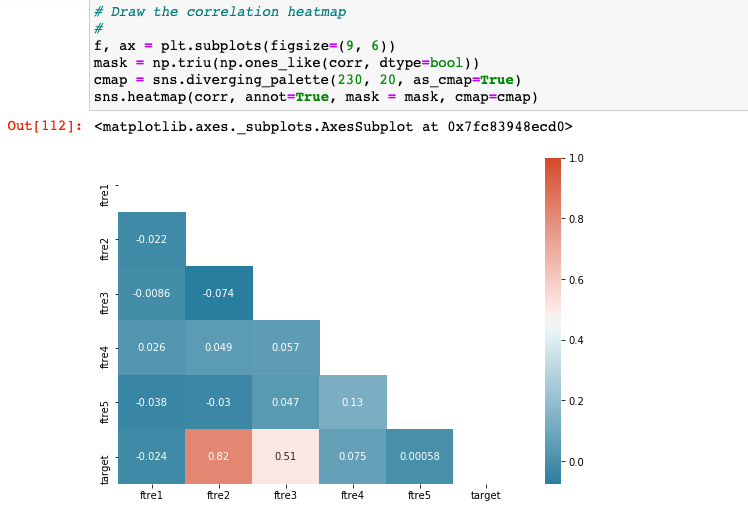
# Determine correlations
#
corr = df.corr()
#
# Draw the correlation heatmap
#
f, ax = plt.subplots(figsize=(9, 6))
mask = np.triu(np.ones_like(corr, dtype=bool))
cmap = sns.diverging_palette(230, 20, as_cmap=True)
sns.heatmap(corr, annot=True, mask = mask, cmap=cmap)
Here is how the correlation heatmap will look like for the randomly generated datasets.
Here is how you could fit a linear regression model using randomly generated regression datasets using make_regression method:
from sklearn.linear_model import LinearRegression
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
#
# Create regression datasets
#
X, y = datasets.make_regression(n_samples=200, n_features=5, n_informative=2, random_state=42)
#
# Training / test split
#
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
#
# Create pipeline
#
pipeline = make_pipeline(StandardScaler(), LinearRegression())
#
# Fit the model
#
pipeline.fit(X_train, y_train)
#
# Score the model
#
pipeline.score(X_test, y_test), pipeline.score(X_train, y_train)
Conclusions
Here is the summary of what you learned in this post in relation to generating random datasets using Python Sklearn methods:
- make_moons or make_circles can be used to create 2-dimensional datasets which could be used for clustering or classification models
- make_classification can be used to generate datasets for fitting classification models.
- make_regression can be used to generate datasets for fitting regression models

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me