In this post, you will get a quick code sample on how to use PDFMiner, a Python library, to extract text from PDF files and perform text analysis. I will be posting several other posts in relation to how to use other Python libraries for extracting text from PDF files.
In this post, the following topic will get covered:
- How to set up PDFMiner
- Python code for extracting text from PDF file using PDFMiner
Setting up PDFMiner
Here is how you would set up PDFMiner.six. You could execute the following command to get set up with PDFMiner while working in Jupyter notebook:
#
# Set up Pdfminer.six in Anaconda Jupyter Notebook
#
!pip install pdfminer.six
Python Code for Extracting Text from PDF file
Here is the Python code which can be used to extract text from PDF file using PDFMiner library. The assumption is that you have already got set up with NLTK. Here is a post on getting set up with NLTK. I have used the PDF file titled a survey on natural language processing and applications in insurance. Pay attention to some of the following in the code given below:
- Pdfminer.high_level extract_text method is used to extract the text
- NLTK.tokenize RegexpTokenizer is used to tokenize the text read from PDF file.
- Method such as tokenize is invoked on the tokenizer instance to get the tokens (words and punctuations)
- NLTK.probability FreqDist is used to create frequency distribution of words in the text read from PDF file.
from nltk.tokenize import RegexpTokenizer
from pdfminer.high_level import extract_text
from nltk.probability import FreqDist
#
# Extract the text from PDF file
#
text = extract_text('/Users/apple/Downloads/2010.00462.pdf')
#
# Create an instance of tokenizer using NLTK ResexpTokenizer
#
tokenizer = RegexpTokenizer('\w+')
#
# Tokenize the text read from PDF
#
tokens = tokenizer.tokenize(text)
#
# Find Frequency Distribution
#
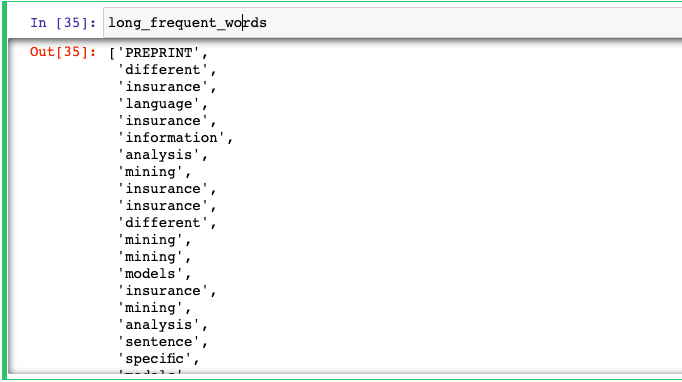
freqdist = FreqDist(tokens)
#
# Find words whose length is greater than 5 and frequency greater than 20
#
long_frequent_words = [words for words in tokens if len(words) > 5 and freqdist[words] > 20]
Executing above code will print all words whose length is greater than 5 and which occurred more than 20 times in the document.
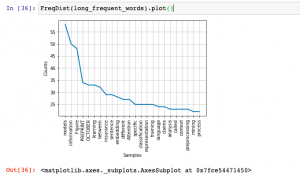
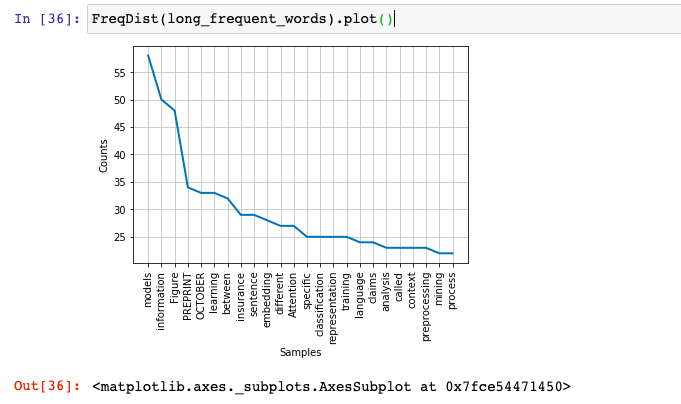
In case you want to create a frequency distribution plot, here is how the code would look like:
#
# Use plot method on instance of FreqDist
#
FreqDist(long_frequent_words).plot()
This is how the frequency distribution plot would look like for words having length greater than 5 and frequency distribution greater than 20 words:
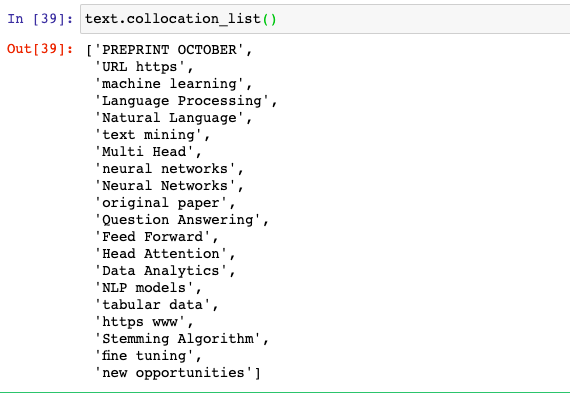
In case you want to find which all words occurred together more often, here is the command you will need to execute. Note the usage of method such as collocation_list(). In case you use method such as collocations(), you will error such as this: Value Error: too many values to unpack (expected 2)
#
# Create NLTK.Text instance using tokens created
# using tokenizer
#
text = nltk.Text(tokens)
#
# Execute collocation_list method on nltk.Text instance
#
text.collocation_list()
This is how the output will look like:
Conclusions
Here is the summary of what you learned about extracting text from PDF file using PDFMiner:
- Set up PDFMiner using !pip install pdfminer.six
- Use extract_text method found in pdfminer.high_level to extract text from the PDF file
- Tokenize the text file using NLTK.tokenize RegexpTokenizer
- Perform operations such as getting frequency distributions of the words, getting words more than some length etc.
- Use method such as collocations or collocation_list to get most frequently sequence of words occurring in the text

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me