In this post, you will learn about how to train neural network for regression machine learning problems using Python Keras. Regression problems are those which are related to predicting numerical continuous value based on input parameters / features. You may want to check out some of the following posts in relation to how to use Keras to train neural network for classification problems:
- Keras – How to train neural network to solve multi-class classification
- Keras – How to use learning curve to select most optimal neural network configuration for training classification model
In this post, the following topics are covered:
- Design Keras neural network architecture for regression
- Keras neural network code for regression
Keras Neural Network Design for Regression
Here are the key aspects of designing neural network for prediction continuous numerical value as part of regression problem.
- The neural network will consist of dense layers or fully connected layers. Fully connected layers are those in which each of the nodes of one layer is connected to every other nodes in the next layer.
- First hidden layer will be configured with input_shape having same value as number of input features.
- The final layer would not need to have activation function set as the expected output or prediction needs to be a continuous numerical value.
- The final layer would need to have just one node.
Keras Neural Network Code Example for Regression
In this section, you will learn about Keras code which will be used to train the neural network for predicting Boston housing price. The code will be described using the following sub-topics:
- Loading the Sklearn Bosting pricing dataset
- Training the Keras neural network
- Evaluating the model accuracy and loss using learning curve
Loading the SKlearn Boston Pricing Dataset
We will use Sklearn Boston Housing pricing data set for training the neural network. Here is the code for loading the dataset. Note the data is has 506 records and 13 features. The output of the following code is ((506, 13), (506,))
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from keras import models
from keras import layers
from keras import optimizers
#
# Load Sklearn Boston Housing Dataset
#
bc = datasets.load_boston()
X = bc.data
y = bc.target
#
# Check the shape of training data
#
X.shape, y.shape
Training the Keras Neural Network
In this section, you will learn about how to set up a neural network and configure it in order to prepare the neural network for training purpose. Pay attention to some of the following covered in the code below:
- An instance of sequential neural network is created. Note that a sequential model is appropriate for a plain stack of layers where each layer has exactly one input tensor and one output tensor.
- The first hidden layer would need to have input_shape set to the value matching the number of features. Note the usage of input_shape in the first hidden layer.
- In every layer, you may need to set number of nodes as first argument, activation function. Keras.layers is used to add the layers to the network.
- The last layer would only require 1 node and no activation function. This is primarily because you want to predict the continuous numerical value. If you set the activation function, the output value would fall under specific range of values determined by the activation function. Since the need to predict the continuous value, no activation function would require to be set.
- Neural network would need to be configured with optimizer function, loss function and metric. For regression problem, the loss function is set to be mean squared error (mse) function which is nothing but the square of the difference between the predictions and the targets. The metric will be mean absolute error (mae) which is noting but the absolute value of the difference between the predictions and the targets.
#
# Set up the network
#
network = models.Sequential()
network.add(layers.Dense(24, activation='relu', input_shape=(13,)))
network.add(layers.Dense(32, activation='relu'))
network.add(layers.Dense(1))
#
# Configure the network with optimizer, loss function and accuracy
#
network.compile(optimizer=optimizers.RMSprop(lr=0.01),
loss='mse',
metrics=['mae'])
#
# Create training and test split
#
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
#
# Fit the network
#
history = network.fit(X_train, y_train,
validation_data=(X_test, y_test),
epochs=18,
batch_size=20)
Evaluating the Model Accuracy and Loss using Learning Curve
The output of the training is a history object which records the loss and accuracy metric after each epoch. The loss and accuracy metric (mae) is measured for training and validation data set after each epoch. The same is plotted to understand aspects such as overfitting and select the most appropriate model. Here is the code for plotting the learning curve.
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
accuracy = history_dict['mae']
val_accuracy = history_dict['val_mae']
epochs = range(1, len(loss_values) + 1)
fig, ax = plt.subplots(1, 2, figsize=(14, 6))
#
# Plot the model accuracy (MAE) vs Epochs
#
ax[0].plot(epochs, accuracy, 'bo', label='Training accuracy')
ax[0].plot(epochs, val_accuracy, 'b', label='Validation accuracy')
ax[0].set_title('Training & Validation Accuracy', fontsize=16)
ax[0].set_xlabel('Epochs', fontsize=16)
ax[0].set_ylabel('Accuracy', fontsize=16)
ax[0].legend()
#
# Plot the loss vs Epochs
#
ax[1].plot(epochs, loss_values, 'bo', label='Training loss')
ax[1].plot(epochs, val_loss_values, 'b', label='Validation loss')
ax[1].set_title('Training & Validation Loss', fontsize=16)
ax[1].set_xlabel('Epochs', fontsize=16)
ax[1].set_ylabel('Loss', fontsize=16)
ax[1].legend()
This is how the plot would look like:
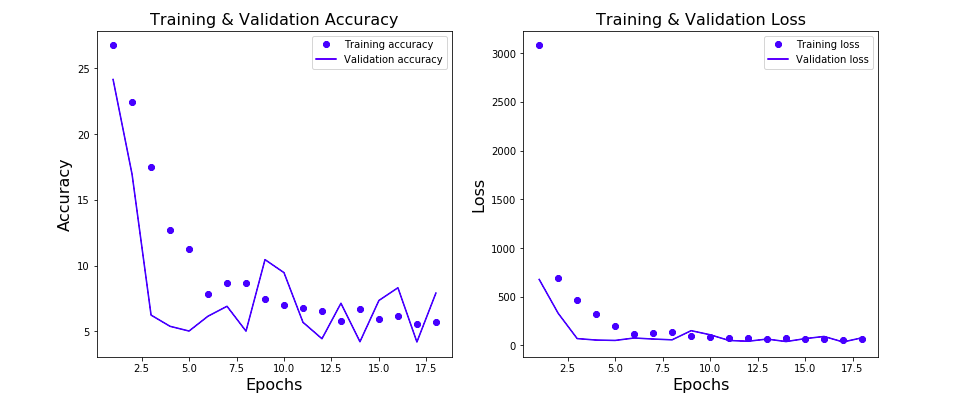
Conclusions
Here is the summary of what you learned in relation to training neural network using Keras for regression problems:
- Keras Sequential neural network can be used to train the neural network
- One or more hidden layers can be used with one or more nodes and associated activation functions.
- The final layer will need to have just one node and no activation function as the prediction need to have continuous numerical value.
- The loss function can be mean squared error (mse)
- The metrics can be mean absolute error (mae)
- Learning curve can be used to select the most optimal design of neural network.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me