Tag Archives: python
Tensor Explained with Python Numpy Examples
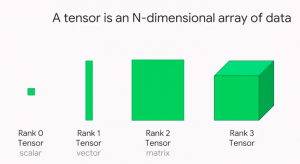
Tensors are a hot topic in the world of data science and machine learning. But what are tensors, and why are they so important? In this post, we will explain the concepts of Tensor using Python Numpy examples with the help of simple explanation. We will also discuss some of the ways that tensors can be used in data science and machine learning. When starting to learn deep learning, you must get a good understanding of the data structure namely tensor as it is used widely as the basic data structure in frameworks such as tensorflow, PyTorch, Keras etc. Stay tuned for more information on tensors! What are tensors, and why are …
Scatter plot Matplotlib Python Example
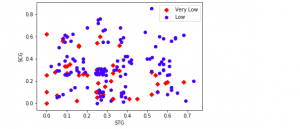
If you’re a data scientist, data analyst or a Python programmer, data visualization is key part of your job. And what better way to visualize all that juicy data than with a scatter plot? Matplotlib is your trusty Python library for creating charts and graphs, and in this blog we’ll show you how to use it to create beautiful scatter plots using examples and with the help of Matplotlib library. So dig into your data set, get coding, and see what insights you can uncover! What is a Scatter Plot? A scatter plot is a type of data visualization that is used to show the relationship between two variables. Scatter …
Softmax Regression Explained with Python Example
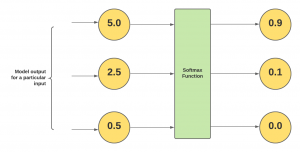
In this post, you will learn about the concepts of what is Softmax regression/function with Python code examples and why do we need them? As data scientist/machine learning enthusiasts, it is very important to understand the concepts of Softmax regression as it helps in understanding the algorithms such as neural networks, multinomial logistic regression, etc in a better manner. Note that the Softmax function is used in various multiclass classification machine learning algorithms such as multinomial logistic regression (thus, also called softmax regression), neural networks, etc. Before getting into the concepts of softmax regression, let’s understand what is softmax function. What’s Softmax function? Simply speaking, the Softmax function converts raw …
Tensor Broadcasting Explained with Examples
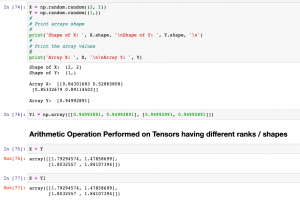
In this post, you will learn about the concepts of Tensor Broadcasting with the help of Python Numpy examples. Recall that Tensor is defined as the container of data (primarily numerical) most fundamental data structure used in Keras and Tensorflow. You may want to check out a related article on Tensor – Tensor explained with Python Numpy examples. Broadcasting of tensor is borrowed from Numpy broadcasting. Broadcasting is a technique used for performing arithmetic operations between Numpy arrays / Tensors having different shapes. In this technique, the following is done: As a first step, expand one or both arrays by copying elements appropriately so that after this transformation, the two tensors have the …
SVM Classifier using Sklearn: Code Examples
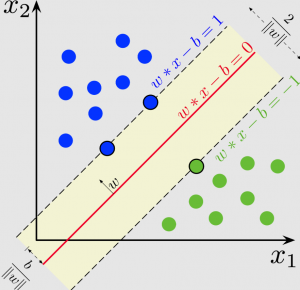
In this post, you will learn about how to train an SVM Classifier using Scikit Learn or SKLearn implementation with the help of code examples/samples. An SVM classifier, or support vector machine classifier, is a type of machine learning algorithm that can be used to analyze and classify data. A support vector machine is a supervised machine learning algorithm that can be used for both classification and regression tasks. The Support vector machine classifier works by finding the hyperplane that maximizes the margin between the two classes. The Support vector machine algorithm is also known as a max-margin classifier. Support vector machine is a powerful tool for machine learning and has been widely used …
Stochastic Gradient Descent Python Example
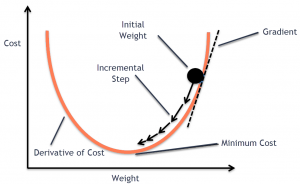
In this post, you will learn the concepts of Stochastic Gradient Descent (SGD) using a Python example. Stochastic gradient descent is an optimization algorithm that is used to optimize the cost function while training machine learning models. The most popular algorithm such as gradient descent takes a long time to converge for large datasets. This is where the variant of gradient descent such as stochastic gradient descent comes into the picture. In order to demonstrate Stochastic gradient descent concepts, the Perceptron machine learning algorithm is used. Recall that Perceptron is also called a single-layer neural network. Before getting into details, let’s quickly understand the concepts of Perceptron and the underlying learning …
Dummy Variables in Regression Models: Python, R
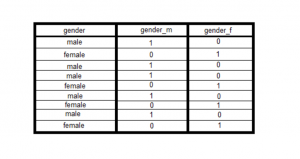
In linear regression, dummy variables are used to represent the categorical variables in the model. There are a few different ways that dummy variables can be created, and we will explore a few of them in this blog post. We will also take a look at some examples to help illustrate how dummy variables work. We will also understand concepts related to the dummy variable trap. By the end of this post, you should have a better understanding of how to use dummy variables in linear regression models. As a data scientist, it is important to understand how to use linear regression and dummy variables. What are dummy variables in …
Correlation Concepts, Matrix & Heatmap using Seaborn
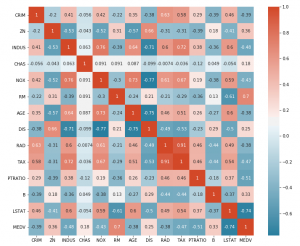
In this blog post, we’ll be discussing correlation concepts, matrix & heatmap using Seaborn. For those of you who aren’t familiar with Seaborn, it’s a library for data visualization in Python. So if you’re looking to up your data visualization game, stay tuned! We’ll start with the basics of correlation and move on to discuss how to create matrices and heatmaps with Seaborn. Let’s get started! Introduction to Correlation Correlation is a statistical measure that expresses the strength of the relationship between two variables. The two main types of correlation are positive and negative. Positive correlation occurs when two variables move in the same direction; as one increases, so do …
Python – Matplotlib Pyplot Plot Example
Matplotlib is a matlab-like plotting library for python. It can create both 2D and 3D plots, with the help of matplotlib pyplot. Matplotlib can be used in interactive environments such as IPython notebook, Matlab, octave, qt-console and wxpython terminal. Matplotlib has a modular architecture with each layer having its own dependencies which makes matplotlib very versatile and allows users to use only those modules they need for their applications. matplotlib provides many hooks that allow developers to customize matplotlib features as they need. Matplotlib architecture has a clear separation between user interface and drawing code which makes it easy to customize or create new interfaces for matplotlib. In this blog …
Elbow Method vs Silhouette Score – Which is Better?
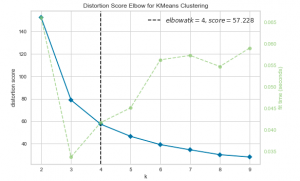
In K-means clustering, elbow method and silhouette analysis or score techniques are used to find the number of clusters in a dataset. The elbow method is used to find the “elbow” point, where adding additional data samples does not change cluster membership much. Silhouette score determines whether there are large gaps between each sample and all other samples within the same cluster or across different clusters. In this post, you will learn about these two different methods to use for finding optimal number of clusters in K-means clustering. Selecting optimal number of clusters is key to applying clustering algorithm to the dataset. As a data scientist, knowing these two techniques to find …
Hello World – Altair Python Install in Jupyter Notebook
This blog post will walk you through the steps needed to install Altair graphical libraries in Jupyter Notebook. For data scientists, Altair visualization library can prove to very useful. In this blog, we’ll look at how to download and install Altair, as well as some examples of using Altair capabilities for data visualization. What is Altair? Altair is a free statistical visualization library that can be used with python (2 or 3). It provides high-quality interactive graphics via an integrated plotting function ́plot() that produces publication-quality figures in a variety of hardcopy formats and interactive environments across platforms. Altair is also easy to learn, with intuitive commands like ‘plot’, ‘hist’ …
Free Python & R Training from Spoken Tutorial Initiative

Many people today are interested in learning Python and R. Are you starting on data science and machine learning and looking to get trained with python and R skills? These two programming languages are very popular because they allow for the analysis of data sets that is not possible with other tools. The training offered at Spoken Tutorial Initiative will introduce you to Python and R, while also providing helpful tips on how to use them effectively. Spoken Tutorials Initiative by IIT Bombay is an initiative of NME (National mission on Education) through Govt. of India, ICT, MoE to promote IT literacy on free and open source software (FOSS) by …
14 Python Automl Frameworks Data Scientists Can Use
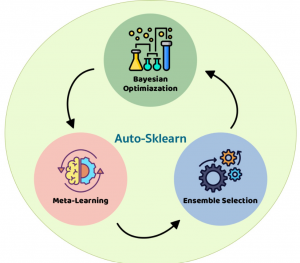
In this post, you will learn about Automated Machine Learning (AutoML) frameworks for Python that can use to train machine learning models. For data scientists, especially beginners, who are unfamiliar with Automl, it is a tool designed to make the process of generating machine learning models in an automated manner, user-friendly, and less time-consuming. The goal of Automl is not just about making it easier for machine learning (ML) developers but also democratizing access to model development. What is AutoML? AutoML refers to automating some or all steps of building machine learning models, including selection and configuration of training data, tuning the performance metric(s), selecting/constructing features, training multiple models, evaluating …
Python Scraper for GoogleNews, Twitter, Reddit & Arxiv

In this post, you will get the Python code for scraping latest and greatest news about any topics from Google News, Twitter, Reddit and Arxiv. This could prove to be very useful for data scientist, machine learning enthusiats to keep track of latest and greatest happening in the field of artificial intelligence. If you are doing some research work, these pieces of code would prove to be very handy to quickly access the information. The code in this post has been worked out in Google Colab notebook. First and foremost, import the necessary Python libraries such as the following for GoogleNews, Twitter and Arxiv. Python Code for mining GoogleNews Here …
Reddit Scraper Code using Python & Reddit API
In this post, you will get Python code sample using which you can search Reddit for specific subreddit posts including hot posts. Reddit API is used in the Python code. This code will be helpful if you quickly want to scrape Reddit for popular posts in the field of machine learning (subreddit – r/machinelearning), data science (subreddit – r/datascience), deep learning (subreddit – r/deeplearning) etc. There will be two steps to be followed to scrape Reddit for popular posts in any specific subreddits. Python code for authentication and authorization Python code for retrieving the popular posts Check the Reddit API documentation page to learn about Reddit APIs. Python code for …
Mining Twitter Data – Python Code Example
In this post, you will learn about how to get started with mining Twitter data. This will be very helpful if you would like to build machine learning models based on NLP techniques. The Python source code used in this post is worked out using Jupyter notebook. The following are key aspects of getting started with Python Twitter APIs. Set up Twitter dev app and Python Twitter package Establish connection with Twitter Twitter API example – location-based trends, user timeline, etc Search twitter by hashtags Setup Twitter Dev App & Python Twitter Package In this section, you will learn about the following two key aspects before you get started with …

I found it very helpful. However the differences are not too understandable for me