Tag Archives: Data Science
Top 5 Data Analytics Methodologies

Here is a list of top 5 data analytics methodologies which can be used to solve different business problems and in a way create business value for any organization: Optimization: Simply speaking, an optimization problem consists of maximizing or minimizing a real function by systematically choosing input values (also termed as decision variables) from within an allowed set and computing the value of the function. An optimization problem consists of three things: A. Objective function B. Decision variables C. Constraint functions (this is optional) Linear / Non-linear programming with constrained / unconstrained optimization Linear programming with constrained optimization Objective function and one or more constraint functions are linear with decision variables as continuous variables Linear programming with unconstrained optimization Objective function …
Contract Management Use Cases for Machine Learning

This post briefly represent the contract management use cases which could be solved using machine learning / data science. These use cases can also be termed as predictive analytics use cases. This can be useful for procurement business functions in any manufacturing companies which require to procure raw materials from different suppliers across different geographic locations. The following are some of the examples of industry where these use cases and related machine learning techniques can be useful. Pharmaceutical Airlines Food Transport Key Analytics Questions One must understand the business value which could be created using predictive analytics use cases listed later in this post. One must remember that one must start with questions …
Deep Learning – Learning Feature Representations
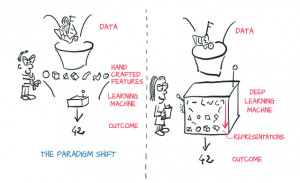
In this post, you learn about what is deep learning with a focus on feature engineering. Here is a quick diagram which represents the idea behind deep learning that Deep learning is about learning features in an automatic manner while optimizing the algorithm. The above diagram is taken from the book, Deep learning with Pytorch. One could learn one of the key differences between training models using machine learning and deep learning algorithms. With machine learning models, one need to engineer features (called as feature engineering) from the data (also called as representations) and feed these features in machine learning algorithms to train one or more models. The model performance …
Machine Learning Models Evaluation Infographics
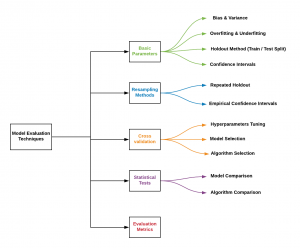
In this post, you will get an access to a self-explanatory infographics / diagram representing different aspects / techniques which need to be considered while doing machine learning model evaluation. Here is the infographics: In the above diagram, you will notice that the following needs to be considered once the model is trained. This is required to be done to select one model out of many models which get trained. Basic parameters: The following need to be considered for evaluating the model: Bias & variance Overfitting & underfitting Holdout method Confidence intervals Resampling methods: The following techniques need to be adopted for evaluating models: Repeated holdout Empirical confidence intervals Cross-validation: Cross …
Python – How to Plot Learning Curves of Classifier
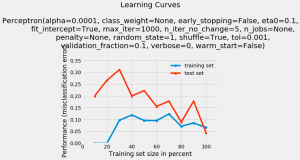
In this post, you will learn a technique using which you could plot the learning curve of a machine learning classification model. As a data scientist, you will find the Python code example very handy. In this post, the plot_learning_curves class of mlxtend.plotting module from mlxtend package is used. This package is created by Dr. Sebastian Raschka. Lets train a Perceptron model using iris data from sklearn.datasets. The accuracy of the model comes out to be 0.956 or 95.6%. Next, we will want to see how did the learning go. In order to do that, we will use plot_learning_curves class of mlxtend.plotting module. Here is a post on how to install mlxtend with Anaconda. The following …
Infographics for Model & Algorithm Selection & Evaluation
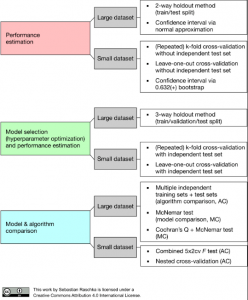
This is a short post created for quick reference on techniques which could be used for model evaluation & selection and model and algorithm comparision. This would be very helpful for those aspiring data scientists beginning to learn machine learning or those with advanced data science skills as well. The image has been taken from this blog, Comparing the performance of machine learning models and algorithms using statistical tests and nested cross-validation authored by Dr. Sebastian Raschka The above diagram provides prescription for what needs to be done in each of the following areas with small and large dataset. Very helpful, indeed. Model evaluation Model selection Model and algorithm comparison …
Feature Scaling & Stratification for Model Performance (Python)
In this post, you will learn about how to improve machine learning models performance using techniques such as feature scaling and stratification. The following topics are covered in this post. The concepts have been explained using Python code samples. What is feature scaling and why one needs to do it? What is stratification? Training Perceptron model without feature scaling and stratification Training Perceptron model with feature scaling Training Perceptron model with feature scaling and stratification What is Feature Scaling and Why is it needed? Feature scaling is a technique of standardizing the features present in the data in a fixed range. This is done when data consists of features of varying …
How to use Sklearn Datasets For Machine Learning
In this post, you wil learn about how to use Sklearn datasets for training machine learning models. Here is a list of different types of datasets which are available as part of sklearn.datasets Iris (Iris plant datasets used – Classification) Boston (Boston house prices – Regression) Wine (Wine recognition set – Classification) Breast Cancer (Breast cancer wisconsin diagnostic – Classification) Digits (Optical recognition of handwritten digits dataset – Classification) Linnerud (Linnerrud dataset – Classification) Diabetes (Diabetes – Regression) The following command could help you load any of the datasets: All of the datasets come with the following and are intended for use with supervised learning: Data (to be used for …
Python – How to install mlxtend in Anaconda
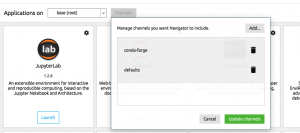
In this post, you will quickly learn about how to install mlxtend python package while you are working with Anaconda Jupyter Notebook. Mlxtend (machine learning extensions) is a Python library of useful tools for the day-to-day data science tasks. This library is created by Dr. Sebastian Raschka, an Assistant Professor of Statistics at the University of Wisconsin-Madison focusing on deep learning and machine learning research. Here is the instruction for installing within your Anaconda. Add a channel namely conda-forge by clicking on Channels button and then Add button. Open a command prompt and execute the following command: conda install mlxtend –channel Conda-forge Once installed, launch a Jupyter Notebook and try importing the following. This should work …
Python DataFrame – Assign New Labels to Columns
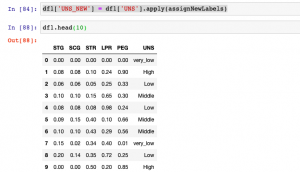
In this post, you will get a code sample related to how to assign new labels to columns in python programming while training machine learning models. This is going to be very helpful when working with classification machine learning problem. Many a time the labels for response or dependent variable are in text format and all one wants is to assign a number such as 0, 1, 2 etc instead of text labels. Beginner-level data scientists will find this code very handy. We will look at the code for the dataset as represented in the diagram below: In the above code, you will see that class labels are named as very_low, Low, High, Middle …
Java Implementation for Rosenblatt Perceptron
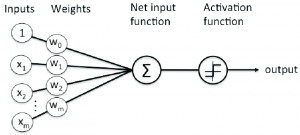
In this post, you will learn about Java implementation for Rosenblatt Perceptron. Rosenblatt Perceptron is the most simplistic implementation of neural network. It is also called as single-layer neural network. The following diagram represents the Rosenblatt Perceptron: The following represents key aspect of the implementation which is described in this post: Method for calculating “Net Input“ Activation function as unit step function Prediction method Fitting the model Calculating the training & test error Method for calculating “Net Input” Net input is weighted sum of input features. The following represents the mathematical formula: $$Z = {w_0}{x_0} + {w_1}{x_1} + {w_2}{x_2} + … + {w_n}{x_n}$$ In the above equation, w0, w1, w2, …
Difference between Adaline and Logistic Regression
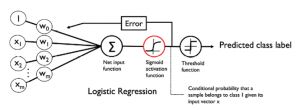
In this post, you will understand the key differences between Adaline (Adaptive Linear Neuron) and Logistic Regression. Activation function Cost function Difference in Activation Function The primary difference is the activation function. In Adaline, the activation function is called as linear activation function while in logistic regression, the activation function is called as sigmoid activation function. The diagram below represents the activation functions for Adaline. The activation function for Adaline, also called as linear activation function, is the identity function which can be represented as the following: $$\phi(W^TX) = W^TX$$ The diagram below represents the activation functions for Logistic Regression. The activation function for Logistic Regression, also called as sigmoid activation function, is …
Logistic Regression: Sigmoid Function Python Code
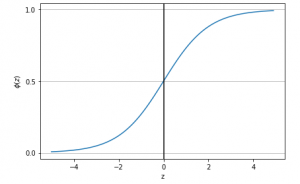
In this post, you will learn about the following: How to represent the probability that an event will take place with the asssociated features (attributes / independent features) Sigmoid function python code Probability as Sigmoid Function The below is the Logit Function code representing association between the probability that an event will occur and independent features. $$Logit Function = \log(\frac{P}{(1-P)}) = {w_0} + {w_1}{x_1} + {w_2}{x_2} + …. + {w_n}{x_n}$$ $$Logit Function = \log(\frac{P}{(1-P)}) = W^TX$$ $$P = \frac{1}{1 + e^-W^TX}$$ The above equation can be called as sigmoid function. Python Code for Sigmoid Function Executing the above code would result in the following plot: Pay attention to some of the …
Three Key Challenges of Machine Learning Models
In this post, you will learn about the three most important challenges or guiding principles that could be used while you are building machine learning models. The three key challenges which could be adopted while training machine learning models are following: The conflict between simplicity and accuracy Dimensionality – Curse or Blessing? The multiplicity of good models The Conflict between Simplicity and Accuracy Before starting on working for training one or more machine learning models, one would need to decide whether one would like to go for simple model or one would want to focus on model accuracy. The simplicity of models could be achieved by using algorithms which help …
Hypergeometric Distribution Explained with 10+ Examples
In this post, we will learn Hypergeometric distribution with 10+ examples. The following topics will be covered in this post: What is Hypergeometric Distribution? 10+ Examples of Hypergeometric Distribution If you are an aspiring data scientist looking forward to learning/understand the binomial distribution in a better manner, this post might be very helpful. The Binomial distribution can be considered as a very good approximation of the hypergeometric distribution as long as the sample consists of 5% or less of the population. One would need a good understanding of binomial distribution in order to understand the hypergeometric distribution in a great manner. I would recommend you take a look at some of my related posts on …
Binomial Distribution with Python Code Examples
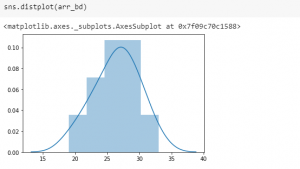
In this code, you will learn code examples, written with Python Numpy package, related to the binomial distribution. You may want to check out the post, Binomial Distribution explained with 10+ examples to get an understanding of Binomial distribution with the help of several examples. All of the examples could be tried with code samples given in this post. Here are the instructions: Load the Numpy package: First and foremost, load the Numpy and Seaborn library Code Syntax – np.random.binomial(n, p, size=1): The code np.random.binomial(n, p, size=1) will be used to print the number of successes that will happen in one (size=1) experiment comprising of n number of trials with probability/proportion of success being p. Tossing a …

I found it very helpful. However the differences are not too understandable for me