In this post, you will learn a technique using which you could plot the learning curve of a machine learning classification model. As a data scientist, you will find the Python code example very handy.
In this post, the plot_learning_curves class of mlxtend.plotting module from mlxtend package is used. This package is created by Dr. Sebastian Raschka.
Lets train a Perceptron model using iris data from sklearn.datasets.
# Load the packages
import numpy as np
import pandas as pd
import Matplotlib.pyplot as plt
from sklearn.linear_model import Perceptron
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn import datasets
# Load the datasets
#
iris = datasets.load_iris()
X = iris.data
Y = iris.target
# Create training / test split; Note the stratification
#
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=1, stratify=Y)
# Perform feature scaling
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
# Fit / train the model
prcptrn = Perceptron(eta0=0.1, random_state=1)
prcptrn.fit(X_train_std, Y_train)
# Check the accuracy of the model
Y_predict_std = prcptrn.predict(X_test_std)
print("Accuracy Score %.3f" % accuracy_score(Y_test, Y_predict_std))
The accuracy of the model comes out to be 0.956 or 95.6%. Next, we will want to see how did the learning go. In order to do that, we will use plot_learning_curves class of mlxtend.plotting module. Here is a post on how to install mlxtend with Anaconda.
# Load the plot_learning_curves class
from mlxtend.plotting import plot_learning_curves
# Plot the learning curves
plot_learning_curves(X_train_std, Y_train, X_test_std, Y_test, prcptrn)
The following would be output plot of the learning curve:
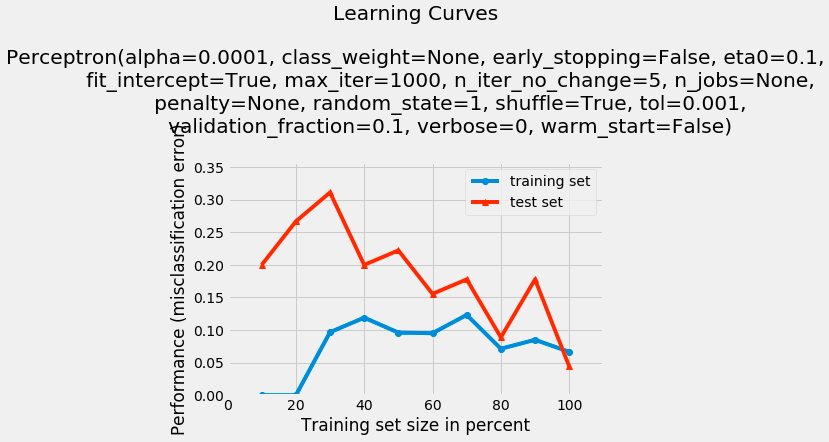
Fig 1. Perceptron Classifier Learning Curve using Python Mlxtend Package
It might be noticed that as the training set size increases, the model performance increases in terms of decrease in number of misclassification.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me