Category Archives: Python
Data Analytics for Car Dealers: Actionable Insights
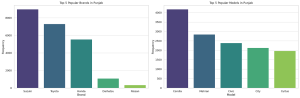
Are you starting a car dealership and wondering how to leverage data to make informed business decisions? In today’s data-driven world, analytics can be the difference between a thriving business and a failing one. This blog aims to provide actionable insights for car dealers, especially those starting new car dealer business, to excel in various business aspects. I will cover inventory management, pricing strategy, marketing and sales, customer service, and risk mitigation, all backed by data analytics. I will continue to update this blog with more methods in time to come. The data used for analysis can be found on the Kaggle.com – Ultimate Car Price Prediction Dataset. First and …
Chi-square test – Formula, Concepts, Examples
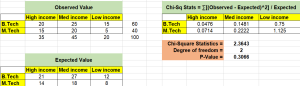
The Pearson’s Chi-square (χ2) test is a statistical test used to determine whether the distribution of observed data is consistent with the distribution of data expected under a particular hypothesis. The Chi-square test can be used to compare or evaluate the independence of two distributions, or to assess the goodness of fit of a given distribution to observed data. In this blog post, we will discuss different types of Chi-square tests, the concepts behind them, and how to perform them using Python / R. As data scientists, it is important to have a strong understanding of the Chi-square test so that we can use it to make informed decisions about …
Find Topics of Text Clustering: Python Examples
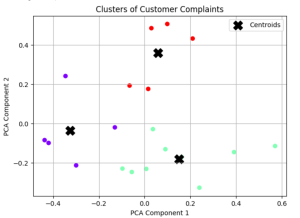
Have you ever clustered a collection of texts and wondered what predominant topics underlie each group? How can you pinpoint the essence of each cluster comprising of large volume of words? Is there a way to succinctly represent the core topic of each cluster using Python? Text clustering is a powerful technique in natural language processing (NLP) that groups documents into clusters based on their content. Once you’ve clustered your data, a natural follow-up question arises: “What are these clusters about?” In this article, we’ll discuss two different methods to find the dominant topics of text clusters using Python. Meanwhile, check out my post on text clustering – Text Clustering …
OpenAI Python API Example for NLP Tasks

Ever wondered how you can leverage the power of OpenAI’s GPT-3 and GPT-3.5 (from Jan 2024 onwards) directly in your Python application? Are you curious about generating human-like text with just a few lines of code? This blog post will walk you through an example Python code snippet that utilizes OpenAI’s Python API for different NLP tasks such as text generation. Check out my other post on how to use Langchain framework for text generation using OpenAI GPT models. OpenAI Python APIs The OpenAI Python API is an interface that allows you to interact with OpenAI’s language models, including their GPT-3 model. The following are different popular models that you …
LLM Chain OpenAI Python Example
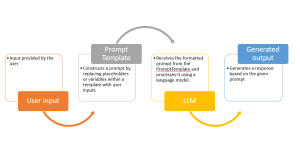
Have you ever wondered how to fully utilize large language models (LLMs) in our natural language processing (NLP) applications, like we do with ChatGPT? Would you not want to create an application such as ChatGPT where you write some prompt and it gives you back output such as text generation or summarization. While learning to make a direct API call to an OpenAI LLMs is a great start, we can build full fledged applications serving our end user needs. And, building prompts that adapt to user input dynamically is one of the most important aspect of an LLM app. That’s where LangChain, a powerful framework, comes in. In this blog, …
Langchain ChatGPT Hello World Python Example
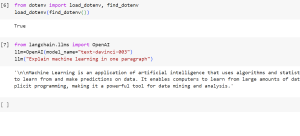
Have you ever wondered how to build applications that not only utilize large language models (LLMs) but are also capable of interacting with their environment and connecting to other data sources. If so, then LangChain is the answer! In this blog, we will learn about what is LangChain, what are its key aspects, how does it work. We will also quickly review the concepts of prompt, tokens and temperature when using the OpenAI API. We will the learn about creating a ‘Hello World’ Python program using LangChain and OpenAI’s Large Language Models (LLMs) such as GPT-3 models. What is LangChain Framework? LangChain is a dynamic framework specifically designed for the …
Huggingface Arxiv Dataset: Python Example

Working with large and specific datasets is a common requirement in the field of natural language processing (NLP) and machine learning. The Arxiv dataset, containing metadata such as titles, abstracts, years, and categories of research papers, is an invaluable resource for researchers and data scientists. How can we easily load this dataset and extract the required information? In this blog post, we will explore a Python example using the Hugging Face library to load the Arxiv dataset and extract specific metadata. Python Code for Loading Huggingface Arxiv Dataset The following are the steps to load Hugging face Arxiv dataset using python code: Real-World Application Use Cases: Analyzing Research Papers Imagine …
Autoregressive (AR) Models Python Examples: Time-series Forecasting
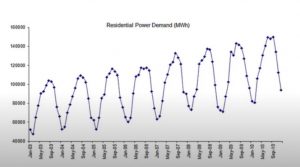
Autoregressive (AR) models, which are used for text generation tasks and time series forecasting, can be employed to predict future values predicated on previous observations. This blog post will provide the concepts of autoregressive (AR) models with Python code examples to demonstrate how you can implement an AR model for time-series forecasting. Note that time-series forecasting is one of the important areas of data science/machine learning. In subsequent blogs, we will take up the topic of how autoregressive models can be used as generative model for text generation tasks. For beginners, time-series forecasting is the process of using a model to predict future values based on previously observed values. Time-series data …
Sign Test Hypothesis: Python Examples, Concepts

Have you ever wanted to make an informed decision, but all you have is a small amount of non-parametric data? In the realm of statistics, we have various tools that enable us to extract valuable insights from such datasets. One of these handy tools is the Sign test, a beautifully simple yet potent method for hypothesis testing. Sign test is a non-parametric test which is often seen as a cousin to the one-sample t-test, allows us to infer information about a whole population based on a small, paired sample. It is particularly useful when dealing with dichotomous data – Data that can have only two possible outcomes. In this blog …
K-Means Clustering Concepts & Python Example
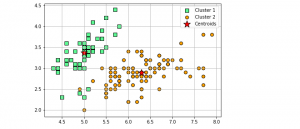
Clustering is a popular unsupervised machine learning technique used in data analysis to group similar data points together. The K-Means clustering algorithm is one of the most commonly used clustering algorithms due to its simplicity, efficiency, and effectiveness on a wide range of datasets. In K-Means clustering, the goal is to divide a given dataset into K clusters, where each data point belongs to the cluster with the nearest mean value. The algorithm works by iteratively updating the cluster centroids until convergence is achieved. In this post, you will learn about K-Means clustering concepts with the help of fitting a K-Means model using Python Sklearn KMeans clustering implementation. You will …
Kruskal Wallis H Test Formula, Python Example

Ever wondered how to find out if different groups of people have different preferences? Maybe you’re a marketer trying to understand if different age groups prefer different features in a smartphone. Or perhaps you’re a public policy researcher, trying to determine if different neighborhoods are equally satisfied with their local services. How do you go about answering these questions, especially when the data doesn’t follow the typical bell-shaped curve or normal distribution? The solution lies in the Kruskal-Wallis H Test! This is a non-parametric test that helps to compare more than two independent groups and it comes in really handy when the data is not bell-shaped curve data or not …
Weighted Regression Model Python Examples
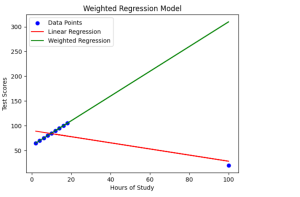
Have you ever wondered how regression models can be enhanced to provide more accurate predictions, even in the presence of outliers or data points with varying significance? Enter weighted regression machine learning models, an approach that assigns weights to data points, allowing for precise adjustments and improvements in prediction accuracy. In this blog post, we will learn about the concepts of weighted regression models with the help of examples while demonstrating with the help of Python implementation. Traditional linear regression is a widely-used technique, but it may struggle when faced with outliers or situations where some data points carry more weight than others. However, weighted regression models help overcome these …
Spearman Correlation Coefficient: Formula, Examples
Have you ever wondered how you might determine the relationship between two sets of data that aren’t necessarily linear, or perhaps don’t adhere to the assumptions of other correlation measures? Enter the Spearman Rank Correlation Coefficient, a non-parametric statistic that offers robust insights into the monotonic relationship between two variables – perfect for dealing with ranked variables or exploring potential relationships in a new, exploratory dataset. In this blog post, we will learn the concepts of Spearman correlation coefficient with the help of Python code examples. Understanding the concept can prove to be very helpful for data scientists. Whether you’re exploring associations in marketing data, results from a customer satisfaction …
Heteroskedasticity in Regression Models: Examples
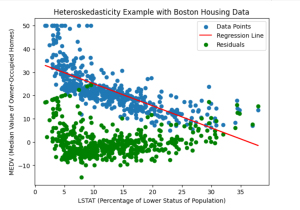
Have you ever encountered data that exhibits varying patterns of dispersion and wondered how it might impact your regression models? The varying patterns of dispersion represents the essence of heteroskedasticity – the phenomenon where the spread or variability of the residuals / errors in a regression model changes across different levels or values of the independent variables. As data scientists, understanding the concept of heteroskedasticity is crucial for robust and accurate analyses. In this blog, we delve into the intriguing world of heteroskedasticity in regression models and explore its implications through real-world examples. What’s heteroskedasticity and why learn this concept? Heteroskedasticity refers to a statistical phenomenon observed in regression analysis, …
Matplotlib Bar Chart Python / Pandas Examples
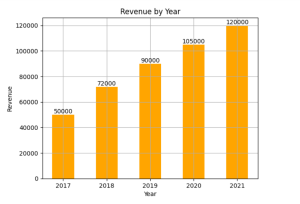
Are you looking to learn how to create bar charts / bar plots / bar graph using the combination of Matplotlib and Pandas in Python? Bar charts are one of the most commonly used visualizations in data analysis, enabling us to present categorical data in a visually appealing and intuitive manner. Whether you’re a beginner data scientist or an intermediate-level practitioner seeking to enhance your visualization skills, this blog will provide you with practical examples and hands-on guidance to create compelling bar charts / bar plots using Matplotlib libraries in Python. You will also learn how to leverage the data manipulation capabilities of Pandas to prepare the data for visualization, …
One-hot Encoding Concepts & Python Examples
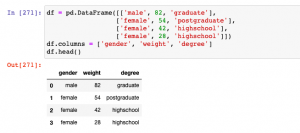
Have you ever encountered categorical variables in your data analysis or machine learning projects? These variables represent discrete qualities or characteristics, such as colors, genders, or types of products. While numerical variables can be directly used as inputs for machine learning algorithms, categorical variables require a different approach. One common technique used to convert categorical variables into a numerical representation is called one-hot encoding, also known as dummy encoding. When working with machine learning algorithms, categorical variables need to be transformed into a numerical representation to be effectively used as inputs. This is where one-hot encoding comes to rescue. In this post, you will learn about One-hot Encoding concepts and …
I found it very helpful. However the differences are not too understandable for me