Tag Archives: spark
Spark – How does Apache Spark Work?
This blog represents concepts on how does apache spark work with the help of diagrams. Following are some of the key aspects in relation with Apache Spark which is described in this blog: Apache Spark – basic concepts Apache Spark with YARN & HDFS/HBase Apache Spark with Mesos & HDFS/HBase Apache Spark – Basic Concepts The following represents basic concepts in relation with Spark: Apache Spark with YARN & HBase/HDFS Following are some of the key architectural building blocks representing how does Apache Spark work with YARN and HDFS/HBase. Spark driver program runs on client node. YARN is used as cluster manager. As part of YARN setup, there would be multiple nodes running …
When a Spark application starts on Spark Standalone Cluster?
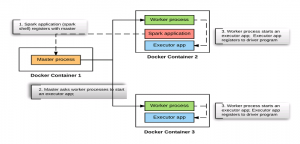
This article represents detailed view on what happens when a driver program (spark application) is started on one of the worker node when working with Spark standalone cluster. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key points described later in this article: Snapshot into what happens when Spark Standalone Cluster Starts? Snapshot into what happens when a spark application (Spark Shell) starts on one of the worker nodes? Snapshot into what happens when a spark application (Spark Shell) stops on the worker node? Snapshot into what happens when Spark Standalone Cluster Starts? In our …
Hello World with Apache Spark Standalone Cluster on Docker
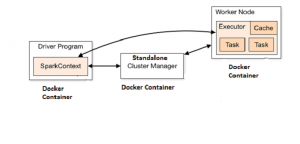
This article presents instructions and code samples for Docker enthusiasts to quickly get started with setting up Apache Spark standalone cluster with Docker containers. Thanks to the owner of this page for putting up the source code which has been used in this article. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. Following are the key points described later in this article: Basic concepts on Apache Spark Cluster Steps to setup the Apache spark standalone cluster Code sample for Setting up Spark Code sample for Docker-compose to start the cluster Code sample for starting the Driver program using Spark …
Dockers – How to Get Started with Spark on Windows
This article represents tips on how to get started with Apache Spark on Windows using Dockers. Please feel free to comment/suggest if I missed to mention one or more important points. Also, sorry for the typos. If you are familiar with Dockers, the instructions below would help you get started with Spark in no time. Download the Spark from https://spark.apache.org/downloads.html page. Remember to select a package type with option such as “Pre-built…”. Once the zipped files are downloaded, unzip the files under the location “C:\Users\<Username>” Build Java8 image and start the container. Follow the instructions on this page, http://vitalflux.com/dockers-how-to-get-started-with-java8-dev-environment/. Once the container is started, go to the folder where you …
I found it very helpful. However the differences are not too understandable for me