Tag Archives: hbase
Spark – How does Apache Spark Work?
This blog represents concepts on how does apache spark work with the help of diagrams. Following are some of the key aspects in relation with Apache Spark which is described in this blog: Apache Spark – basic concepts Apache Spark with YARN & HDFS/HBase Apache Spark with Mesos & HDFS/HBase Apache Spark – Basic Concepts The following represents basic concepts in relation with Spark: Apache Spark with YARN & HBase/HDFS Following are some of the key architectural building blocks representing how does Apache Spark work with YARN and HDFS/HBase. Spark driver program runs on client node. YARN is used as cluster manager. As part of YARN setup, there would be multiple nodes running …
HBase Architecture Components for Beginners
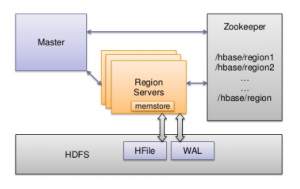
This blog represents high-level concepts on HBase architecture components. Following diagram represents the same: HBase Architecture Components – Key Building Blocks Following diagram represents the same: Pay attention to some of the following in relation to above diagram: HMaster: Responsible for coordinating the region servers including assigning regions on startup as well as recovery, and, monitoring region servers using Zookeeper Region Servers: Manages one or more regions Zookeeper: Zookeeper is used as a distributed coordination service for maintaining the server state of the cluster. Regions: Records in HBase tables are split horizontally based on the key range. Each of these splits can be called as Regions. A region contains all rows in …
I found it very helpful. However the differences are not too understandable for me