This blog represents concepts on how does apache spark work with the help of diagrams. Following are some of the key aspects in relation with Apache Spark which is described in this blog:
- Apache Spark – basic concepts
- Apache Spark with YARN & HDFS/HBase
- Apache Spark with Mesos & HDFS/HBase
Apache Spark – Basic Concepts
The following represents basic concepts in relation with Spark:
Apache Spark with YARN & HBase/HDFS
Following are some of the key architectural building blocks representing how does Apache Spark work with YARN and HDFS/HBase.
- Spark driver program runs on client node.
- YARN is used as cluster manager. As part of YARN setup, there would be multiple nodes running as YARN resource manager with one of them acting as a leader (managed by Zookeeper). Each worker node runs a process such as YARN node manager.
- HDFS (data node) or HBase is used as data source for Spark executor programs.
Following diagram represents the same:
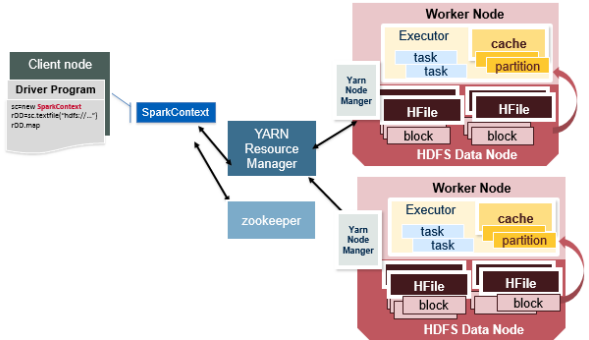
Figure 1. Apache Spark with YARN & HDFS, HBase (image credit: MapR blog)
In the above diagram, pay attention to some of the following:
- There is a driver program which comprises of SparkContext object.
- YARN is used as a cluster manager. YARN consists of a resource manager which is used to launch tasks on the worker node via its agent such as node manager.
- Each worker node runs an Executor program which executes tasks as and when it receives from the driver program via the cluster manager such as YARN.
- The Spark executor program reads the partition data either from HDFS or HBase whichever is set up on the executor nodes.
- In case of HBase, note how HFile is stored as part of HDFS data node. HFile is associated with the index which gets loaded as Block Cache.
For details, check this page, Getting Started with Spark Web UI.
Apache Spark with Mesos & HBase/HDFS
Following enlists the key architectural building blocks of Apache Spark setup with Mesos & HDFS:
- Spark driver program runs on client node
- Mesos is used as Cluster manager. There is a set of Mesos master nodes with one of them acting as a leader and used to delegate tasks to Executor program running on Mesos slave nodes
- Spark Executor program runs on Mesos slave nodes.
- HDFS is used as data source for Spark executor program.
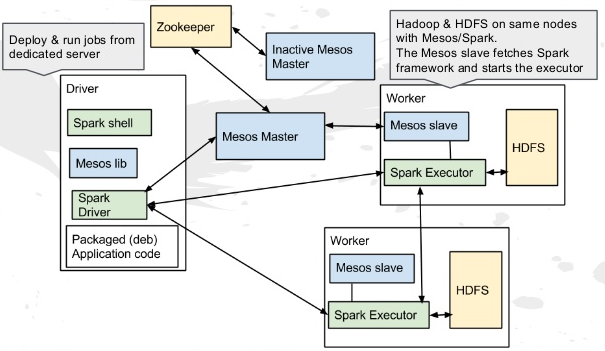
Figure 2. Apache Spark with Mesos & HDFS/HBase (image credit: Apache Spark at Viadeo)
Pay attention to some of the following in above diagram:
- Spark driver program uses Mesos master (Cluster manager) to launch tasks on Mesos slave nodes (worker nodes) running Spark executor programs.
- Spark executor programs read partition data from HDFS (data node) and write the data to HDFS.
- HBase can as well be used in place of HDFS. However, HBase uses HDFS to persist HFile and index data.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me