Category Archives: Data Science
Business Analytics Team Structure: Roles/ Responsibilities
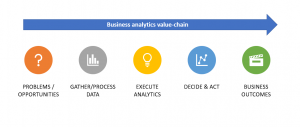
Business analytics is a business function that has been around for years, but it’s only recently gained traction as one of the most important business functions. Organizations are now realizing how business analytics can help them increase revenue and improve business operations. But before you bring on a business analytics team, you need to determine if your company needs full-time or part-time team members or both. It might seem logical to hire full-time staff members just because they’re in demand, but this isn’t always necessary. If your business operates without any external data sets and doesn’t have complex reporting and advanced analytics needs then it may be more cost-effective to …
Linear Regression Interview Questions for Data Scientists
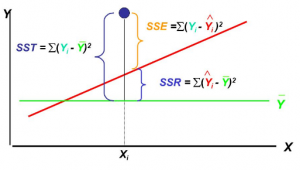
This page lists down 40 regression (linear/univariate, multiple/multilinear/multivariate) interview questions (in form of objective questions) which may prove to be helpful for Data Scientists / Machine Learning enthusiasts. Those appearing for interviews for machine learning/data scientist freshers/intern/beginners positions would also find these questions very helpful and handy enough to quickly brush up / check your knowledge and prepare accordingly. Practice Tests on Regression Analysis These interview questions are split into four different practice tests with questions and answers which can be found on following page: Linear, Multiple regression interview questions and answers – Set 1 Linear, Multiple regression interview questions and answers – Set 2 Linear, Multiple regression interview questions …
Most In-Demand Skills for Data Scientists in 2022
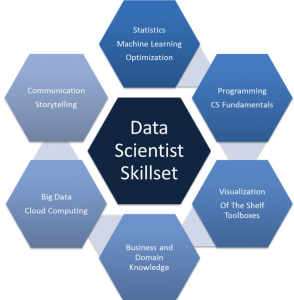
The data science field is growing rapidly and data scientists are in high demand. If you want to enter this field, it’s important that you have the right skills. In this blog post, we’ll explore the most in-demand skills of data scientist employers are looking for the most and how to develop these skills so that you can find a job as a data scientist. Strong knowledge and experience with Statistical/ML methods: Strong familiarity with statistical concepts such as probability distributions (e.g., normal distribution), concepts of hypothesis testing, regression analysis, etc is essential for becoming a great data scientist. One of the most important ask for a data scientist is …
One-sample Z-test for Means: Formula & Examples
One sample Z-test for means is one of the statistical techniques used for testing hypothesis related to whether the sample belongs to a population. As a data scientist, you must get a good understanding of the z-test and its applications to test the hypothesis for your statistical models. In this blog post, we will discuss the one sample z-test for means and its concepts with an example. You may want to check my post on hypothesis testing titled – Hypothesis testing explained with examples What is One-sample Z-test for Means? Z-test is usually referred to as a 1-sample Z-test for means that is used to test the hypothesis about the …
Z-tests for Hypothesis testing: Formula & Examples
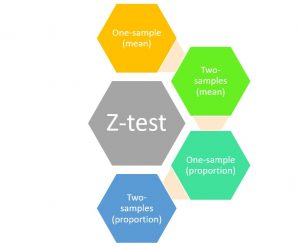
Z-tests are statistical hypothesis testing techniques that are used to determine whether the null hypothesis relating to comparing sample means or proportions with that of population at a given significance level can be rejected or otherwise based on the z-statistics or z-score. As a data scientist, you must get a good understanding of the z-tests and its applications to test the hypothesis for your statistical models. In this blog post, we will discuss an overview of different types of z-tests and related concepts with the help of examples. You may want to check my post on hypothesis testing titled – Hypothesis testing explained with examples What are Z-tests & Z-statistics? …
One sample Z-test for proportion: Formula & Examples

One proportion z-test or one-sample Z-test for proportion is one of the most popular statistical hypothesis tests dealing with one sample proportion. It is used to determine whether or not a hypothesized mean difference between the sample and the population can be rejected by drawing conclusions from sample data. As a data scientist, it is important to be proficient in this type of Z-test and understand how it works. In this blog post, we will learn about how one proportion z-test works with the help of formula and examples. What is one sample Z-test for proportion? A one proportion Z-test is a hypothesis testing technique which is used for testing …
Z-test MCQs with Answers: Interview Questions
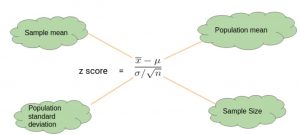
In this blog post, you can test your knowledge about Z-test, Z-statistics and related concepts through multiple choice questions (MCQs) and answers. Getting a good understanding of Z-tests, Z-statistics and Z-distribution is of utmost importance for data scientists at large. The following are key concepts around which the MCQs are posted: Z-score or Z-statistics concepts Estimation of population mean and proportion 1-sample Z-test for mean and proportion 2-samples Z-test for mean and proportion Z-test Interview Questions Samples The following is a list of interview questions that you would want to learn: What is Z-score? Explain with an example and formula. What are different types of Z-tests? Explain with formula and …
Different Success / Evaluation Metrics for AI / ML Products

In this post, you will learn about some of the common success metrics that can be used for measuring the success of AI / ML (machine learning) / DS (data science) initiatives / projects / products. If you are one of the AI / ML stakeholders including product managers, you would want to get hold of these metrics in order to apply right metrics in right business use cases. Business leaders do want to know and maximise the return on investments (ROI) from AI / ML investments. Here is the list of success metrics for AI / DS / ML initiatives: Business value metrics / key performance indicators (KPIs): Business …
Null and Alternate hypothesis: Definition & Example
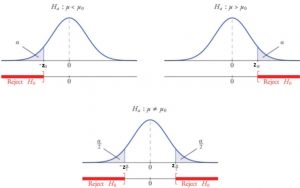
Hypothesis testing is a technique used to determine whether an assumption about the population is true. Null hypothesis and alternate hypothesis are two types of hypotheses that you may hear when conducting this type of test. Having a good understanding about null and alternate hypothesis will help you better design good hypothesis tests and understand their results in a nice manner. It is very important for data scientists to be able to distinguish between null and alternate hypothesis and design hypothesis tests. In this blog post, we will understand the definition and examples of the null and alternate hypothesis. What are different scenarios for hypothesis testing? The following are two …
Warehouse Management & Machine Learning Use Cases

Warehouses are a vital part of the supply chain. Not only do they store products, but warehouses also play a role in shipping and receiving goods. As warehouse operations become more complex, it’s important to use technology to help manage them. Warehouses need to be able to efficiently manage the flow of goods in and out while still making room for new deliveries. Increasingly warehouses are turning to machine learning algorithms as a way to improve warehouse efficiency, reduce costs, and increase warehouse productivity. In this blog post, we will explore different machine learning use cases which can be deployed by warehouse managers to create a positive business impact. Machine …
Normal Distributions Questions and Answers for Interviews
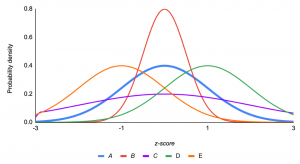
In order to be successful in normal distribution interviews, you need a solid understanding of the normal distribution. This blog post will focus on normal distribution questions and answers that are commonly asked in the data science and statistics interviews. Before jumping into questions and answers, lets quickly understand what normal distribution is. What is normal distribution? A normal distribution is a symmetric, bell-shaped curve that describes the distribution of many types of data. The normal distribution has two parameters, mean and standard deviation. It is important to know these two parameters because they are used to calculate probabilities associated with the normal distribution. The normal curve describes how data …
Level of Significance & Hypothesis Testing
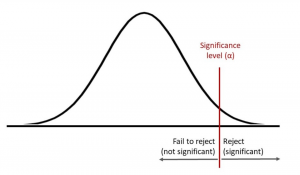
In hypothesis testing, the level of significance is a measure of how confident you can be about rejecting the null hypothesis. This blog post will explore what hypothesis testing is and why understanding significance levels are important for your data science projects. In addition, you will also get to test your knowledge of level of significance towards the end of the blog with the help of quiz. These questions can help you test your understanding and prepare for data science / statistics interviews. Before we look into what level of significance is, let’s quickly understand what is hypothesis testing. What is Hypothesis testing and how is it related to significance …
P-Value & Hypothesis Testing: Examples
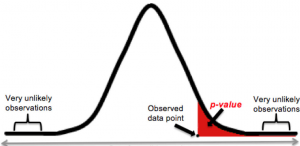
Many describe p-value as the probability that the null hypothesis holds good. That is an incorrect definition. The concept of p-value is understood differently by different people and is considered as one of the most used & abused concepts in statistics, mostly in relation to hypothesis testing. In this blog post, you will learn the P-VALUE concepts with multiple different examples. It is extremely important to get a good understanding of P-value if you are starting to learn data science/machine learning as the concepts of P-value are key to hypothesis testing. Before getting into the description of p-value, let’s quickly go through the hypothesis testing concepts to get a good …
Type I & Type II Errors in Hypothesis Testing: Examples

This article describes Type I and Type II errors made due to incorrect evaluation of the outcome of hypothesis testing, based on a couple of examples such as the person comitting a crime, the house on fire, and Covid-19. You may want to note that it is key to understand type I and type II errors as these concepts will show up when we are evaluating a hypothesis such as those related to machine learning algorithms (linear regression, logistic regression, etc). For example, in the case of linear regression models, the significance value is compared with the p-value and, the null hypothesis that the parameter/coefficient is equal to zero is …
Python – Matplotlib Pyplot Plot Example
Matplotlib is a matlab-like plotting library for python. It can create both 2D and 3D plots, with the help of matplotlib pyplot. Matplotlib can be used in interactive environments such as IPython notebook, Matlab, octave, qt-console and wxpython terminal. Matplotlib has a modular architecture with each layer having its own dependencies which makes matplotlib very versatile and allows users to use only those modules they need for their applications. matplotlib provides many hooks that allow developers to customize matplotlib features as they need. Matplotlib architecture has a clear separation between user interface and drawing code which makes it easy to customize or create new interfaces for matplotlib. In this blog …
Survival Analysis Modeling for Customer Churn
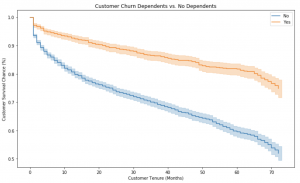
Customer churn is a prevalent problem for many businesses. It can happen in several different ways, such as when customers stop using the product, or when they leave because of an issue with customer service. This blog post will explore survival analysis modeling and what it can do to help you better understand customer churn problems. First, we will discuss survival analysis itself and why it is beneficial for analyzing customer behavior. Then we will show some examples on how survival analysis has been used to analyze customer churn problems. As data scientists, it will be good to familiarize ourselves with survival analysis, as it is a popular modeling technique …
I found it very helpful. However the differences are not too understandable for me