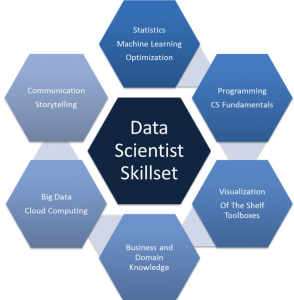
The data science field is growing rapidly and data scientists are in high demand. If you want to enter this field, it’s important that you have the right skills. In this blog post, we’ll explore the most in-demand skills of data scientist employers are looking for the most and how to develop these skills so that you can find a job as a data scientist.
- Strong knowledge and experience with Statistical/ML methods: Strong familiarity with statistical concepts such as probability distributions (e.g., normal distribution), concepts of hypothesis testing, regression analysis, etc is essential for becoming a great data scientist. One of the most important ask for a data scientist is his/her knowledge in hypothesis formulation and hypothesis testing techniques. This is one of the most neglected skills found with the data scientists. Reasoning by first principles, the most important skill is to understand the nuances of acquiring knowledge about a thing based on concepts of Epistemology. In simpler words, the idea is to know about the truth of a thing or a problem. For example, if it is claimed that there is a correlation between the salary of a person and his education, the idea is to know this truth based on hypothesis testing and not just accept it as it is. Another example is considering the truth about the data set used for machine learning models. The truth is that the any amount of data should only be treated as a sample which means that the best model trained using that data set is only a hypothesis. Here is my related post titled – Hypothesis testing explained with examples. Data scientists are required to model data, assess the suitability of data for analysis, develop mathematical / machine learning models that capture important features in data, and design algorithms to discover patterns.
- Strong programming skills: Data scientists need to be able to program their data science tools. This means that you should have a strong foundation in Python, R, Julia etc and understand how to perform data manipulation tasks with these languages, as well as the ability to create new functions on your own when needed. It is helpful to be proficient in at least one programming language to take advantage of data science resources. It is also required in order to run data analysis, data exploration, and machine learning algorithms on your laptop or a cluster when needed. One would want to get proficiency working with IDEs such as RStudio and Jupyter Notebook in order to work with R and Python programming. Other options include Kaggle and Google Colab to start working on building models using R & Python.
- Strong data visualization skills: A data scientist should be able to visualize data in a way that is not only helpful for them but also for the business stakeholders and anyone else who might need to understand their work. This can help you gain buy-in from those folks as well as make your job easier by helping you see trends or data outliers that might otherwise go unnoticed. Some common data visualization tools include Density Plots in Python with Matplotlib; Bar Charts in R; Tableau for data visualization; Tableau Public for data visualization.
- Good experience with data science tools: The data scientist should have a working knowledge of data mining, data visualization, and other data analysis techniques in order to gain insights from the data sets they are given. Some common tools used by data scientists include Jupyter for data science with Python, RStudio for data science in R; Python data visualization libraries like Matplotlib and Seaborn.
- Write clean and maintainable code. There are times when this isn’t strictly required (for example, for ad-hoc analyses), but if you’re ever going to re-use or distribute your code, following excellent software development practices will result in far greater productivity. Writing clean Python or R code can seem daunting at first, but there are many data science tutorials that can get you started.
- Basic knowledge of Shells, SSH, and Docker: It is useful to have hands-on experience of these tools to manage data and data-related products. Docker containers are very useful in data science projects because they help in deploying mathematical models in a production environment in a very easy manner.
- Knowledge of cloud ML services: Know your way around one of the cloud platforms such as AWS, Google Cloud Platform (GCP), or Azure. Each of these cloud services provides AI/ML APIs, data storage options, data processing engines, and other services. Understanding how to utilize these platforms’ data science/machine learning services can help you get more out of your data science practice. AWS ML tools & services are the most widely used data science tools.
- Knowledge of data storage options: Data scientists should be aware of the pros and cons associated with different data storage technologies (e.g., SQL, NoSQL) depending on the use cases they are working on. Knowledge about how data is stored can help them design more effective data pipelines or choose appropriate data formats. It is helpful for data scientists to know about data warehouses, data fabric as well as data lake architecture.
- Familiar with data engineering tasks: Data scientists should be familiar with tools like Hive or Pig for data ingestion and ETL (Extract Transform Load) processes; HBase for large-scale storage of semi-structured/unstructured data; HDFS for distributed data storage; data streaming tools like Kafka to process data in real-time. Data scientists should know how data analytics projects would benefit from the Hadoop big data framework. A basic understanding of this will help data scientists choose which data science tools to use for their projects.
- Business domain knowledge: Data scientists need to understand the business domain in a data science project. This helps data scientists understand the data and derive context from it, which in turn leads to better decision-making processes within an organization. In case, he/she does not have a good understanding of the business domain, it is helpful that he/she gets tagged with business analysts or product managers. It is extremely important for data scientists to participate in a business conversation and provide meaningful input on the projects, the questions, and the potential outcomes. Inability to do so may act as a hindrance to building great data products
- Business acumen: In the current scenario, a data scientist needs to acquire skills related to business acumens such as good communication, data storytelling, project management, etc. A data scientist might not be the one to deliver final reports or presentations that are presented to senior staff, but they often play a critical role in gathering requirements from business stakeholders (for example, by interviewing them) as well as communicating results back to those same folks after analysis. A data scientist should be able to show how data science can help a company make more money or save on costs.
- Product mindset: As a data scientist, it is desirable to have a product mindset because data science isn’t only about the data and statistical/ML techniques, it’s about what you can build with data. Being able to see data as a product will help your team understand how to monetize data and make smarter decisions on how they use data for business growth. Great things happen when the Data science toolkit (analysis, experimentation, metrics monitoring, root cause analyses, etc.) is seen as simple means to the end goal of creating a successful product and the end itself. Building data products with a product mindset mean data scientists will be able to more quickly and easily get their data products into the hands of users, which can lead to higher adoption rates for data products.
- Software engineering: It is desirable to have data scientists have a decent knowledge of software engineering skills such as exposing models as API, model deployments, etc. This helps data scientists create data products that are scalable and reusable for future projects. In addition to strong programming skills and knowledge of data science tools, data scientists also need to be familiar with software development best practices such as version control systems (e.g., Git), continuous integration/deployment, and unit testing frameworks.
- MLOps: It is super helpful if data scientists have MLOps skills. MLOps focuses on data management and data science operations, which can include aspects such as versioning data sets to make sure they are accessible for multiple experiments; documentation of models so that other data scientists or data engineers know how a model works and what it does; deploying models into production with the right metrics tracking around errors, etc.
Data science is an ever-evolving field, and data scientists are constantly learning new skills. The most in-demand data science skills for data scientists include knowledge of cloud services, data storage options, business domain knowledge, software engineering, MLOps skillsets – these should be some of the top skill sets you to focus on developing to stay competitive in this industry. Feel free to send your questions or comments.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me