Category Archives: Data Science
Python – How to Create Dictionary using Pandas Series
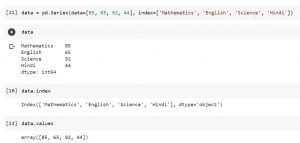
In this post, you will learn about one of the important Pandas fundamental data structure namely Series and how it can be used as a dictionary. It will be useful for beginner data scientist to understand the concept of Pandas Series object. A dictionary is a structure that maps arbitrary keys to a set of arbitrary values. Pandas Series is a one-dimensional array of indexed data. It can be created using a list or an array. Pandas Series can be thought of as a special case of Python dictionary. It is a structure which maps typed keys to a set of typed values. Here are the three different ways in …
Free Online Books – Machine Learning with Python

This post lists down free online books for machine learning with Python. These books covers topiccs related to machine learning, deep learning, and NLP. This post will be updated from time to time as I discover more books. Here are the titles of these books: Python data science handbook Building machine learning systems with Python Deep learning with Python Natural language processing with Python Think Bayes Scikit-learn tutorial – statistical learning for scientific data processing Python Data Science Handbook Covers topics such as some of the following: Introduction to Numpy Data manipulation with Pandas Visualization with Matplotlib Machine learning topics (Linear regression, SVM, random forest, principal component analysis, K-means clustering, Gaussian …
Great Site for Matrix Multiplication Demo

Here is a great website for the matrix multiplication demo. If you are a beginner data scientist, you will love this. http://matrixmultiplication.xyz/ Here is how the website looks like. It has just one page. It actually shows how multiplication happens given the different dimensions of the matrix. Here are few other websites for understanding matrix multiplication concepts: https://www.mathsisfun.com/algebra/matrix-multiplying.html Khan Academy – Matrix multiplication
Different types of Machine Learning Problems
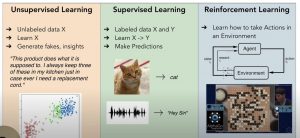
This post describes the most popular types of machine learning problems using multiple different images/pictures. The following represent various different types of machine learning problems: Supervised learning Unsupervised learning Reinforcement learning Transfer learning Imitation learning Meta-learning In this post, the image shows supervised, unsupervised, and reinforcement learning. You may want to check the explanation on this Youtube lecture video. Unsupervised Learning Problems In unsupervised learning problems, the learning algorithm learns about the structure of data from the given data set and generates fakes or insights. In the above diagram, you may see that what is given is the unlabeled dataset X. The unsupervised learning algorithm learns the structure of data …
Top 10+ Youtube AI / Machine Learning Courses

In this post, you get access to top Youtube free AI/machine learning courses. The courses are suitable for data scientists at all levels and cover the following areas of machine learning: Machine learning Deep learning Natural language processing (NLP) Reinforcement learning Here are the details of the free machine learning / deep learning Youtube courses. S.No Title Description Type 1 CS229: Machine Learning (Stanford) Machine learning lectures by Andrew NG; In case you are a beginner, these lectures are highly recommended Machine learning 2 Applied machine learning (Cornell Tech CS 5787) Covers all of the most important ML algorithms and how to apply them in practice. Includes 3 full lectures …
Scikit-learn vs Tensorflow – When to use What?

In this post, you will learn about when to use Scikit-learn vs Tensorflow. For data scientists/machine learning enthusiasts, it is very important to understand the difference such that they could use these libraries appropriately while working on different business use cases. When to use Scikit-learn? Scikit-learn is a great entry point for beginners data scientists. It provides an efficient implementation of many machine learning algorithms. In addition, it is very simple and easy to use. You can get started with Scikit-learn in a very easy manner by using Jupyter notebook. Scikit-learn can be used to solve different kinds of machine learning problems including some of the following: Classification (SVM, nearest neighbors, random …
Machine Learning – Training, Validation & Test Data Set
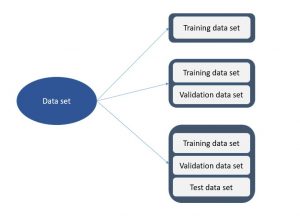
In this post, you will learn about the concepts of training, validation, and test data sets used for training machine learning models. The post is most suitable for data science beginners or those who would like to get clarity and a good understanding of training, validation, and test data sets concepts. The following topics will be covered: Data split – training, validation, and test data set Different model performance based on different data splits Data Splits – Training, Validation & Test Data Sets You can split data into the following different sets and each data split configuration will have machine learning models having different performance: Training data set: When you …
Why use Random Seed in Machine Learning?

In this post, you will learn about why and when do we use random seed values while training machine learning models. This is a question most likely asked by beginners data scientist/machine learning enthusiasts. We use random seed value while creating training and test data set. The goal is to make sure we get the same training and validation data set while we use different hyperparameters or machine learning algorithms in order to assess the performance of different models. This is where the random seed value comes into the picture. Different Python libraries such as scikit-learn etc have different ways of assigning random seeds. While training machine learning models using Scikit-learn, …
Precision & Recall Explained using Covid-19 Example
In this post, you will learn about the concepts of precision, recall, and accuracy when dealing with the machine learning classification model. Given that this is Covid-19 age, the idea is to explain these concepts in terms of a machine learning classification model predicting whether the patient is Corona positive or not based on the symptoms and other details. The following model performance concepts will be described with the help of examples. What is the model precision? What is the model recall? What is the model accuracy? What is the model confusion matrix? Which metrics to use – Precision or Recall? Before getting into learning the concepts, let’s look at the data (hypothetical) derived out …
Actionable Insights Examples – Turning Data into Action
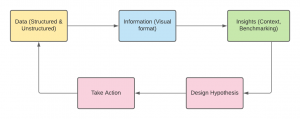
In this post, you will learn about how to turn data into information and then to actionable insights with the help of few examples. It will be helpful for data analysts, data scientists, and business analysts to get a good understanding of what is actionable insight? You will understand aspects related to data-driven decision making. Before getting into the details, let’s understand what is the problem at hand? The school authority is trying to assess and improve the health of students. Here is the question it is dealing with: How could we improve the overall health of the students in the school? We will look into the approach of finding the …
When to use Deep Learning vs Machine Learning Models?
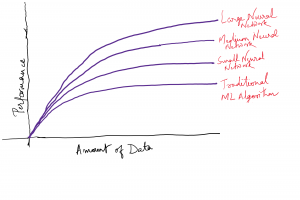
In this post, you will learn about when to go for training deep learning models from the perspective of model performance and volume of data. As a machine learning engineer or data scientist, it always bothers as to can we use deep learning models in place of traditional machine learning models trained using algorithms such as logistic regression, SVM, tree-based algorithms, etc. The objective of this post is to provide you with perspectives on when to go for traditional machine learning models vs deep learning models. The two key criteria based on which one can decide whether to go for deep learning vs traditional machine learning models are the following: …
Most Common Types of Machine Learning Problems
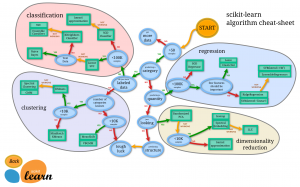
In this post, you will learn about the most common types of machine learning (ML) problems along with a few examples. Without further ado, let’s look at these problem types and understand the details. Regression Classification Clustering Time-series forecasting Anomaly detection Ranking Recommendation Data generation Optimization Problem types Details Algorithms Regression When the need is to predict numerical values, such kinds of problems are called regression problems. For example, house price prediction Linear regression, K-NN, random forest, neural networks Classification When there is a need to classify the data in different classes, it is called a classification problem. If there are two classes, it is called a binary classification problem. …
Historical Dates & Timeline for Deep Learning
This post is a quick check on the timeline including historical dates in relation to the evolution of deep learning. Without further ado, let’s get to the important dates and what happened on those dates in relation to deep learning: Year Details/Paper Information Who’s who 1943 An artificial neuron was proposed as a computational model of the “nerve net” in the brain. Paper: “A logical calculus of the ideas immanent in nervous activity,” Bulletin of Mathematical Biophysics, volume 5, 1943 Warren McCulloch, Walter Pitts Late 1950s A neural network application by reducing noise in phone lines was developed Paper: Andrew Goldstein, “Bernard Widrow oral history,” IEEE Global History Network, 1997 Bernard …
Great Mind Maps for Learning Machine Learning
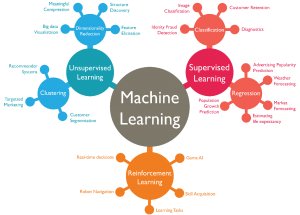
In this post, you will get to look at some of the great mind-maps for learning different machine learning topics. I have gathered these mind maps from different web pages on the Internet. The idea is to reinforce our understanding of different machine learning topics using pictures. You may have heard the proverb – A picture is worth a thousand words. Keeping this in mind, I thought to pull some of the great mind maps posted on different web pages. I would be updating this blog post from time-to-time. If you are a beginner data scientist or an experienced one, you may want to bookmark this page for refreshing your …
Different Types of Distance Measures in Machine Learning
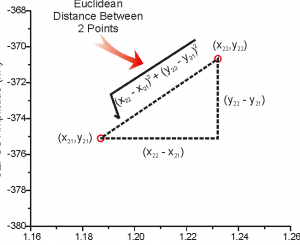
In this post, you will learn different types of distance measures used in different machine learning algorithms such as K-nearest neighbours, K-means etc. Distance measures are used to measure the similarity between two or more vectors in multi-dimensional space. The following represents different forms of distance metrics / measures: Geometric distances Computational distances Statistical distances Geometric Distance Measures Geometric distance metrics, primarily, tends to measure the similarity between two or more vectors solely based on the distance between two points in multi-dimensional space. The examples of such type of geometric distance measures are Minkowski distance, Euclidean distance and Manhattan distance. One other different form of geometric distance is cosine similarity which will discuss …
Machine Learning Terminologies for Beginners
When starting on the journey of learning machine learning and data science, we come across several different terminologies when going through different articles/posts, books & video lectures. Getting a good understanding of these terminologies and related concepts will help us understand these concepts in a nice manner. At a senior level, it gets tricky at times when the team of data scientists / ML engineers explain their projects and related outcomes. With this in context, this post lists down a set of commonly used machine learning terminologies that will help us get a good understanding of ML concepts and also engage with the DS / AI / ML team in …
I found it very helpful. However the differences are not too understandable for me