
What is a Type I Error?
When doing hypothesis testing, one ends up incorrectly rejecting the null hypothesis (default state of being) when in reality it holds true. The probability of rejecting a null hypothesis when it actually holds good is called as Type I error. Generally, a higher Type I error triggers eyebrows because this indicates that there is evidence against the default state of being. This essentially means that unexpected outcomes or alternate hypotheses can be true. Thus, it is recommended that one should aim to keep Type I errors as small as possible. Type I error is also called as “false positive“.
Lets try and understand type I error with the help of person held guilty or otherwise given the fact that he is innocent. The claim made or the hypothesis is that the person has committed a crime or is guilty. The null hypothesis will be that the person is not guilty or innocent. Based on the evidence gathered, the null hypothesis that the person is not guilty gets rejected. This means that the person is held guilty. However, the rejection of null hypothesis is false. This means that the person is held guilty although he/she was not guilty. In other words, the innocent person is convicted. This is an example of Type I error.
In order to achieve the lower Type I error, the hypothesis testing assigns a fairly small value to the significance level. Common values for significance level are 0.05 and 0.01, although, on average scenarios, 0.05 is used. Mathematically speaking, if the significance level is set to be 0.05, it is acceptable/OK to falsely or incorrectly reject the Null Hypothesis for 5% of the time.
Type I Error & House on Fire

Whether the house is on fire?
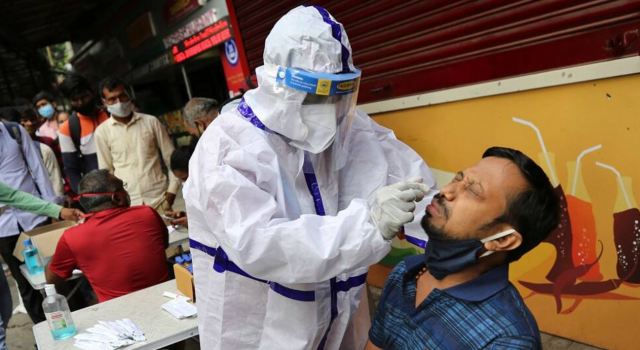
Type I Error & Covid-19 Diagnosis
What is a Type II Error?
Type II Error & House On Fire
Type II Error & Covid-19 Diagnosis
In the case of Covid-19 example, if the person having a breathing problem fails to reject the Null hypothesis, and does not go for Covid-19 diagnostic tests when he/she should actually have rejected it. This may prove fatal to life in case the person is actually suffering from Covid-19. Type II errors can turn out to be very fatal and expensive.
Type I Error & Type II Error Explained with Diagram
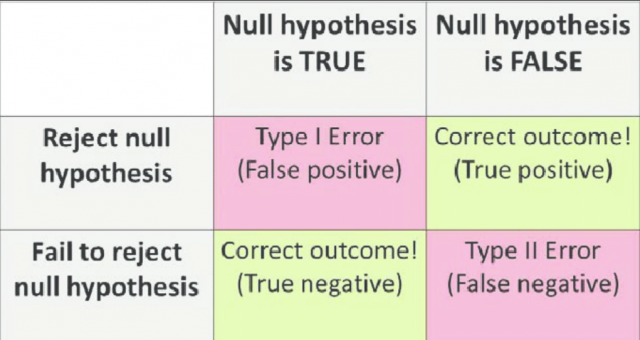
Given the diagram above, one could observe the following two scenarios:
- Type I Error: When one rejects the Null Hypothesis (H0 – Default state of being) given that H0 is true, one commits a Type I error. It can also be termed as false positive.
- Type II Error: When one fails to reject the Null hypothesis when it is actually false or does not hold good, one commits a Type II error. It can also be termed as a false negative.
- In other cases when one rejects the Null Hypothesis when it is false or not true, and when fails to reject the Null hypothesis when it is true is the correct decision.
Type I Error & Type II Error: Trade-off
Ideally it is desired that both the Type I and Type II error rates should remain small. But in practice, this is extermely hard to achieve. There typically is a trade-off. The Type I error can be made small by only rejecting H0 if we are quite sure that it doesn’t hold. This would mean a very small value of significance level such as 0.01. However, this will result in an increase in the Type II error. Alternatively, The Type II error can be made small by rejecting H0 in the presence of even modest evidence that it does not hold. This can be obtained by having slightly higher value of significance level ssuch as 0.1. This will, however, cause the Type I error to be large. In practice, we typically view Type I errors as “bad” or “not good” than Type II errors, because the former involves declaring a scientific finding that is not correct. Hence, when the hypothesis testing is performed, What is desired is typically a low Type I error rate — e.g., at most α = 0.05, while trying to make the Type II error small (or, equivalently, the power large).
Understanding the difference between Type I and Type II errors can help you make more informed decisions about how to use statistics in your research. If you are looking for some resources on how to integrate these concepts into your own work, reach out to us. We would be happy to provide additional training or answer any questions that may arise!

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me