Transformer Architecture Types: Explained with Examples
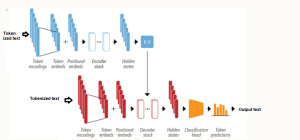
Are you fascinated by the power of deep learning large language models that can generate creative writing, answer complex questions, etc? Ever wondered how these LLMs understand and process human language with such finesse? At the heart of these remarkable achievements lies a machine learning model architecture that has revolutionized the field of Natural Language Processing (NLP) – the Transformer architecture and its types. But what makes Transformer models so special? From encoding sentences into numerical embeddings to employing attention mechanisms that capture the relationships between words, we will dissect different types of Transformer architectures, provide real-world examples, and even dive into the mathematics that governs its operation. Let’s explore …
Blueprint: Deploying Generative AI Applications
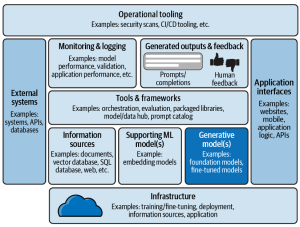
In this blog, we will learn about a comprehensive framework for the deployment of generative AI applications, breaking down the essential components that architects must consider. Learn more about this topic from this book: Generative AI on AWS. The following is a solution / technology architecture that represents a blueprint for deploying generative AI applications. The following is an explanation of the different components of this architectural viewpoint:
Pre-trained Models Explained with Examples
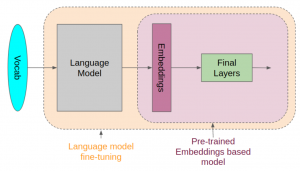
NLP has been around for decades, but it has recently seen an explosion in popularity due to pre-trained models (PTMs), also termed foundation models. This blog post will introduce you to different types of pre-trained (a.k.a. foundation) machine learning models and discuss their usage in real-world examples. Before we get into looking at different types of pre-trained models in NLP, let’s understand the concepts related to pre-trained models. What are Pre-trained Models? Pre-trained models (PTMs) are very large and complex neural network-based deep learning models, such as transformers, that consist of billions of parameters (a.k.a. weights) and have been trained on very large datasets to perform specific NLP tasks. The …
BERT vs GPT Models: Differences, Examples
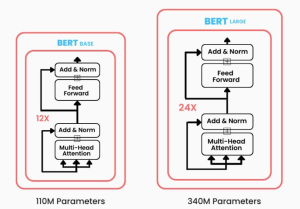
Have you been wondering what sets apart two of the most prominent transformer-based machine learning models in the field of NLP, Bidirectional Encoder Representations from Transformers (BERT) and Generative Pre-trained Transformers (GPT)? While BERT leverages encoder-only transformer architecture, GPT models are based on decoder-only transformer architecture. In this blog, we will delve into the core architecture, training objectives, real-world applications, examples, and more. By exploring these aspects, we’ll learn about the unique strengths and use cases of both BERT and GPT models, providing you with insights that can guide your next LLM-based NLP project or research endeavor. Differences between BERT vs GPT Models BERT, introduced in 2018, marked a significant …
NLP Corpus Types (Text & Multimodal): Examples

At the heart of NLP lies a fundamental element: the corpus. A corpus, in NLP, is not just a collection of text documents or utterances; it’s at the core of large language models (LLMs) training. Each corpus type serves a unique purpose in terms of training language models that serve different purposes. Whether it’s a collection of written texts, transcriptions of spoken words, or an amalgamation of various media forms, each corpus type holds the key to leveraging different aspects of language to generate value. In this blog, we’re going to explore the significance of these different corpora types in NLP. From the traditional text corpora consisting of written content …
Demystifying Encoder Decoder Architecture & Neural Network
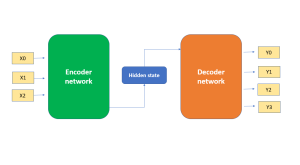
In the field of AI / machine learning, the encoder-decoder architecture is a widely-used framework for developing neural networks that can perform natural language processing (NLP) tasks such as language translation, text summarization, and question-answering systems, etc which require sequence-to-sequence modeling. This architecture involves a two-stage process where the input data is first encoded (using what is called an encoder) into a fixed-length numerical representation, which is then decoded (using a decoder) to produce an output that matches the desired format. In this blog, we will explore the inner workings of the encoder-decoder architecture, how it can be used to solve real-world problems, and some of the latest developments in …
Attention Mechanism Workflow & Transformer: Examples
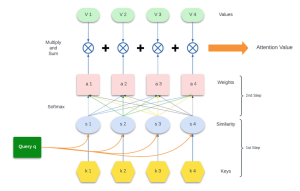
The attention mechanism workflow in the context of transformers in NLP, is a process that enables the model to dynamically focus on certain parts of the input data when performing a task such as machine translation, language understanding, text summarization, etc. Large language models, such as those based on the transformer architecture, rely on attention mechanisms to understand the context of words in a sentence and perform tasks as mentioned earlier. This mechanism selectively weights the significance of different parts of the input. This mechanism is essential for handling sequential data where the importance of each element may vary depending on the context. In this blog, we will learn about …
ChatGPT Prompts Best Practices: Examples
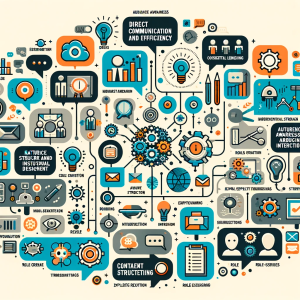
In this blog, you will learn the best practices you can adopt when writing prompts for ChatGPT. Here is the list: Direct Communication and Efficiency Audience Awareness and Contextual Understanding Interactive and Engaging Prompting Prompt Structure and Instructional Design Natural and Unbiased Interaction Content Creation and Revision Role-Assigning and Scripting Explicit Requirements and Mimicry
NLP: Different Types of Language Models – Examples

Have you ever wondered how your smartphone seems to know exactly what you’re going to type next? Or how virtual assistants like Alexa and Siri understand and respond to your queries with such precision? The magic is NLP language models. In this blog, we will explore the diverse types of language models in NLP that have evolved over time, each with its unique capabilities and applications. From the simplicity of N-gram models, which predict text based on preceding words, to the sophisticated neural network-based models like RNNs, LSTMs, and the groundbreaking large language models using Transformers, we will learn about the intricacies of these models, examples of real-world applications and …
Bag of Words in NLP & Machine Learning: Examples
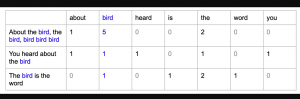
Last updated: 6th Jan, 2024 Most machine learning algorithms require numerical input for training the models. Bag of words (BoW) effectively converts text data into numerical feature vectors, making it compatible with a wide range of machine learning algorithms, from linear classifiers like logistic regression to complex ones like neural networks. In this post, you will learn about the concepts of bag-of-words model and how to train a text classification model using Python Sklearn. Some of the most common text classification problems includes sentiment analysis, spam filtering etc. In these problems, one can apply bag-of-words technique to train machine learning models for text classification. It will be good to understand the …
Innovative Thinking: Methods & Examples

Innovative thinking is a multifaceted approach that leverages different styles of thinking to tackle problems and generate groundbreaking solutions. It encompasses first principles thinking, which digs down to the foundational elements of an issue, analytical thinking that systematically dissects a problem into smaller, more manageable parts, critical thinking that involves evaluating and judging the information and ideas at hand, and infinite thinking, which pushes the boundaries of imagination to consider limitless possibilities. Each of these styles contributes uniquely to the process of innovation, offering a comprehensive toolkit for tackling challenges in novel and effective ways. In this blog, we’ll delve deeper into each of these styles, exploring how they individually …
Natural Language Processing (NLP) Task Examples

Last updated: 5th Jan, 2024 Have you ever wondered how your phone’s voice assistant understands your commands and responds appropriately? Or how search engines are able to provide relevant results for your queries? The answer lies in Natural Language Processing (NLP), a subfield of artificial intelligence (AI) that focuses on enabling machines to understand and process human language. NLP is becoming increasingly important in today’s world as more and more businesses are adopting AI-powered solutions to improve customer experiences, automate manual tasks, and gain insights from large volumes of textual data. With recent advancements in AI technology, it is now possible to use pre-trained language models such as ChatGPT to …
Cohen Kappa Score Explained: Formula, Example
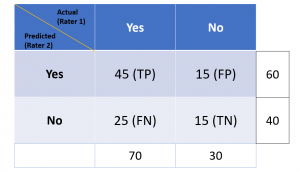
Last updated: 5th Jan, 2024 Cohen’s Kappa Score is a statistic used to measure the performance of machine learning classification models. In this blog post, we will discuss what Cohen’s Kappa Score is and Python code example representing how to calculate Kappa score using Python. We will also provide a code example so that you can see how it works! What is Cohen’s Kappa Score or Coefficient? Cohen’s Kappa Score, also known as the Kappa Coefficient, is a statistical measure of inter-rater agreement for categorical data. Cohen’s Kappa Coefficient is named after statistician Jacob Cohen, who developed the metric in 1960. It is generally used in situations where there …
Validation Techniques for Machine Learning Models: Examples

Last updated: 4th Jan, 2024 In the realm of machine learning, the emphasis increasingly shifts towards solving real-world problems with high-quality models. Creating high performant models does not not just depend on raw computational power or theoretical knowledge, but crucially on the ability to systematically conduct and learn from a myriad of different models by trying with hypothesis and related experiments including different algorithms, datasets / features, hyperparameters, etc. This is where the importance of a robust validation strategy and related techniques becomes paramount. Validation techniques, in essence, are the methodologies employed to accurately assess a model’s errors and to gauge how its performance fluctuates with different experiments. The primary …
Machine Learning Definition, Examples, Method, Types
Last updated: 3rd Jan, 2024 Machine learning is a machine’s ability to learn from data. It has been around for decades, but machine learning is now being applied in nearly every industry and job function. In this blog post, we’ll cover a detailed introduction to what is machine learning (ML) including different definitions. We will also learn about different types of machine learning tasks, algorithms, etc along with real-world examples. What is machine learning & how does it work? Definition 1: Simply speaking, machine learning can be defined as an approach to model our beliefs about real-world events. For example, let’s say a person came to a doctor with a …
Machine Learning Models Solution Design: Examples

This blog is crafted for data scientists, machine learning (ML) and software engineers, business analysts / product managers, and anyone involved in the ML project lifecycle, aiming to create a reliable solution design and development strategy / plan for successful AI / machine learning project implementation and value realization. The blog revolves around a series of critical solution design questions, meticulously curated to guide teams from the initial conception of a project to its final deployment and beyond. By addressing each of these solution design questions, teams can ensure that they are not only building a model that is technically proficient but also one that aligns seamlessly with business objectives, …

I found it very helpful. However the differences are not too understandable for me