
Last updated: 5th Jan, 2024
Have you ever wondered how your phone’s voice assistant understands your commands and responds appropriately? Or how search engines are able to provide relevant results for your queries? The answer lies in Natural Language Processing (NLP), a subfield of artificial intelligence (AI) that focuses on enabling machines to understand and process human language.
NLP is becoming increasingly important in today’s world as more and more businesses are adopting AI-powered solutions to improve customer experiences, automate manual tasks, and gain insights from large volumes of textual data. With recent advancements in AI technology, it is now possible to use pre-trained language models such as ChatGPT to perform various NLP tasks with high accuracy. These tasks include text classification, sentiment analysis, named entity recognition, and more. In this blog post, we will explore some common NLP tasks with examples to help you better understand the capabilities of this exciting technology.
Learning examples of NLP tasks is important because it allows data scientists to understand the different techniques and algorithms used in processing natural language data. This knowledge can be applied to solve a wide range of business problems such as sentiment analysis, topic modeling, language translation, and more. So, let’s dive into the world of NLP!
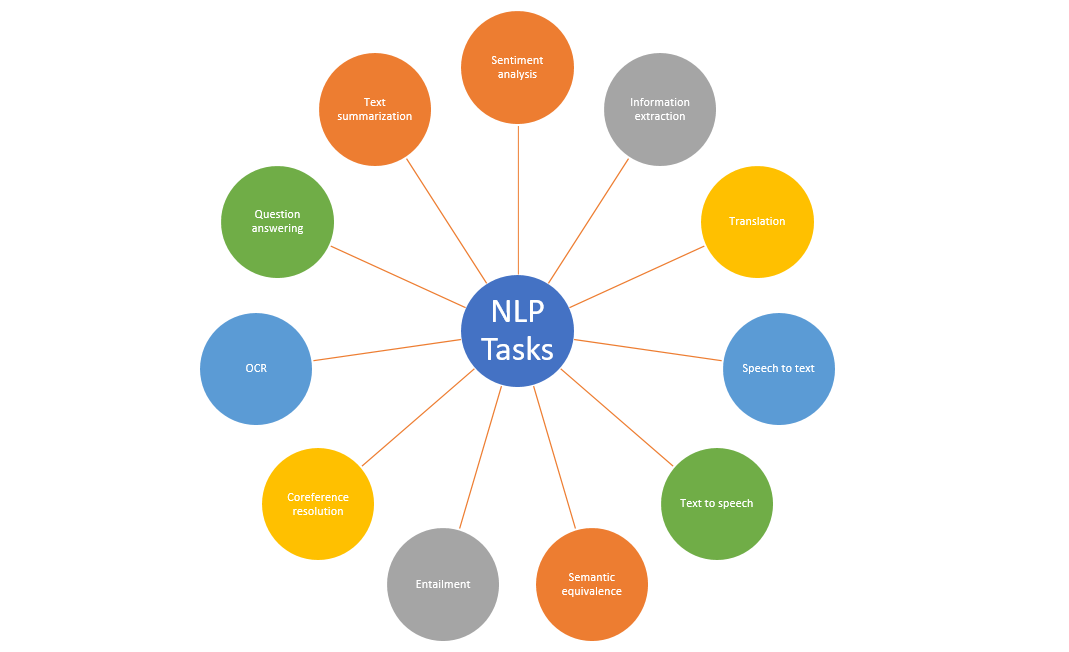
Here is a summary visualization of important NLP tasks:
Text Generation
Text Generation is one of the most popular NLP task in the recent times where the goal is to automatically generate natural language texts which can be in the form of sentences, paragraphs, or even entire documents. This task has witnessed remarkable advancements with the advent of Generative AI, particularly through Large Language Models (LLMs). These models are trained on vast datasets and can generate coherent, contextually relevant, and often surprisingly creative text.
Among the most popular LLMs used today for text generation are OpenAI’s GPT series (like GPT-3.5, GPT-4, etc) and Google’s BERT and its variants, such as T5 (Text-To-Text Transfer Transformer). GPT-4, known for its wide-ranging capabilities and large-scale training data, excels in generating human-like text, making it useful for applications like content creation, conversation simulation, and even coding. GPT models learn to predict the next word in a sentence and can generate lengthy and coherent passages of text that are contextually aligned with the input provided.
On the other hand, Google’s BERT and T5 take a slightly different approach. BERT is designed to understand the context of a word in a sentence, making it more effective for tasks that require a deep understanding of language, like sentiment analysis or question answering. T5, which treats every NLP problem as a text-to-text task, is also capable of generating high-quality text but is particularly known for its versatility in handling a range of NLP tasks, including translation and summarization.
Sentiment Analysis
Sentiment analysis is the process of identifying and extracting opinions and emotions from text data. An example of this would be analyzing customer reviews for a product to determine overall satisfaction levels. Here’s an example of a sentiment analysis task:
Review comment: I absolutely loved the new restaurant in town. The food was delicious and the service was excellent!
Sentiment Analysis Result: Positive
In this example, the sentiment analysis task correctly identifies the overall positive sentiment expressed in the text. Sentiment analysis is a common NLP task that involves analyzing written or spoken language to determine the emotional tone or attitude conveyed by the words used. It can be used for various purposes such as understanding customer feedback, monitoring brand reputation, and analyzing social media trends.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is an NLP task that involves identifying and classifying named entities in text into predefined categories such as the names of persons, organizations, locations, expressions of times, quantities, monetary values, percentages, etc. For example, consider the sentence: “Margaret visited IBM in New York on Tuesday.” In this case, NER would identify “Margaret” as a person, “IBM” as an organization, “New York” as a location, and “Tuesday” as a time expression.
Here is another example.
Text: “John Smith was born on January 5th, 1980 in New York City. He graduated from Harvard University in 2002 with a degree in Computer Science.”
Extracted Information:
- Name: John Smith
- Date of Birth: January 5th, 1980
- Place of Birth: New York City
- Education: Harvard University, Computer Science (2002)
Here are the top 3 popular methods of implementing NER:
- spaCy: A powerful, efficient library for advanced NLP in Python. Implementing NER with spaCy involves loading a pre-trained model, passing the text through the model, and iterating over the detected entities. It offers high accuracy and speed.
- NLTK (Natural Language Toolkit): A widely-used toolkit in Python for text processing. NLTK provides access to over 50 corpora and lexical resources, and includes a simple NER functionality, although it’s less powerful compared to spaCy.
- BERT (Bidirectional Encoder Representations from Transformers) by Google: BERT and its variants (like RoBERTa, DistilBERT) are primarily used for understanding the context in text. They are widely used in Python for tasks like sentiment analysis, named entity recognition, and question answering. BERT models can be easily accessed through libraries like Hugging Face’s Transformers.
Translation
Translation involves converting text from one language to another. For instance, Google Translate uses NLP algorithms to translate web pages or documents from one language to another in real-time. here’s an example of a translation NLP task:
Source Text: “Bonjour, comment ça va?”
Target Text: “Hello, how are you?”
In this example, the translation NLP task correctly translates the French text to English. Translation is a common NLP task that involves converting written or spoken language from one language to another while preserving the meaning and context of the original text. It can be used for various purposes such as translating documents, websites, and social media posts for international audiences.
Speech-to-text
Speech-to-text, also known as automatic speech recognition (ASR), is a critical NLP task that involves the conversion of spoken language into a written text format. This technology underpins the functionality of various applications, most notably virtual assistants like Siri, Alexa, and Google Assistant. These assistants leverage speech-to-text technology to interpret user commands or queries spoken aloud and then process these verbal inputs to provide appropriate responses or actions.
Text-to-speech
Text-to-speech is the process of converting written text into spoken words using computer-generated voices. A real-life example would be audiobooks that use NLP algorithms to convert written text into audio format.
OCR (Optical Character Recognition)
OCR involves recognizing printed or handwritten characters within an image or document and converting them into machine-readable text format.
A real-life example would be using OCR software to scan paper documents and convert them into digital formats for easy storage and retrieval. One real-life example of OCR is the use of mobile banking apps. Many banks now allow customers to deposit checks by taking a picture of them using their smartphone camera. The app then uses OCR technology to read the text on the check and extract important information such as the account number, routing number, and amount. This information is then used to process the deposit electronically without requiring the customer to physically go to a bank branch or ATM. This process saves time and is more convenient for customers while also reducing processing costs for banks.
Text Summarization
Text summarization involves condensing large amounts of text into shorter summaries while retaining important information. The goal of text summarization is to provide end users with an efficient way to understand the main points of a longer piece of text without having to read through every detail. There are two types of text summarization: extractive and abstractive.
Extractive summarization involves identifying the most important sentences or phrases from the original text and using them to create a summary. This type of summarization preserves the original wording and phrasing, but can sometimes result in summaries that lack coherence.
Abstractive summarization involves generating new sentences that convey the same meaning as the original text, but in a more concise manner. This type of summarization requires more advanced NLP techniques such as natural language generation and deep learning models.
Here is an example of extractive summarization:
Original text: The COVID-19 pandemic has had a significant impact on the global economy. Many businesses have been forced to close their doors due to lockdowns and social distancing measures. The travel and hospitality industries have been hit particularly hard, with many airlines and hotels experiencing massive losses. Governments around the world have implemented stimulus packages to help support affected businesses and individuals.
Summary: COVID-19 has significantly impacted the global economy, with many businesses closing due to lockdowns and social distancing measures. The travel and hospitality industries have been hit hard, with airlines and hotels experiencing huge losses. Governments have implemented stimulus packages to support affected businesses and individuals.
Question Answering
Question answering involves providing direct answers to questions posed by users in natural language format. Virtual assistants like Siri or Alexa use question answering techniques to provide relevant responses based on user queries. Here’s an example of a question answering NLP task:
Context: The COVID-19 pandemic has affected countries worldwide, leading to widespread lockdowns and economic disruption. Vaccines have been developed and distributed to combat the virus. BNT162b2 vaccine was developed by Pfizer-BioNTech
Question: What is the name of the vaccine that was developed by Pfizer-BioNTech?
Answer: The vaccine that was developed by Pfizer-BioNTech is called BNT162b2.
In this example, an NLP system would need to understand that the text is referring to a current event (the COVID-19 pandemic), identify the key information (vaccines being developed and distributed), and then correctly match the question with the appropriate answer.
Semantic Equivalence
Semantic equivalence refers to determining whether two sentences have the same meaning despite differences in phrasing or wording. For example, consider the following two sentences:
A. The cat sat on the mat.
B. The feline rested on the rug.
In the above case, you can see that both sentences convey the same information, even though they use different words to express it. Therefore, we can say that these two sentences are semantically equivalent.
Semantic equivalence has many practical applications in natural language processing such as text classification and information retrieval. For instance, if a system can accurately determine semantic equivalence between different pieces of text, it can be used to improve search engine results by identifying relevant documents or passages based on their meaning rather than just keyword matching. Similarly, semantic equivalence can help classify texts into categories based on their underlying meaning rather than just surface-level features like word choice and syntax.
Entailment
Entailment involves determining whether a given sentence logically follows from another sentence. In other words, if the meaning of one sentence necessarily implies the meaning of another sentence, then we say that the second sentence is entailed by the first. For example, consider the following two sentences:
A. John went to the store to buy some milk.
B. John bought some milk.
In this case, we can see that the second sentence (John bought some milk) is entailed by the first sentence (John went to the store to buy some milk), since going to the store to buy milk implies actually buying it. Therefore, we can say that these two sentences are logically related through entailment.
Entailment has many practical applications in natural language processing such as question answering and text classification. For instance, if a system can accurately determine entailment relationships between different pieces of text, it can be used to improve search engine results or help answer questions more accurately by identifying relevant information from large datasets.
Coreference Resolution
Coreference resolution is an NLP task that involves identifying which pronouns or noun phrases refer to the same entity in a sentence or paragraph. In other words, it helps determine who or what a particular pronoun refers to in context. For example, consider the following sentence:
John went to the store to buy some milk. He then went home and put it in the fridge.
In this case, the pronoun “he” refers back to John from the previous sentence. Coreference resolution helps identify this relationship between “John” and “he”, allowing NLP systems to accurately understand the meaning of the text.
Coreference resolution has many practical applications in natural language processing such as chatbots, machine translation, and question answering systems. For instance, if a chatbot can accurately resolve coreferences within user queries, it can provide more accurate responses by understanding exactly who or what is being referred to in each message.
Conclusion
In this blog post, we have explored various examples of Natural Language Processing (NLP) tasks and how they can be performed using advanced AI models like ChatGPT. We have covered popular NLP applications such as sentiment analysis, information extraction, translation, speech-to-text and text-to-speech conversion. We also discussed how NLP technology is being used in question answering systems and how it can help improve the accuracy of search engines. Furthermore, we explored the concepts of semantic equivalence and entailment and their significance in NLP. As we have seen throughout this article, NLP has become an essential tool for businesses looking to extract insights from large volumes of unstructured text data. With advancements in AI technology like ChatGPT and pre-trained language models becoming more accessible to data scientists and developers alike, it’s now easier than ever to perform complex NLP tasks with high accuracy. If you want to learn more, please drop a message.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me