The attention mechanism workflow in the context of transformers in NLP, is a process that enables the model to dynamically focus on certain parts of the input data when performing a task such as machine translation, language understanding, text summarization, etc. Large language models, such as those based on the transformer architecture, rely on attention mechanisms to understand the context of words in a sentence and perform tasks as mentioned earlier. This mechanism selectively weights the significance of different parts of the input. This mechanism is essential for handling sequential data where the importance of each element may vary depending on the context.
In this blog, we will learn about the details of the attention mechanism workflow and how it operates within the layers of a transformer machine learning model. We’ll do a deep dive into each step of the workflow process, from the initial embedding of the input sequence to the final generation of an attention-weighted output.
Attention Mechanism Workflow
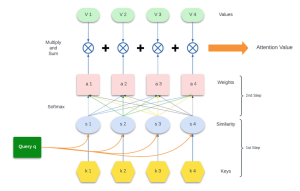
We will look into different steps of this attention mechanism workflow and understand the details. Here is the workflow diagram. You can find good detail in this book – Understanding Large Language Models: Learning Their Underlying Concepts and Technologies.
To make this concept easier to understand, let’s apply it to a simple sentence: “The cat sat on the mat”. We will walk through an eight-step attention mechanism workflow, referencing specific components of an attention mechanism diagram as shown below:
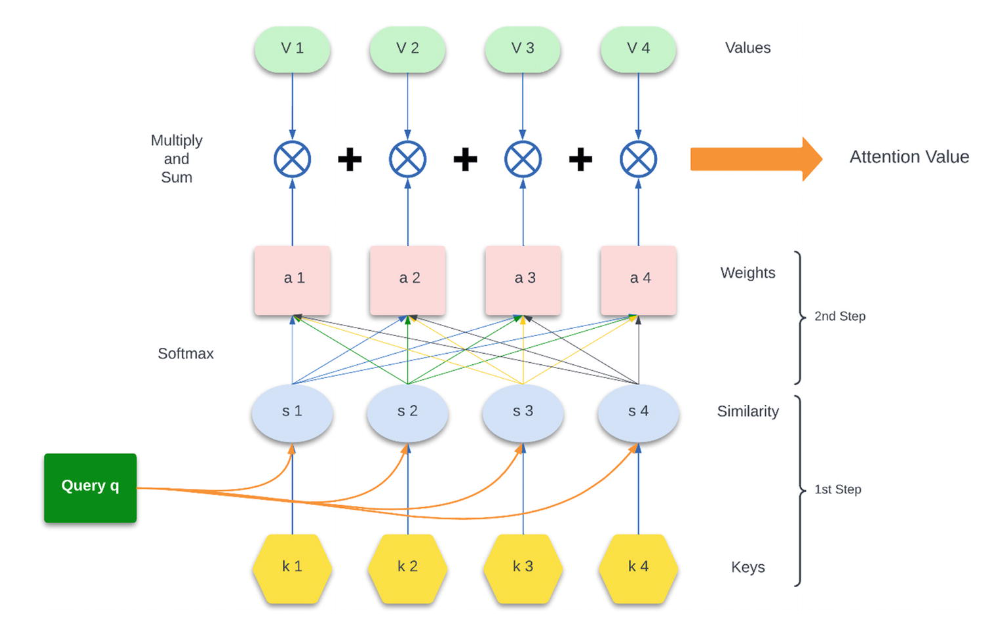
Step 1: Represent Words as Query Vector
Firstly, we start with a query. In the attention mechanism diagram, the query is depicted as a green box. If “sat” is our focus word, it is represented as a query vector (q). This is the starting point for determining the context within the sentence.
Example: For the word “sat”, the model generates a query vector that encapsulates its meaning and role in the sentence.
Step 2: Assign Keys (k1, k2, k3, k4, …) to Words
As shown by the yellow hexagons in our diagram, each word in the sentence is assigned a key vector. These vectors are rich in semantic and syntactic information, learned during the model’s training.
Example: The words “The”, “cat”, “on”, “the”, and “mat” are turned into key vectors (k1, k2, k3, k4, k5), ready to be compared with our query “sat”.
Step 3: Calculate Query-Key Similarities
The attention mechanism calculates the similarity between the query and each key, visualized by the orange lines in the diagram. Typically, the dot product is used to calculate this similarity, which serves as a measure of alignment between the vectors.
Example: The similarity between the query vector for “sat” and the key vectors for the other words in the sentence is computed, indicating which words are most contextually relevant to “sat”.
Step 4: Normalize Similarities with Softmax
Each similarity score is then passed through a softmax function, as shown by the blue circles in our diagram. This step normalizes the scores into a probability distribution, indicating the likelihood of each word being important to the query.
Example: The softmax function converts the similarity scores into weights, quantifying how much attention “sat” should pay to each of the other words.
Step 5: Assign Weights to Values
The pink rectangles in the diagram represent the weights. These are the attention probabilities which will be used to emphasize certain value vectors.
Example: The word “sat” is now assigned weights (a1, a2, a3, a4, a5), with higher weights likely given to “cat” and “mat”.
Step 6: Scale Values by Weights
Corresponding to the green ellipses in the diagram, each word also has a value vector. The values contain the content that will be used based on their relevance.
Example: Each word’s value vector (v1, v2, v3, v4, v5) will be scaled by its respective weight to contribute to the final attention output for “sat”.
Step 7: Multiply and Sum
This step involves multiplying each value vector by its weight and summing them up to form a single vector. This process is depicted by the crossed circles in the diagram.
Example: The value vectors are weighted by their attention weights and summed to form a contextually enriched representation of “sat”.
Step 8: Calculate Attention Value
Finally, the attention value is the output of the multiply and sum operation. In the diagram, this is represented by the arrow pointing to the right, indicating the direction of the workflow towards the final attention value. The attention value in transformer models helps in determining contextual relevance within input sequences, enabling the model to focus on the most pertinent parts for accurate output generation. Unlike traditional sequential models, transformers rely on these values to encode positional relationships. Through layered processing, these values facilitate the model’s ability to capture both detailed and abstract features of the data, significantly enhancing overall performance.
Example: The word “sat” now has a new vector that represents it in the context of the sentence, highlighting the influence of the words “cat” and “mat”.
Conclusion
The attention mechanism in transformers, crucial for tasks like machine translation and text summarization, follows a multi-step workflow to enhance contextual understanding. It begins with transforming input elements into query, key, and value vectors, representing different aspects of the data. The model then calculates the similarity between each query and key, often using dot products, to determine the relevance of different parts of the input. These similarities are normalized using a softmax function, turning them into attention weights. Subsequently, each value vector is scaled by its corresponding weight, with the weighted sum of these values forming the attention output. This output, indicative of focused information, is then integrated through the model’s layers, allowing for nuanced and contextually rich language processing. The attention mechanism’s ability to dynamically focus on relevant input segments, combined with its parallel processing capability, marks a significant advancement in handling complex language tasks efficiently and effectively.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me