Have you ever marveled at how typing a few words into a search engine yields exactly the information you’re looking for from the vast expanse of the web? This is largely thanks to the advancements in semantic search, bolstered by technologies like Large Language Models (LLMs). Semantic search, which focuses on understanding the intent and contextual meaning behind queries, benefits from LLMs to provide more accurate and relevant results. However, it’s important to note that traditional search engines also rely on a sophisticated mix of algorithms, indexing, and ranking systems. LLMs complement these systems by enhancing their ability to interpret complex queries, making your search experience more intuitive and effective.
There are three different ways of using LLMs for semantic search. They are Dense Retrieval, Reranking, and Generative Search. In this blog, you will learn about these great techniques in an easy-to-understand way. Large Language Models (LLMs) quickly became a staple in search technology following the release of the influential BERT paper. Google incorporated BERT into Google Search shortly after, marking a significant advancement in search capabilities. Similarly, Microsoft Bing enhanced its search quality significantly by integrating large transformer models. This widespread adoption underscores the remarkable impact and utility of LLMs. They have substantially improved semantic search – the ability to search by meaning rather than just keywords – in some of the world’s most sophisticated and widely used systems.
Dense Retrieval
Dense retrieval, one of the key types of semantic search, is a method that uses neural network embeddings to represent and retrieve information based on semantic similarity, rather than keyword matching, improving search relevance by understanding query and document meanings. In the context of dense retrieval, embeddings refer to the numerical representations of text data created by a neural network, which in this case is often a language model. These embeddings capture the semantic meaning of words, phrases, or documents and allow for the matching of queries to documents based on the similarity of their meanings rather than exact keyword matches.
The following are key steps of dense retrieval method that leverages LLMs for semantic search:
- Query: The user inputs a search query. This query is typically a string of text that represents the information need of the user.
- Dense Retrieval: This is the core of the semantic search process. Instead of traditional keyword matching, dense retrieval involves converting the query and the documents in the search database into high-dimensional vectors using a language model. The language model generates embeddings (dense vectors) that capture the semantic meaning of the text rather than just the presence or absence of specific terms.
- Results: After the query is converted into a vector, it’s compared against the vectors of potential result documents using a similarity measure (like cosine similarity). The most semantically similar documents are then retrieved as results.
- Ranking: The documents are ranked based on their similarity to the query vector. The most similar documents (those whose vectors are most similar to the query vector) are considered the most relevant to the query.
- Retrieval: The top ranked documents are then retrieved as the search results.
Reranking
Reranking, or re-scoring, is an essential step in many retrieval systems to enhance the quality of initially retrieved results. After the retrieval step, which could be sparse or dense retrieval, reranking models score and reorder the returned results based on a more nuanced understanding of the query’s semantics.
Here are the key steps involved in the reranking process:
- Query: This is the initial user input that is searching for information.
- Small Number of Relevant Texts: Initially, a set of documents is retrieved, which may not be in the order of their relevance to the query. These documents have been previously selected, likely through a method like dense retrieval, which identifies a broader list of candidate documents based on semantic similarity.
- Reranker: The reranker is a system, often powered by a Large Language Model, which takes the initial set of retrieved documents and analyzes them in greater depth. It examines the content more closely for relevance, quality, and other factors that may be important for the user’s search intent.
- Results (in improved order): After the reranker has processed the documents, it outputs them in a new order that better reflects their relevance to the query. This is typically done by giving higher ranks to the documents that the model predicts to be most useful for the query’s intent.
Like with dense retrieval, the effectiveness of reranking can depend heavily on the quality of the model and the data it was trained on.
Generative Search
Generative Search, on the other hand, opens a new frontier in LLM semantic search. Traditional retrieval methods start by finding relevant documents based on the query and then extract answers from those documents. In contrast, generative models directly generate responses to queries.
LLMs, with their sophisticated sequence-generation capabilities, are ideally suited for this sematic search task. They do not just find relevant information but can generate answers in natural language, thus offering a conversational feel to the search process. This trait of LLMs has been particularly beneficial in areas such as chatbots and question-answering systems. However, the quality and reliability of generative search often depend on the training data and how well the model has been fine-tuned for the specific task.
Here are the key steps in the Generative Search method, one of the semantic search method that leverages LLMs:
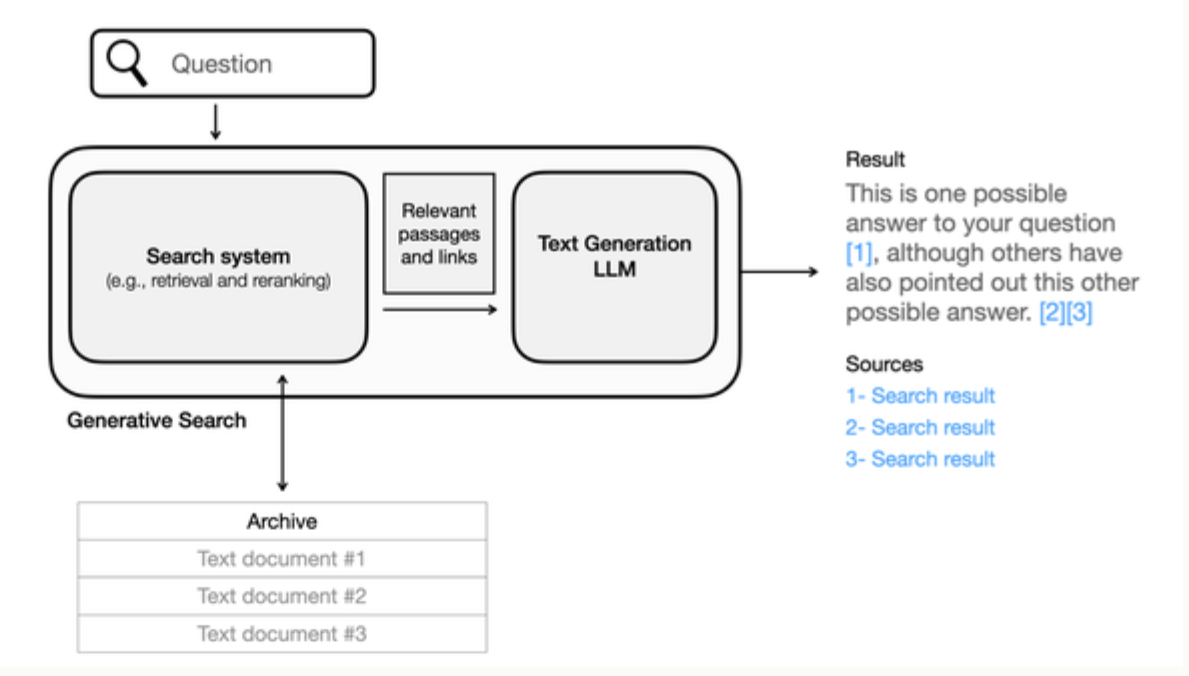
- In generative search, the process starts with a user inputting a question. This question is then processed by a generative search system, powered by a search system (dense retrieval & reranking) and a text generation LLM. The LLM interprets the question semantically—understanding the intent and the nuances of the question rather than relying on keyword matching.
- Subsequently, the LLM accesses a range of text documents, which may have been pre-filtered by relevance. It uses the information within these documents to construct a synthesized response. The power of LLMs in semantic search is their ability to integrate and comprehend information from multiple sources, thus generating a coherent and contextually relevant answer.
- The final output is not just a list of documents (sources) or excerpts but a coherently generated answer that directly addresses the user’s question. This answer also includes citations to the information sources—demonstrating transparency about where the information was derived from and allowing for verification. These citations are indicated by numbers in brackets, corresponding to the list of sources provided.
Conclusion
In a nutshell, Large Language Models (LLMs), through techniques like Dense Retrieval, Reranking, and Generative Search, are rewriting the rules of information retrieval and semantic search. They’ve transformed how we pull precise information from the ever-expanding digital universe, enhancing both speed and accuracy. As we move forward, we can expect these models to get even better, bringing us closer to a seamless interaction between humans and machines. The future of search promises to be more intuitive, personal, and effective, making it an exciting space to watch.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me