Last updated: 6th Jan, 2024
Most machine learning algorithms require numerical input for training the models. Bag of words (BoW) effectively converts text data into numerical feature vectors, making it compatible with a wide range of machine learning algorithms, from linear classifiers like logistic regression to complex ones like neural networks. In this post, you will learn about the concepts of bag-of-words model and how to train a text classification model using Python Sklearn. Some of the most common text classification problems includes sentiment analysis, spam filtering etc. In these problems, one can apply bag-of-words technique to train machine learning models for text classification. It will be good to understand the concepts of bag-of-words model while beginning on learning advanced NLP techniques for text classification in machine learning.
What is a Bag-of-Words (BoW) Model?
Bag of words model helps convert the text into numerical representation (numerical feature vectors) such that the same can be used to train models using machine learning algorithms. Here are the key steps of fitting a bag-of-words model:
- Tokenization: The first step is to break down the text into individual words or tokens.
- Vocabulary Creation: Create a vocabulary indices of words (also called as tokens) from the entire set of documents. The vocabulary indices can be created in alphabetical order.
- Vectorization: Construct the numerical feature vector for each document that represents how frequent each word appears in different documents. The feature vector representing each will be sparse in nature as the words in each document will represent only a small subset of words out of all words (bag-of-words) present in entire set of documents.
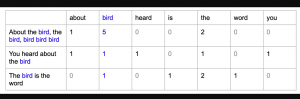
The picture below represents the above concept with the help of an example. Note some of the following:
- Number of words in header represents unique words in all the three documents listed in first column
- Against each document, number represents number of occurences. For example, for the first document, “bird” occured for 5 times, “the” occured for two times and “about” occured for 1 time.
Bag of Words Applications in Machine Learning
The following are some of the most common applications of BoW in machine learning:
- Feature Generation for Textual Data: BoW converts textual data into numerical form, which is essential as machine learning algorithms generally work on numeric data.
- Text Classification: In classification tasks like spam detection, sentiment analysis, or topic classification, BoW can provide a simple but effective way of feature extraction. In this blog, an example of text classification is demonstrated.
- Information Retrieval: BoW helps in creating a term-document matrix (TDM) which is crucial in various information retrieval applications. A term-document matrix is a mathematical matrix that describes the frequency of terms (words) in a collection of documents. Each row represents a unique term (word) from the entire text corpus (the collection of all documents). Each column corresponds to a document in the corpus. The entry in a row and column represents the frequency of that term in the specific document.
- Input for Further Processing: The BoW representation can be a starting point for more sophisticated models or techniques, like Term Frequency-Inverse Document Frequency (TF-IDF) or embeddings. TF-IDF is a numerical statistic that reflects how important a word is to a document in a collection or corpus. It’s calculated as the number of times a term t appears in a document divided by the total number of terms in that document.
Implementing bag-of-words Model using Python Sklearn
Let’s write Python Sklearn code to construct the bag-of-words from a sample set of documents. To construct a bag-of-words model based on the word counts in the respective documents, the CountVectorizer class implemented in scikit-learn is used. In the code given below, note the following:
- CountVectorizer (sklearn.feature_extraction.text.CountVectorizer) is used to fit the bag-or-words model. As a result of fitting the model, the following happens.
- The fit_transform method of CountVectorizer takes an array of text data, which can be documents or sentences. In the example given below, the numpay array consisting of text is passed as an argument.
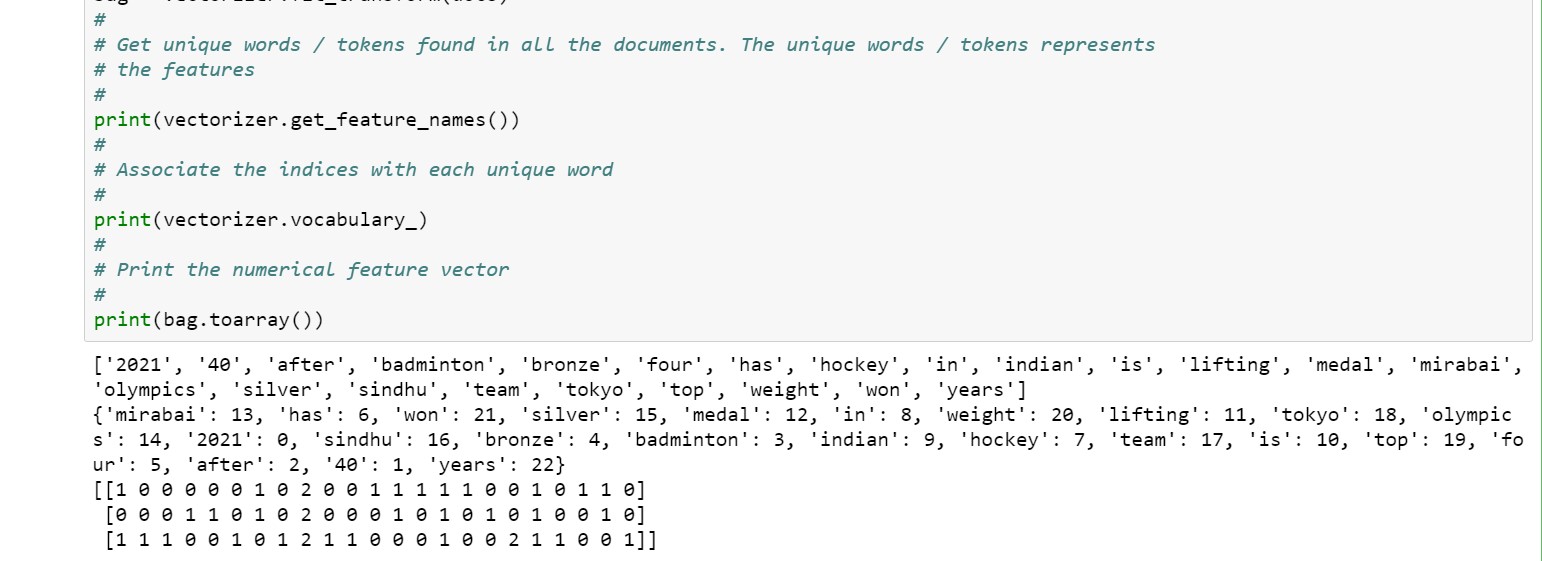
- The numpy array consisting of text is used to create the dictionary consisting of vocabulary indices. The vocabulary indices represent unique words and indices arranged in the alphabetical order. In the example given below, there are three documents stored in the numpy array. The first element is 2021:0, second term is 40:1, third term is after:2, fourth term is badminton:3 and so on and so forth. The documents stored in the numpy array represents the outcome of indian atheletes in current Tokyo olympics.
- Numerical feature vectore for each document is created based on frequency of words occuring in each document. For example, the “medal” word in first document, “Mirabai has won a silver medal in weight lifting in Tokyo olympics 2021” has indices of 12 and occured once in the document. However, the word “in” having indices 8 has occured twice (2 times) in the document. Note “2” in first vector.
- You can use NLTK for different purposes such as stemming, spell correction etc.
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer()
#
# Create sample set of documents
#
docs = np.array(['Mirabai has won a silver medal in weight lifting in Tokyo olympics 2021',
'Sindhu has won a bronze medal in badminton in Tokyo olympics',
'Indian hockey team is in top four team in Tokyo olympics 2021 after 40 years'])
#
# Fit the bag-of-words model
#
bag = vectorizer.fit_transform(docs)
#
# Get unique words / tokens found in all the documents. The unique words / tokens represents
# the features
#
print(vectorizer.get_feature_names())
#
# Associate the indices with each unique word
#
print(vectorizer.vocabulary_)
#
# Print the numerical feature vector
#
print(bag.toarray())
Here is how the output would look like:
You could learn more about the bags of model from the following video:
Fitting a Text Classification Model using Bag-of-words Technique
In this section, you will learn about how to fit or train a text classification model using bag-of-words technique. Pay attention to some of the following before looking into the Python code:
- Logistic regression classifier is trained using the training data set used in this post. You may want to check some of the following posts in relation to logistic regression:
- Training data set is created from bag-of-words technique
- The training and test data split is created from the numerical feature vector and dummy labels.
#
# Creating training data set from bag-of-words and dummy label
#
X = bag.toarray()
y = np.array([1, 1, 0, 0, 1, 0, 0, 1])
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
#
# Create training and test split
#
X_train, X_test, y_train, y_test = train_test_split(X, y)
#
# Create an instance of LogisticRegression classifier
#
lr = LogisticRegression(C=100.0, random_state=1, solver='lbfgs', multi_class='ovr')
#
# Fit the model
#
lr.fit(X_train, y_train)
#
# Create the predictions
#
y_predict = lr.predict(X_test)
# Use metrics.accuracy_score to measure the score
print("LogisticRegression Accuracy %.3f" %metrics.accuracy_score(y_test, y_predict))

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me