Category Archives: Data Science
Data Science Interview Questions – List

Are you preparing for a data science interview and looking for some common questions that may be asked? Look no further! In this blog post, we will provide a list of potential interview questions for a data science position. These questions cover a range of topics, from technical skills and experience to problem-solving and communication. Whether you are a seasoned data scientist or just starting out in the field, these questions will help you get ready for your upcoming interview and showcase your knowledge and expertise. So let’s dive in and see what’s in store! Here are some of the most popular / potential interview questions that may be asked …
Instance-based vs Model-based Learning: Differences
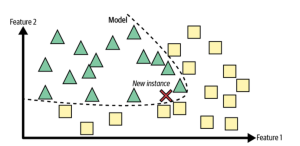
Machine learning is a field of artificial intelligence that deals with giving machines the ability to learn without being explicitly programmed. In this context, instance-based learning and model-based learning are two different approaches used to create machine learning models. While both approaches can be effective, they also have distinct differences that must be taken into account when building a machine learning system. Let’s explore the differences between these two types of machine learning. What is instance-based learning & how does it work? Instance-based learning (also known as memory-based learning or lazy learning) involves memorizing training data in order to make predictions about future data points. This approach doesn’t require any …
Data Analyst, Data Scientist or Data Engineer: What to Become?
There is a lot of confusion surrounding the job designations or titles such as “data analyst,” “data scientist,” and “data engineer“. What do these job titles mean, and what are the differences between them? Before selecting one of these career path, it will be good to get a good understanding about these job titles or designations, related roles & responsibilities and career potential. In this blog post, we will describe each title / designation and discuss the key distinctions between them. By the end of this post, you will have a better understanding of which career path and related designations are right for you! Shall I become a data analyst? …
Data Warehouse vs. Data Lake – Differences, Examples
When it comes to data storage, there are two distinct types of solutions that you can use—a data warehouse and a data lake. Both of these solutions have their own benefits, but it’s important to understand the key differences between them so that you can choose the best option for your needs. Let’s take a closer look at what makes each solution unique. What is a Data Warehouse? A data warehouse is defined as an electronic storage system used for reporting and analysis. Data warehouses store data in a structured (row-column) format. It typically contains aggregated collections of data from multiple sources, which come together in one database. A data warehouse …
Python Pickle Example: What, Why, How

Have you ever heard of the term “Python Pickle“? If not, don’t feel bad—it can be a confusing concept. However, it is a powerful tool that all data scientists, Python programmers, and web application developers should understand. In this article, we’ll break down what exactly pickling is, why it’s so important, and how to use it in your projects. What is Python Pickle? In its simplest form, pickling is the process of converting any object into a byte stream (a sequence of bytes). This byte stream can then be transmitted over a network or stored in a file for later use. It’s like putting the object into an envelope and …
Top 10 Basic Computer Science Topics to Learn
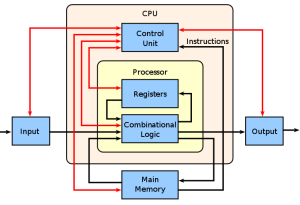
Computer science is an expansive field with a variety of areas that are worth exploring. Whether you’re just starting out or already have some experience in computer science, there are certain topics that every aspiring software engineer should understand. This blog post will cover the basic computer science topics that are essential for any software engineer or software programmer to know. Computer Architecture Computer architecture is a course of study that explores the fundamental elements of computer building and design. It’s an important field of study for software engineers to understand, since it provides basic principles and concepts related to hardware and software interactions. Computer architecture courses typically cover a …
Free Datasets for Machine Learning & Deep Learning

Are you looking for free / popular datasets to use for your machine learning or deep learning project? Look no further! In this blog post, we will provide an overview of some of the best free datasets available for machine learning and deep learning. These datasets can be used to train and evaluate your models, and many of them contain a wealth of valuable information that can be used to address a wide range of real-world problems. So, let’s dive in and take a look at some of the top free datasets for machine learning and deep learning! Here is the list of free data sets for machine learning & …
Difference between Online & Batch Learning
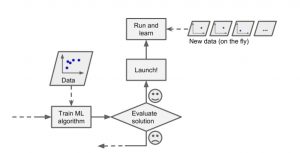
In this post, you will learn about the concepts and differences between online and batch or offline learning in relation to how machine learning models in production learn incrementally from the stream of incoming data or otherwise. It is one of the most important aspects of designing machine learning systems. Data science architects would require to get a good understanding of when to go for online learning and when to go for batch or offline learning. Why online learning vs batch or offline learning? Before we get into learning the concepts of batch and on-line or online learning, let’s understand why we need different types of models training or learning …
Most Common Machine Learning Tasks
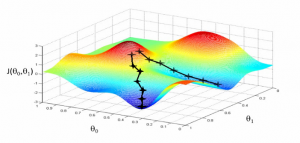
This article represents some of the most common machine learning tasks that one may come across while trying to solve machine learning problems. Also listed is a set of machine learning methods that could be used to resolve these tasks. Please feel free to comment/suggest if I missed mentioning one or more important points. Also, sorry for the typos. You might want to check out the post on what is machine learning?. Different aspects of machine learning concepts have been explained with the help of examples. Here is an excerpt from the page: Machine learning is about approximating mathematical functions (equations) representing real-world scenarios. These mathematical functions are also referred …
Moving Average Method for Time-series forecasting
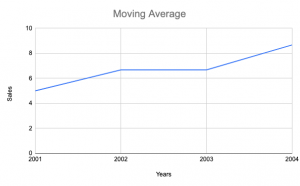
In this post, you will learn about the concepts of the moving average method in relation to time-series forecasting. You will get to learn Python examples in relation to training a moving average machine learning model. The following are some of the topics which will get covered in this post: What is the moving average method? Why use the moving average method? Python code example for the moving average methods What is Moving Average method? The moving average is a statistical method used for forecasting long-term trends. The technique represents taking an average of a set of numbers in a given range while moving the range. For example, let’s say …
Drivetrain Approach for Machine Learning
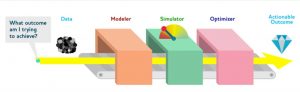
In this post, you will learn about a very popular approach or methodology called as Drivetrain approach coined by Jeremy Howard. The approach provides you steps to design data products that provide you with actionable outcomes while using one or more machine learning models. The approach is indeed very useful for data scientists/machine learning enthusiasts at all levels. However, this would prove to be a great guide for data science architects whose key responsibility includes designing the data products. Without further ado, let’s do a deep dive. Why Drivetrain Approach? Before getting into the drivetrain approach and understands the basic concepts, Lets understand why drivetrain approach in the first place? …
Machine Learning Models Evaluation Techniques
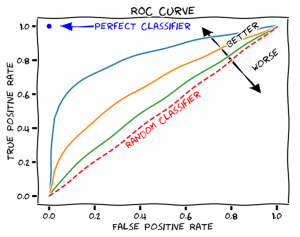
Machine learning is a powerful machine intelligence technique that can be used to develop predictive models for different types of data. It has become the backbone of many intelligent applications and evaluating machine learning model performance at a regular intervals is key to success of such applications. A machine learning model’s performance depends on several factors including the type of algorithm used, how well it was trained and more. In this blog post, we will discuss essential techniques for evaluating machine-learning model performance in order to provide you with some best practices when working with machine-learning models. The following are different techniques that can be used for evaluating machine learning …
Data Preprocessing Steps in Machine Learning

Data preprocessing is an essential step in any machine learning project. By cleaning and preparing your data, you can ensure that your machine learning model is as accurate as possible. In this blog post, we’ll cover some of the important and most common data preprocessing steps that every data scientist should know. Replace/remove missing data Before building a machine learning model, it is important to preprocess the data and remove or replace any missing values. Missing data can cause problems with the model, such as biased results or inaccurate predictions. There are a few different ways to handle missing data, but the best approach depends on the situation. In some …
Resume Screening using Machine Learning & NLP

In today’s job market, there are many qualified candidates vying for the same position. So, how do you weed out the applicants who are not a good fit for your company? One way to do this is by using machine learning and natural language processing (NLP) to screen resumes. By using machine learning and NLP to screen resumes, you can more efficiently identify candidates who have the skills and qualifications you are looking for. In this blog, we will learn different aspects of screening and selecting / shortlisting candidates for further processing using machine learning & NLP techniques. Key Challenges for Resume Screening / Shortlisting Resume screening is the process …
Bagging vs Boosting Machine Learning Methods
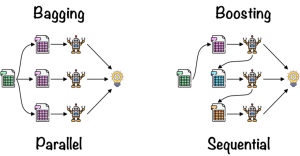
In machine learning, there are a variety of methods that can be used to improve the performance of your models. Two of the most popular methods are bagging and boosting. In this blog post, we’ll take a look at what these methods are and how they work with the help of examples. What is Bagging? Bagging, short for “bootstrap aggregating”, is a method that can be used to improve the accuracy of your machine learning models. The idea behind bagging is to train multiple models on different subsets of the data and then combine the predictions of those models. The data is split into a number of smaller datasets, or …
Healthcare Claims Processing AI Use Cases
In recent years, artificial intelligence (AI) / machine learning (ML) has begun to revolutionize many industries – and healthcare is no exception. Hospitals and insurance companies are now using AI to automate various tasks in the healthcare claims processing workflow. Claims processing is a complex and time-consuming task that often requires manual intervention. By using AI to automate claims processing, healthcare organizations can reduce costs, improve accuracy, and speed up the claims adjudication process. In this blog post, we will explore some of the most common use cases for healthcare claims processing AI / machine learning. Automated Data Entry One of the most time-consuming tasks in the claims process is …
I found it very helpful. However the differences are not too understandable for me