In machine learning, there are a variety of methods that can be used to improve the performance of your models. Two of the most popular methods are bagging and boosting. In this blog post, we’ll take a look at what these methods are and how they work with the help of examples.
What is Bagging?
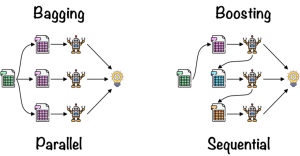
Bagging, short for “bootstrap aggregating”, is a method that can be used to improve the accuracy of your machine learning models. The idea behind bagging is to train multiple models on different subsets of the data and then combine the predictions of those models. The data is split into a number of smaller datasets, or “bags”, and individual models are trained on on each one. The models are then combined to produce a final prediction. Bagging is important in machine learning because it helps to reduce variance and improve the accuracy of predictions. When a machine learning algorithm is trained on a single data set, its performance can vary significantly depending on the composition of that data set. By training the algorithm on multiple data sets (each of which is a “bag” of data), Bagging can help to reduce the variation in the final predictions. This, in turn, results in more accurate predictions overall.
The benefits of using bagging in machine learning are:
- Increased accuracy: When you combine a number of models together, the individual models tend to be more accurate than any of the models would have been if they were used individually.
- Increased stability: Bagging can help to make your models more stable, meaning that they are less likely to be affected by noise in your data.
- Increased speed: By using a technique like bagging, you can often get better results more quickly than you would if you were to train individual models.
There are a few drawbacks to using bagging in machine learning. One is that, since it relies on a lot of randomness, it can be difficult to ensure that the individual models produced by the bagging algorithm are accurate. Additionally, the bagging algorithm can be slow to execute, which can be a problem when working with large data sets. Finally, because bagging is a relatively simple technique, it may not be as effective as more sophisticated machine learning algorithms in producing models that are accurate across a wide range of datasets.
What is Boosting?
Boosting is another popular method for improving the accuracy of machine learning models. The idea behind boosting is to train a series of weak models and then combine the predictions of those models to create a strong model. Unlike bagging, which trains multiple models independently, boosting trains each new model such that it focuses on correcting the errors made by the previous model. By training a series of weak models and combining their predictions, you can create a strong model that has high accuracy.
One of the benefits of using boosting in machine learning is that it can help to improve the accuracy of a classifier. This is because boosting can be used to combine the predictions of a number of different weak classifiers, which can result in a more accurate overall classification. Additionally, boosting can also be used to improve the robustness of a classifier, meaning that it is less likely to be affected by noise or inaccuracies in the data. Boosting can also be used to improve the generalization ability of the classifiers.
There are a few drawbacks to using boosting in machine learning. One is that it can be computationally expensive, especially if the boosting algorithm is implemented naively. Additionally, boosting can be unstable, meaning that the performance of the final model can vary significantly depending on the order in which the individual base models are combined. Finally, boosting can sometimes lead to overfitting, or a model that performs well on the training data but does not generalize well to new data.
Difference between Bagging & Boosting
Bagging and Boosting are two popular methods used in machine learning to improve the accuracy of models. Both methods are used to create ensembles, which are models that are created by combining multiple individual models. Both methods involve the use of multiple models, but they differ in how the models are generated. Bagging is a technique that involves training multiple models on different subsets of the data. The results of the individual models are then combined to form a final prediction. Boosting, on the other hand, trains multiple models sequentially. Boosting involves training each individual model in the ensemble using a weighted version of the training data. Each model is trained using the errors of the previous model as input. As a result, boosting typically achieves better performance than bagging. However, it is also more computationally expensive and can be more difficult to tune.
While both methods can improve the accuracy of predictions, Boosting is more effective at reducing bias, while Bagging is more effective at reducing variance. Bagging is generally more effective with architectures that are high variance and low bias, while boosting is more effective with architectures that are low variance and high bias. In general, boosting typically results in better performance than bagging, but it is also more computationally expensive.
Conclusion
In conclusion, bagging and boosting are two popular methods for improving the accuracy of machine learning models. Bagging works by training multiple models on different subsets of data and then combining the predictions of those models. Boosting works by training a series of weak models and then combining the predictions of those models. Both methods can be used to improve the accuracy of your machine learning models.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me