Machine learning is a field of artificial intelligence that deals with giving machines the ability to learn without being explicitly programmed. In this context, instance-based learning and model-based learning are two different approaches used to create machine learning models. While both approaches can be effective, they also have distinct differences that must be taken into account when building a machine learning system. Let’s explore the differences between these two types of machine learning.
What is instance-based learning & how does it work?
Instance-based learning (also known as memory-based learning or lazy learning) involves memorizing training data in order to make predictions about future data points. This approach doesn’t require any prior knowledge or assumptions about the data, which makes it easy to implement and understand. However, it can be computationally expensive since all of the training data needs to be stored in memory before making a prediction. Additionally, this approach doesn’t generalize well to unseen data sets because its predictions are based on memorized examples rather than learned models.
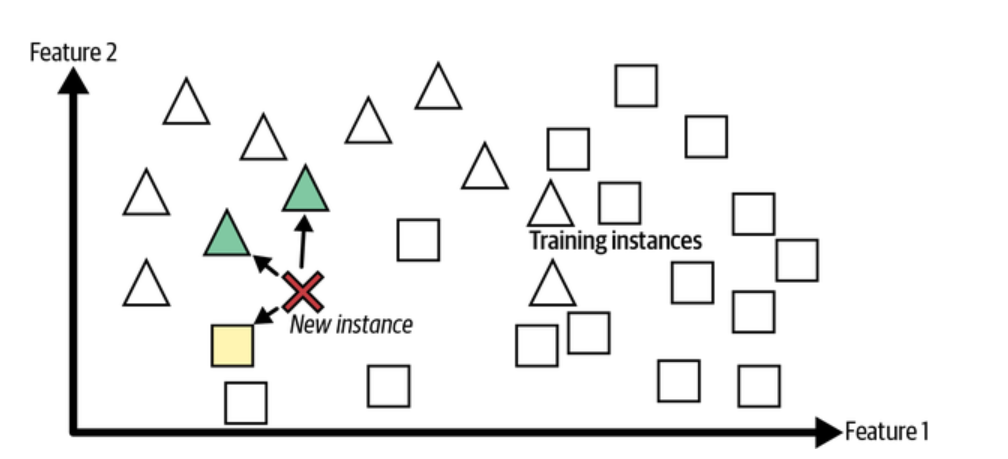
In instance-based learning, the system learns the training data by heart. At the time of making prediction, the system uses similarity measure and compare the new cases with the learned data. K-nearest neighbors (KNN) is an algorithm that belongs to the instance-based learning class of algorithms. KNN is a non-parametric algorithm because it does not assume any specific form or underlying structure in the data. Instead, it relies on a measure of similarity between each pair of data points. Generally speaking, this measure is based on either Euclidean distance or cosine similarity; however, other forms of metric can be used depending on the type of data being analyzed. Once the similarity between two points is calculated, KNN looks at how many neighbors are within a certain radius around that point and uses these neighbors as examples to make its prediction. This means that instead of creating a generalizable model from all of the data, KNN looks for similarities among individual data points and makes predictions accordingly. The picture below demonstrates how the new instance will be predicted as triangle based on greater number of triangles in its proximity.
In addition to providing accurate predictions, one major advantage of using KNN over other forms of supervised learning algorithms is its versatility; KNN can be used with both numeric datasets – such as when predicting house prices – and categorical datasets – such as when predicting whether a website visitor will purchase a product or not. Furthermore, there are no parameters involved in tuning KNN since it does not assume any underlying structure in the data that needs to be fitted into; instead, all parameters involved are dependent on how close two points are considered to be similar.
Because KNN is an instance-based learning algorithm, it is not suitable for very large datasets. This is because the model has to store all of the training examples in memory, and making predictions on new data points involves comparing the new point to all of the stored training examples. However, for small or medium-sized datasets, KNN can be a very effective learning algorithm.
Other instance-based learning algorithms include learning vector quantization (LVQ) and self-organizing maps (SOMs). These algorithms also memorize the training examples and use them to make predictions on new data, but they use different techniques to do so.
What is model-based learning & how does it work?
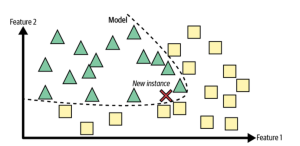
Model-based learning (also known as structure-based or eager learning) takes a different approach by constructing models from the training data that can generalize better than instance-based methods. This involves using algorithms like linear regression, logistic regression, random forest, etc. trees to create an underlying model from which predictions can be made for new data points. The picture below represents how the prediction about the class is decided based on boundary learned from training data rather than comparing with learned data set based on similarity measures.
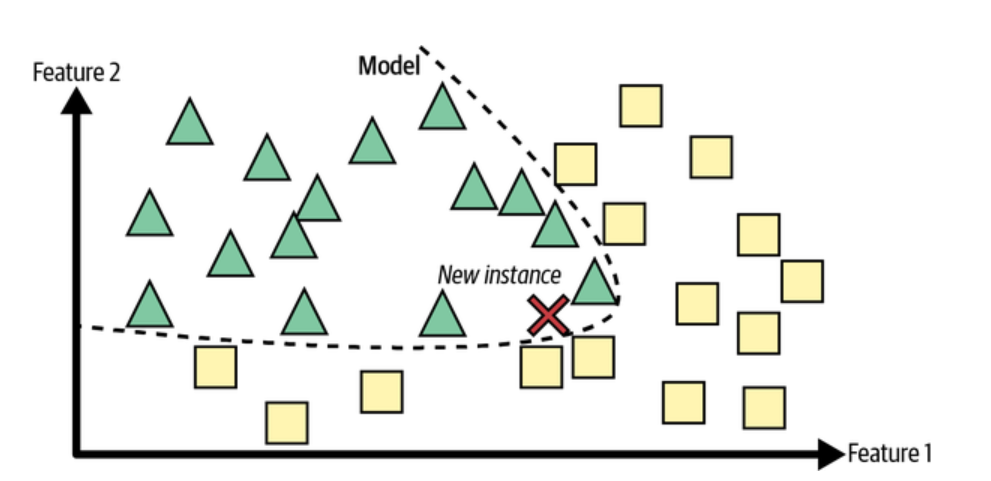
The model based learning approach has several benefits over instance-based methods, such as faster processing speeds and better generalization capabilities due to its use of an underlying model rather than relying solely on memorized examples. However, this approach requires more time and effort to develop and tune the model for optimal performance on unseen data sets.
Differences between Instance-based & Model-based Learning
Instance-based learning and model-based learning are two broad categories of machine learning algorithms. There are several key differences between these two types of algorithms, including:
- Generalization: In model-based learning, the goal is to learn a generalizable model that can be used to make predictions on new data. This means that the model is trained on a dataset and then tested on a separate, unseen dataset to evaluate its performance. In contrast, instance-based learning algorithms simply memorize the training examples and use them to make predictions on new data. This means that instance-based learning algorithms don’t try to learn a generalizable model, and their performance on new data is not as reliable as model-based algorithms.
- Scalability: Because instance-based learning algorithms simply memorize the training examples, they can be very slow and memory-intensive when working with large datasets. This is because the model has to store all of the training examples in memory and compare new data points to each of the stored examples. In contrast, model-based learning algorithms can be more scalable because they don’t have to store all of the training examples. Instead, they learn a model that can be used to make predictions without storing the training data.
- Interpretability: Model-based learning algorithms often produce models that are easier to interpret than instance-based learning algorithms. This is because the model-based algorithms learn a set of rules or parameters that can be inspected to understand how the model is making predictions. In contrast, instance-based learning algorithms simply store the training examples and use them as a basis for making predictions, which can make it difficult to understand how the predictions are being made.
Overall, while instance-based learning algorithms can be effective for small or medium-sized datasets, they are generally not as scalable or interpretable as model-based learning algorithms. Therefore, model-based learning is often preferred for larger, more complex datasets.
Conclusion
In conclusion, instance-based and model-base learning are two distinct approaches used in machine learning systems. Instance-based methods require less effort but don’t generalize well while model-base methods require more effort but produce better generalization capabilities. It is important for anyone working with machine learning systems to understand how these two approaches differ so they can choose the best one for their specific applications. With a proper understanding of both types of machine learning techniques, you will be able to create powerful systems that achieve your desired goals with minimal effort and maximum accuracy!

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me