Category Archives: Python
Three Approaches to Creating AI Agents: Code Examples
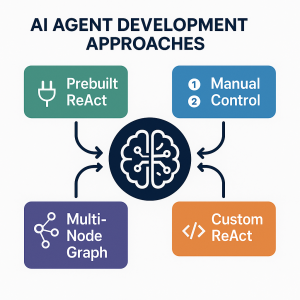
AI agents are autonomous systems combining three core components: a reasoning engine (powered by LLM), tools for external actions, and memory to maintain context. Unlike traditional AI-powered chatbots (created using DialogFlow, AWS Lex), agents can interact with end user based on planning multi-step workflows, use specialized tools, and make decisions based on previous results. In this blog, we will learn about different approaches for building agentic systems. The blog represents Python code examples to explain each of the approaches for creating AI agents. Before getting into the blog, lets quickly look at the set up code which will be basis for code used in the approaches. To explain different approaches, …
Invoke Python ML Models from Other Applications – Examples
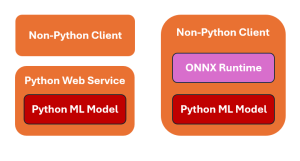
When working with Python-based machine learning models, a common question that pops up is how do we invoke models written in Python from apps written in other languages? The picture below represents two strategies for invoking Python machine learning models from client applications written using other programming languages such as Java, C++, C#, etc. The following is explanation for the above: Sample Flask Code for Python Web Service The following is the sample Python Flask application to work with a pre-trained ML model saved as model.pkl (pickle file). Non-python client can invoke this webservice appropriately. The model is loaded once when the server starts, ensuring efficient use of resources. The …
Principal Component Analysis (PCA) & Feature Extraction – Examples

Last updated: 17 Sept, 2024 Principal component analysis (PCA)is a dimensionality reduction technique that reduces the number of dimensions or features in a dataset without sacrificing a lot of information. What if it is told that you could take a dataset with 500 columns, use PCA to reduce it to 50 columns, and still able to retain 90% or more of the information in the original dataset? Wouldn’t that sound like a miracle? In this post, you will learn about how to use PCA for extracting important features (also termed as feature extraction technique) from a list of given features. As a machine learning / data scientist, it is very …
Content-based Recommender System: Python Example

In this blog, we will learn about how to implement content-based recommender system using Python programming example. We will learn with the example of movie recommender system for recommending movies. Download the movies data from here to work with example given in this blog. The following is a list of key activities we would do to build a movie recommender system based on content-based recommendation technique. Data loading & preparation Text vectorization Cosine similarity computation Getting recommendations Data Loading & Preparation To start with, we import the data in csv format. Once data is imported, next step is analyse and prepare data before we apply modeling techniques. The dataset contains …
Sklearn LabelEncoder Example – Single & Multiple Columns

Last updated: 13 Sept, 2024 In this post, you will learn about the concept of encoding such as Label Encoding used for encoding categorical features while training machine learning models. Label encoding technique is implemented using sklearn LabelEncoder. You would learn the concept and usage of sklearn LabelEncoder using code examples, for handling encoding labels related to categorical features of single and multiple columns in Python Pandas Dataframe. The following are some of the points which will get covered: Background When working with dataset having categorical features, you come across two different types of features such as the following. Many machine learning algorithms require the categorical data (labels) to be …
ROC Curve & AUC Explained with Python Examples
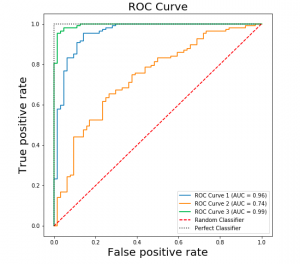
Last updated: 8th Sep, 2024 Confusion among data scientists regarding whether to use ROC Curve / AUC, or, Accuracy / precision / recall metrics for evaluating classification models often stems from misunderstanding ROC Curve / AUC concepts. The ROC Curve visualizes true positive vs false positive rates at various thresholds, while AUC quantifies the overall ability of a model to discriminate between classes, with higher values indicating better performance. In this post, you will learn about ROC Curve and AUC concepts along with related concepts such as True positive and false positive rate with the help of Python examples. It is very important to learn ROC, AUC and related concepts as it …
Accuracy, Precision, Recall & F1-Score – Python Examples
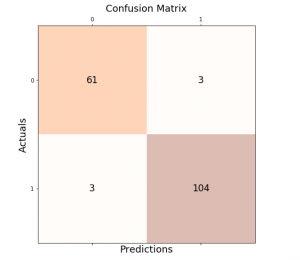
Last updated: 27th Aug, 2024 Classification models are used in classification problems to predict the target class of the data sample. The classification machine learning models predicts the probability that each instance belongs to one class or another. It is important to evaluate the model performance in order to reliably use these models in production for solving real-world problems. The model performance metrics include accuracy, precision, recall, and F1-score. In this blog post, we will explore these classification model performance metrics such as accuracy, precision, recall, and F1-score through Python Sklearn example. As a data scientist, you must get a good understanding of concepts related to the above in relation to …
Logistic Regression in Machine Learning: Python Example
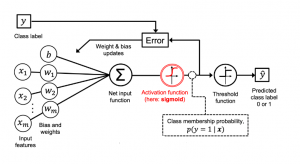
Last updated: 26th August, 2024 In this blog post, we will discuss the concepts of logistic regression machine learning algorithm with the help of python example. Logistic regression is a parametric algorithm which is used to estimate the probability of an event occurring. For example, it can be used in the medical field to predict the probability of a patient developing a certain disease based on various health indicators, such as age, weight, and blood pressure. It is often used in machine learning applications. What is Logistic Regression? Logistic regression is a type of supervised learning classification algorithm that is adept not only in binary classification but also in multinomial …
K-Fold Cross Validation in Machine Learning – Python Example
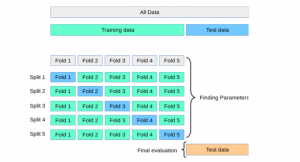
Last updated: 16th Aug, 2024 In this post, you will learn about K-fold Cross-Validation concepts used while training machine learning models with the help of Python code examples. K-fold cross-validation is a data splitting technique that is primarily used for assessing the model accuracy given smaller datasets. This technique can be implemented with k > 1 folds where k is equal number of data splits. K-Fold Cross Validation is also known as k-cross, k-fold cross-validation, k-fold CV, and k-folds. The k-fold cross-validation technique can be implemented easily using Python with scikit learn (Sklearn) package which provides an easy way to implement training of k-fold cross-validation models. It is important to learn the …
Random Forest Classifier – Sklearn Python Example
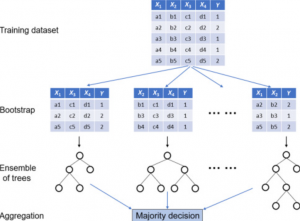
Last updated: 14th Aug, 2024 A random forest classifier is an ensemble machine learning model which is used for classification problems, and operates by constructing a multitude of decision trees during training, and, predicting the class label (of the data). In general, Random Forest is popular due to its high accuracy, robustness to overfitting, ability to handle large datasets with numerous features, and its effectiveness for both classification and regression tasks. Random Forest and Decision Tree classification algorithms are different, although Random Forest is built upon the concept of Decision Trees. In this post, you will learn about the concepts of random forest classifiers and how to train a Random …
Lasso Regression in Machine Learning: Python Example
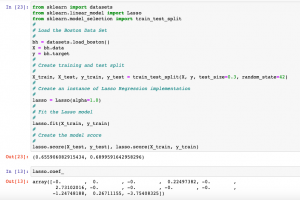
Last updated: 10th Aug, 2024 Lasso regression, sometimes referred to as L1 regularization, is a technique in linear regression that incorporates regularization to curb overfitting and enhance the performance of machine learning models. It works by adding a penalty term to the cost function that encourages the model to select only the most important features and set the coefficients of less important features to zero. This makes Lasso regression a popular method for feature selection and high-dimensional data analysis. In this post, you will learn concepts, formulas, advantages, and limitations of Lasso regression along with Python Sklearn examples. The other two similar forms of regularized linear regression are Ridge regression and …
Python Pickle Security Issues / Risk

Suppose your machine learning model is serialized as a Python pickle file and later loaded for making predictions. In that case, you need to be aware of security risks/issues associated with loading the Python Pickle file. Security Issue related to Python Pickle The Python pickle module is a powerful tool for serializing and deserializing Python object structures. However, its very power is also what makes it a potential security risk. When data is “pickled,” it is converted into a byte stream that can be written to a file or transmitted over a network. “Unpickling” this data reconstructs the original object in memory. The danger lies in the fact that unpickling …
Linear Regression T-test: Formula, Example
Last updated: 7th May, 2024 Linear regression is a popular statistical method used to model the relationship between a dependent variable and one or more independent variables. In linear regression, the t-test is a statistical hypothesis testing technique used to test the hypothesis related to the linearity of the relationship between the response variable and different predictor variables. In this blog, we will discuss linear regression and t-test and related formulas and examples. For a detailed read on linear regression, check out my related blog – Linear regression explained with real-life examples. T-tests are used in linear regression to determine if a particular independent variable (or feature) is statistically significant …
Feature Engineering in Machine Learning: Python Examples
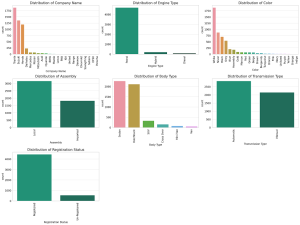
Last updated: 3rd May, 2024 Have you ever wondered why some machine learning models perform exceptionally well while others don’t? Could the magic ingredient be something other than the algorithm itself? The answer is often “Yes,” and the magic ingredient is feature engineering. Good feature engineering can make or break a model. In this blog, we will demystify various techniques for feature engineering, including feature extraction, interaction features, encoding categorical variables, feature scaling, and feature selection. To demonstrate these methods, we’ll use a real-world dataset containing car sales data. This dataset includes a variety of features such as ‘Company Name’, ‘Model Name’, ‘Price’, ‘Model Year’, ‘Mileage’, and more. Through this …
Gradient Descent in Machine Learning: Python Examples
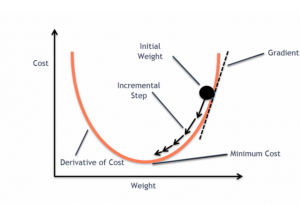
Last updated: 22nd April, 2024 This post will teach you about the gradient descent algorithm and its importance in training machine learning models. For a data scientist, it is of utmost importance to get a good grasp on the concepts of gradient descent algorithm as it is widely used for optimizing/minimizing the objective function / loss function / cost function related to various machine learning models such as regression, neural network, etc. in terms of learning optimal weights/parameters. This algorithm is essential because it underpins many machine learning models, enabling them to learn from data by optimizing their performance. Introduction to Gradient Descent Algorithm The gradient descent algorithm is an optimization …
Free IBM Data Sciences Courses on Coursera

In the rapidly evolving fields of Data Science and Artificial Intelligence, staying ahead means continually learning and adapting. In this blog, there is a list of around 20 free data science-related courses from IBM available on coursera.org that can help data science enthusiasts master different domains in AI / Data Science / Machine Learning. This list includes courses related to the core technical skills and knowledge needed to excel in these innovative fields. Foundational Knowledge: Understanding the essence of Data Science lays the groundwork for a successful career in this field. A solid foundation helps you grasp complex concepts easily and contributes to better decision-making, problem-solving, and the capacity to …
I found it very helpful. However the differences are not too understandable for me