Category Archives: Machine Learning
Cross Entropy Loss Explained with Python Examples
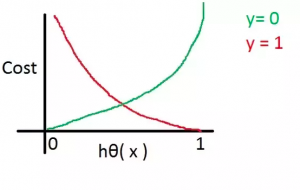
Last updated: 1st May, 2024 In this post, you will learn the concepts related to the cross-entropy loss function along with Python code examples and which machine learning algorithms use the cross-entropy loss function as an objective function for training the models. Cross-entropy loss represents a loss function for models that predict the probability value as output (probability distribution as output). Logistic regression is one such algorithm whose output is a probability distribution. You may want to check out the details on how cross-entropy loss is related to information theory and entropy concepts – Information theory & machine learning: Concepts What’s Cross-Entropy Loss? Cross-entropy loss, also known as negative log-likelihood …
Mean Squared Error vs Cross Entropy Loss Function
Last updated: 28th April, 2024 As a data scientist, understanding the nuances of various cost functions is critical for building high-performance machine learning models. Choosing the right cost function can significantly impact the performance of your model and determine how well it generalizes to unseen data. In this blog post, we will delve into two widely used cost functions: Mean Squared Error (MSE) and Cross Entropy Loss. By comparing their properties, applications, and trade-offs, we aim to provide you with a solid foundation for selecting the most suitable loss function for your specific problem. Cost functions play a pivotal role in training machine learning models as they quantify the difference …
Logistic Regression in Machine Learning: Python Example
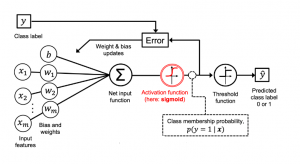
Last updated: 26th April, 2024 In this blog post, we will discuss the logistic regression machine learning algorithm with a python example. Logistic regression is a regression algorithm specifically designed to estimate the probability of an event occurring. For example, it can be used in the medical field to predict the likelihood of a patient developing a certain disease based on various health indicators, such as age, weight, and blood pressure. It is often used in machine learning applications. In this blog, we will learn about the logistic regression algorithm, and use python to implement the logistic regression model with IRIS dataset. What is Logistic Regression? The logistic regression algorithm …
MSE vs RMSE vs MAE vs MAPE vs R-Squared: When to Use?
Last updated: 22nd April, 2024 As data scientists, we navigate a sea of metrics to evaluate the performance of our regression models. Understanding these metrics – Mean Squared Error (MSE), Root Mean Squared Error (RMSE), Mean Absolute Error (MAE), Mean Absolute Percentage Error (MAPE), and R-Squared – is crucial for robust model evaluation and selection. In this blog, we delve into the intricacies of these different metrics while learning them based on clear definitions, formulas, and guidance on when to use which of these metrics. Different Types of Regression Models Evaluation Metrics The following are different types of regression model evaluation metrics including MSE, RMSE, MAE, MAPE, R-squared, and Adjusted …
Gradient Descent in Machine Learning: Python Examples
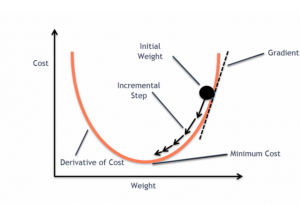
Last updated: 22nd April, 2024 This post will teach you about the gradient descent algorithm and its importance in training machine learning models. For a data scientist, it is of utmost importance to get a good grasp on the concepts of gradient descent algorithm as it is widely used for optimizing/minimizing the objective function / loss function / cost function related to various machine learning models such as regression, neural network, etc. in terms of learning optimal weights/parameters. This algorithm is essential because it underpins many machine learning models, enabling them to learn from data by optimizing their performance. Introduction to Gradient Descent Algorithm The gradient descent algorithm is an optimization …
Loss Function vs Cost Function vs Objective Function: Examples
Last updated: 19th April, 2024 Among the terminologies used in training machine learning models, the concepts of loss function, cost function, and objective function often cause a fair amount of confusion, especially for aspiring data scientists and practitioners in the early stages of their careers. The reason for this confusion isn’t unfounded, as these terms are similar / closely related, often used interchangeably, and yet, they are different and serve distinct purposes in the realm of machine learning algorithms. Understanding the differences and specific roles of loss function, cost function, and objective function is more than a mere exercise in academic rigor. By grasping these concepts, data scientists can make …
Model Parallelism vs Data Parallelism: Examples

Last updated: 19th April, 2024 Model parallelism and data parallelism are two strategies used to distribute the training of large machine-learning models across multiple computing resources, such as GPUs. They form key categories of multi-GPU training paradigms. These strategies are particularly important in deep learning, where models and datasets can be very large. What’s Data Parallelism? In data parallelism, we break down the data into small batches. Each GPU works on one batch of data at a time. It calculates two things: the loss, which tells us how far off our model’s predictions are from the actual outcomes, and the loss gradients, which guide us on how to adjust the …
Model Complexity & Overfitting in Machine Learning: How to Reduce

Last updated: 4th April, 2024 In machine learning, model complexity, and overfitting are related in that the model overfitting is a problem that can occur when a model is too complex for different reasons. This can cause the model to fit the noise in the data rather than the underlying pattern. As a result, the model will perform poorly when applied to new and unseen data. In this blog post, we will discuss model complexity and how you can avoid overfitting in your machine-learning models by handling the model complexity. As data scientists, it is of utmost importance to understand the concepts related to model complexity and how it impacts …
Self-Prediction vs Contrastive Learning: Examples

In the dynamic realm of AI, where labeled data is often scarce and costly, self-supervised learning helps unlock new machine learning use cases by harnessing the inherent structure of data for enhanced understanding without reliance on extensive labeled datasets as in the case of supervised learning. Simply speaking, self-supervised learning, at its core, is about teaching models to learn from the data itself, turning unlabeled data into a rich source of learning. There are two distinct methodologies used in self-supervised learning. They are the self-prediction method and contrastive learning method. In this blog, we will learn about their concepts and differences with the help of examples. What is the Self-Prediction …
Free IBM Data Sciences Courses on Coursera

In the rapidly evolving fields of Data Science and Artificial Intelligence, staying ahead means continually learning and adapting. In this blog, there is a list of around 20 free data science-related courses from IBM available on coursera.org that can help data science enthusiasts master different domains in AI / Data Science / Machine Learning. This list includes courses related to the core technical skills and knowledge needed to excel in these innovative fields. Foundational Knowledge: Understanding the essence of Data Science lays the groundwork for a successful career in this field. A solid foundation helps you grasp complex concepts easily and contributes to better decision-making, problem-solving, and the capacity to …
Self-Supervised Learning vs Transfer Learning: Examples
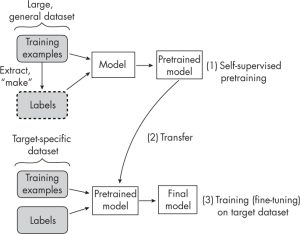
Last updated: 3rd March, 2024 Understanding the difference between self-supervised learning and transfer learning, along with their practical applications, is crucial for any data scientist looking to optimize model performance and efficiency. Self-supervised learning and transfer learning are two pivotal techniques in machine learning, each with its unique approach to leveraging data for model training. Transfer learning capitalizes on a model pre-trained on a broad dataset with diverse categories, to serve as a foundational model for a more specialized task. his method relies on labeled data, often requiring significant human effort to label. Self-supervised learning, in contrast, pre-trains models using unlabeled data, creatively generating its labels from the inherent structure …
Retrieval Augmented Generation (RAG) & LLM: Examples
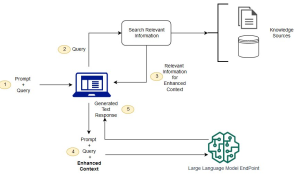
Last updated: 26th Jan, 2024 Have you ever wondered how to seamlessly integrate the vast knowledge of Large Language Models (LLMs) with the specificity of domain-specific knowledge stored in file storage, image storage, vector databases, etc? As the world of machine learning continues to evolve, the need for more sophisticated and contextually relevant responses from LLMs becomes paramount. Lack of contextual knowledge can result in LLM hallucination thereby producing inaccurate, unsafe, and factually incorrect responses. This is where context augmentation with prompts, and, hence retrieval augmentated generation method, comes into the picture. For data scientists and product managers keen on deploying LLMs in production, the Retrieval Augmented Generation pattern offers …
NLP Tokenization in Machine Learning: Python Examples

Last updated: 1st Feb, 2024 Tokenization is a fundamental step in Natural Language Processing (NLP) where text is broken down into smaller units called tokens. These tokens can be words, characters, or subwords, and this process is crucial for preparing text data for further analysis like parsing or text generation. Tokenization plays a crucial role in training machine learning models, particularly Large Language Models (LLMs) like GPT (Generative Pre-trained Transformer) series, BERT (Bidirectional Encoder Representations from Transformers), and others. Tokenization is often the first step in preparing text data for machine learning. LLMs use tokenization as an essential data preprocessing step. Advanced tokenization techniques (like those used in BERT) allow …
Large Language Models (LLMs): Types, Examples
Last updated: 31st Jan, 2024 Large language models (LLMs), being the key pillar of generative AI, have been gaining traction in the world of natural language processing (NLP) due to their ability to process massive amounts of text and generate accurate results related to predicting the next word in a sentence, given all the previous words. These different LLM models are trained on a large or broad corpus of text datasets, which contain hundreds of millions to billions of words. LLMs, as they are known, rely on complex algorithms including transformer architectures that shift through large datasets and recognize patterns at the word level. This data helps the LLMs better understand …
Amazon (AWS) Machine Learning / AI Services List

Last updated: 30th Jan, 2024 Amazon Web Services (AWS) is a cloud computing platform that offers machine learning as one of its many services. AWS has been around for over 10 years and has helped data scientists leverage the Amazon AWS cloud to train machine learning models. AWS provides an easy-to-use interface that helps data scientists build, test, and deploy their machine learning models with ease. AWS also provides access to pre-trained machine learning models so you can start building your model without having to spend time training it first! You can get greater details on AWS machine learning services, data science use cases, and other aspects in this book – …
LLM Optimization for Inference – Techniques, Examples
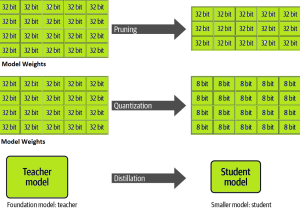
One of the common challenges faced with the deployment of large language models (LLMs) while achieving low-latency completions (inferences) is the size of the LLMs. The size of LLM throws challenges in terms of compute, storage, and memory requirements. And, the solution to this is to optimize the LLM deployment by taking advantage of model compression techniques that aim to reduce the size of the model. In this blog, we will look into three different optimization techniques namely pruning, quantization, and distillation along with their examples. These techniques help model load quickly while enabling reduced latency during LLM inference. They reduce the resource requirements for the compute, storage, and memory. …
I found it very helpful. However the differences are not too understandable for me