
Last updated: 25th August, 2024
In machine learning, model complexity and overfitting are related in that the model overfitting is a problem that can occur when a model is too complex for different reasons. This can cause the model to fit the noise & outliers in the data rather than the underlying pattern. As a result, the model will perform poorly when applied to new and unseen data. In this blog post, we will discuss model complexity and how you can avoid overfitting in your models by handling the complexity. As data scientists, it is of utmost importance to understand the concepts related to model complexity and how it impacts the model overfitting.
What is model complexity & why it’s important?
Model complexity is a key consideration in machine learning. Simply put, it refers to the number of predictor or independent variables or features that a model needs to take into account to make accurate predictions. For example, a linear regression model with just one independent variable is relatively simple, while a model with multiple variables or non-linear relationships is more complex. A model with a high degree of complexity may be able to capture more variations in the data, but it will also be more difficult to train and may be more prone to overfitting. On the other hand, a model with a low degree of complexity may be easier to train but may not be able to capture all the relevant information in the data. Finding the right balance between model complexity and predictive power is crucial for successful machine learning. The picture below represents a complex model (extreme right) vis-a-vis a simple model (extreme left). Note the aspect of some parameters vis-a-vis model complexity.
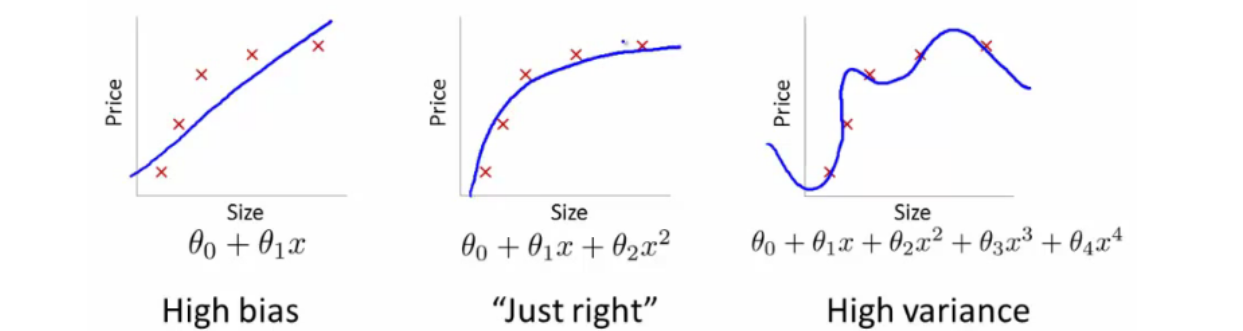
Model complexity is a measure of how accurately a machine learning model can predict unseen data, as well as how much data the model needs to see to make good predictions. Model complexity is an important consideration because it determines how generalizable a model is – that is, how well the model can be used to make predictions on new, unseen data. With simple models and abundant data, the generalization error is expected to be similar to the training error. With more complex models and fewer examples, the training error is expected to go down but the generalization gap grows which can also be termed model overfitting.
The following are key factors that govern the model complexity and impact the model accuracy with unseen data:
- The number of parameters: When there is a large number of tunable parameters, which is also sometimes called the degrees of freedom, the models tend to be more susceptible to overfitting.
- The range of values taken by the parameters: When the parameters can take a wider range of values, models can become more susceptible to overfitting.
- The number of training examples: With a fewer or smaller number of datasets, it becomes easier for models to overfit a dataset even if the model is simpler. Overfitting a dataset with millions of training examples requires an extremely complex model.
Why is model complexity important? Because as models become more complex, they are more likely to overfit the training data. This means that they may perform well on the training set but fail to generalize to new data. In other words, the model has learned too much about the specific training set and has not been able to learn the underlying patterns. As a result, it is essential to strike the right balance between model complexity and overfitting when developing machine learning models.
What’s model overfitting & how it’s related to model complexity?
Model overfitting occurs when a machine learning model is too complex, captures noise in the training data instead of the underlying signal, and therefore does not generalize well to new data. This is usually due to the model having been trained on too small of a dataset, or on a dataset that is too similar to the test dataset. The picture below represents the relationship between model complexity and training/test (generalization) prediction error.
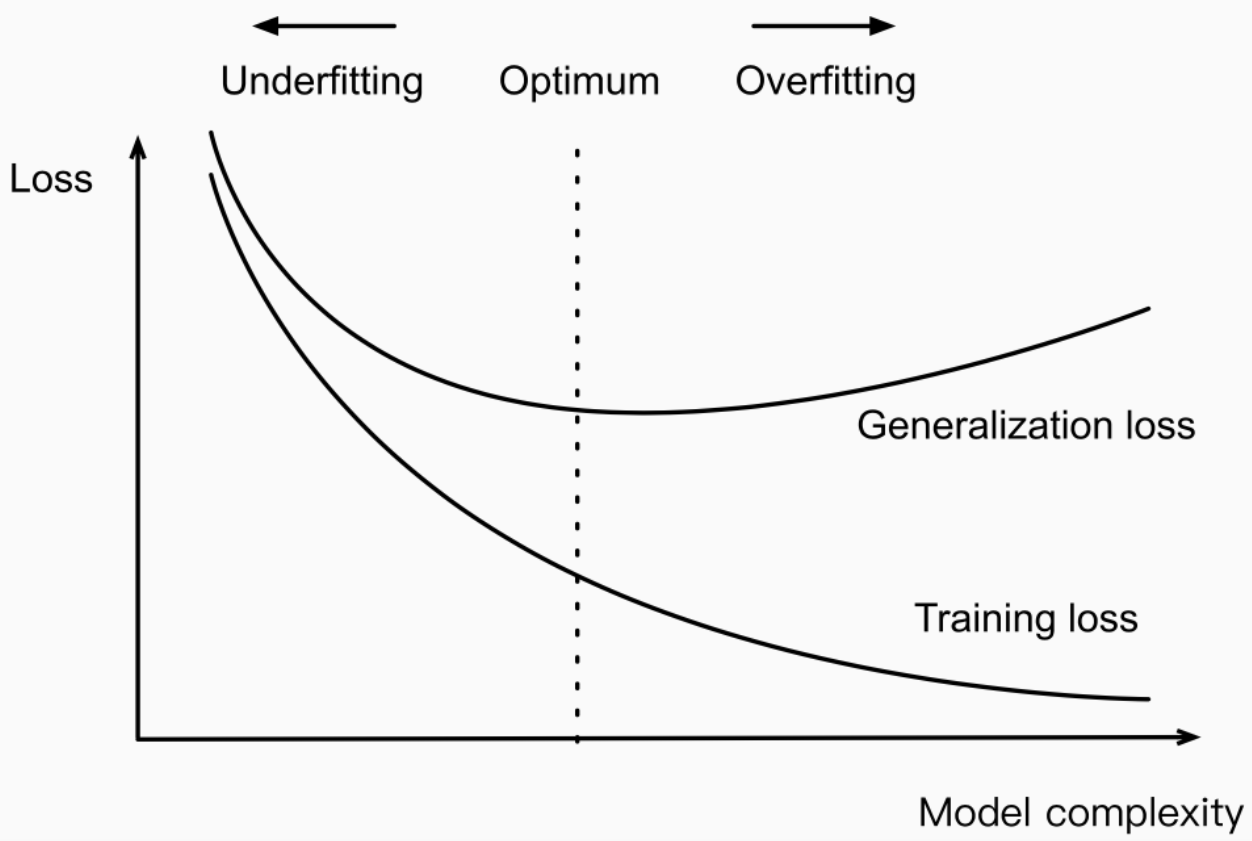
Note some of the following in the above picture:
- As the model complexity increases (x-direction), the training error decreases, and the test error increases.
- When the model is very complex, the gap between training and generalization/test error is very high. This is the state of overfitting
- When the model is very simple (less complex), the model will have a sufficiently high training error. The model is said to be underfitting.
In the case of neural networks, model complexity can be increased by adding more hidden layers to the model, or by increasing the number of neurons in each layer. Model overfitting can be prevented by using regularization techniques such as dropout or weight decay. When using these techniques, it is important to carefully choose the appropriate level of regularization, as too much regularization can lead to underfitting.
How to avoid model complexity and overfitting?
In machine learning, one of the main goals is to find a model that accurately predicts the output for new input data. However, it is also important to avoid both model complexity and overfitting. When models are too complex, they tend to overfit the training data and perform poorly on new, unseen data. This is because they have learned the noise in the training data rather than the underlying signal. Model complexity can also lead to longer training times and decreased accuracy while overfitting can cause the model to perform well on the training data but poorly on new data. There are a few ways to prevent these problems.
- Collect more data: One of the best ways to avoid overfitting is to collect high-quality data. How do we know whether the data is good quality data? The answer is the learning curve. The learning curve is a plot of model accuracy against the training set size. To create this plot, model accuracy is printed for both training and validation data sets with varying training data sets but fixed validation sets. If the validation accuracy increases with an increase in training dataset size, it is an indication of the need for good-quality data. Check out this post, Learning Curve Python Sklearn Example , to learn more about the learning curve.
- Data augmentation: In case, we have constraints with data collection, we can generate newer data records, or features as well based on the existing data. This is called data augmentation. It does help because it makes it difficult for the model to memorize the data.
- Use simpler models: This may seem counterintuitive, but simpler models are often more robust and generalize better to new data. One way to create simpler models is by avoiding too many features. If a model has too many features, it may start to overfit the data. It is important to select only the most relevant features for the model.
- Use regularization techniques, which help to avoid creating overly complex models by penalizing excessive parameter values. It adds a penalty to the loss function that is proportional to the size of the weights. Common regularization techniques include L1 (Lasso) and L2 (Ridge) regularization. For example, Lasso regression is a type of linear regression that uses regularization to reduce model complexity and prevent overfitting.
- Split the data into a training set and a test set, which allows the model to be trained on one set of data and then tested on another. This can help prevent overfitting by ensuring that the model generalizes well to new data.
- Use early stopping: Early stopping is another technique that can be used to prevent overfitting. It involves training the model until the validation error starts to increase and then stopping the training process. This ensures that the model does not continue to fit the training data after it has started to overfit.
- Use cross-validation: Cross-validation is a technique that can be used to reduce overfitting by splitting the data into multiple sets and training on each set in turn. This allows the model to be trained on different data and prevents it from being overfitted to a particular set of data.
- Monitor the performance of the model as it is trained and adjust the parameters accordingly.
- Pretraining methods: One can use pertaining methods such as self-supervised learning and transfer learning to leverage unlabeled datasets. This can also be used to avoid overfitting. Check out this post to learn more – Self-supervised learning vs Transfer learning: Examples.
Model complexity and overfitting are two of the main problems that can occur in machine learning. Model complexity can lead to a model that is too complex and does not generalize well to new data, while overfitting can cause the model to perform well on the training data but poorly on new data. There are several ways to prevent these problems, including using simpler models, using regularization techniques, splitting the data into a training set and a test set, early stopping, and cross-validation. It is important to monitor the performance of the model as it is being trained and adjust the parameters accordingly.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me