
Last updated: 24th August, 2024
Model parallelism and data parallelism are two strategies used to distribute the training of large machine-learning models across multiple computing resources, such as GPUs. They form key categories of multi-GPU training paradigms. These strategies are particularly important in deep learning, where models and datasets can be very large.
What’s Data Parallelism?
In data parallelism, we break down the data into small batches. Each GPU works on one batch of data at a time. It calculates two things: the loss, which tells us how far off our model’s predictions are from the actual outcomes, and the loss gradients, which guide us on how to adjust the model’s internal settings or weights to improve predictions. Once all GPUs finish their tasks, the calculated gradients are gathered and used to update the model’s weights, making it ready for the next round of learning. This way, even with limited resources, the model can be efficiently trained on large datasets.
In data parallelism, the model itself remains intact on each computing device, but the dataset is divided into smaller batches. Each device works on a different subset of the data but with an identical copy of the model. The picture below represents the multi-GPU training paradigm based on data parallelism.
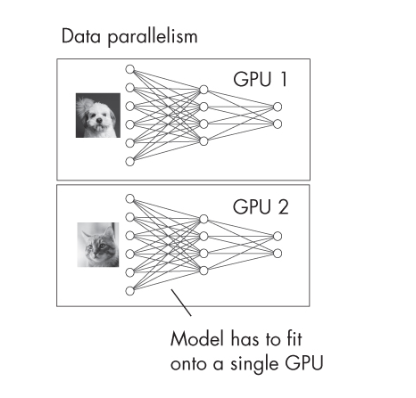
The communication happens when the gradients (which are calculated by each device independently) are aggregated across all devices to update the model weights. This usually happens after each batch or a group of batches has been processed.
Data parallelism scales well with the number of data samples and is particularly effective when the model size is not too large to fit into a single device’s memory.
An advantage of data parallelism over model parallelism is that the GPUs can run in parallel.
Data parallelism in PyTorch involves distributing the data across multiple GPUs and performing operations in parallel. PyTorch’s torch.nn.DataParallel or torch.nn.parallel.DistributedDataParallel modules make this process straightforward.
What’s Model Parallelism?
In model parallelism, also called as inter-op parallelism, the model itself is divided across different GPUs, meaning different parts of the model (e.g., layers or groups of neurons) are located on GPUs. The computation happens sequentially. The communication involves the transfer of intermediate outputs (activations) between devices as the data progresses through the model. This is because different parts of the input data need to be processed by different parts of the model residing on different devices.
In simple words, let’s say we have a very simplistic neural network model with one hidden layer and one output layer. With model parallelism, hidden layer can be trained on one GPU and the output layer can be trained on another GPU.
Model parallelism is particularly useful when the model is too large to fit into the memory of a single GPU. However, the efficiency of model parallelism can be limited by the overhead of inter-device communication. In addition, the chain like structure such as layer 1 on GPU 1, layer 2 on GPU 2, etc introduces bottleneck. The major disadvantage is that the GPUs have to wait for each other. The picture below represents this aspect of model parallelism.
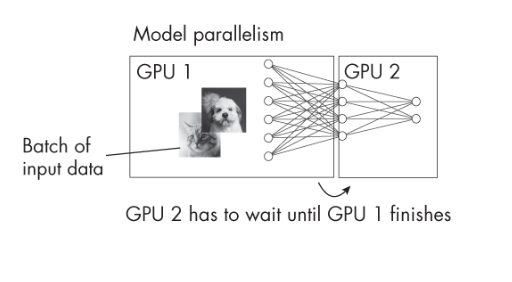
The following PyTorch code demonstrates the implementation of model parallelism. In the Python code below, the first layer (fc1) is on GPU 0 (cuda:0). The second and third layers (fc2, fc3) are on GPU 1 (cuda:1). The fourth layer in back on GPU 0 (cuda:0). Notice how the data is moved between GPUs using x.to(‘cuda:1’) and x.to(‘cuda:0’).
import torch
import torch.nn as nn
class ModelParallelNN(nn.Module):
def __init__(self):
super(ModelParallelNN, self).__init__()
# Assume we have two GPUs
self.fc1 = nn.Linear(1024, 512).to('cuda:0')
self.fc2 = nn.Linear(512, 256).to('cuda:1')
self.fc3 = nn.Linear(256, 128).to('cuda:1')
self.fc4 = nn.Linear(128, 10).to('cuda:0')
def forward(self, x):
x = x.to('cuda:0')
x = torch.relu(self.fc1(x))
x = x.to('cuda:1')
x = torch.relu(self.fc2(x))
x = torch.relu(self.fc3(x))
x = x.to('cuda:0')
x = self.fc4(x)
return x
model = ModelParallelNN()
There are more efficient ways of using multiple GPUs, such as tensor parallelism. You might check out this book, Machine Learning Q and AI, for more such topics.
Differences between Model Parallelism & Data Parallelism
The differences between model parallelism and data parallelism can be summarized as the following:
| Feature | Data Parallelism | Model Parallelism |
|---|---|---|
| Definition | The Data is split across devices while the model is copied across devices, and each model works on a different subset of the data. | The model is split across devices, with each part working on the same data but different parts of the model. |
| Communication | Involves aggregating gradients across all devices to update model weights. | Involves transferring intermediate outputs between devices as data progresses through the model. |
| Scalability | Works well when increasing dataset size, especially if the model size is not too large. | Useful for very large models that don’t fit into the memory of a single device. |
| Use Cases | Ideal for large datasets with smaller to moderately sized models. | Best suited for training very large models, regardless of dataset size. |
| Main Challenge | Managing the synchronization and aggregation of gradients from all devices. | Handling the communication overhead due to the transfer of intermediate outputs between devices. |
| Objective | To handle large datasets by distributing data. | To manage large model sizes by distributing the model’s architecture. |
You might want to check out Machine Learning Q and AI by Sebastian Rashka for an interesting read.
Quick Tutorial on the Difference between Model, Data & Tensor Parallelism

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
I found it very helpful. However the differences are not too understandable for me