Category Archives: Machine Learning
Adaboost Algorithm Explained with Python Example
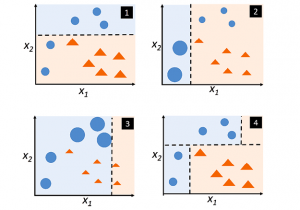
In this post, you will learn about boosting technique and adaboost algorithm with the help of Python example. You will also learn about the concept of boosting in general. Boosting classifiers are a class of ensemble-based machine learning algorithms which helps in variance reduction. It is very important for you as data scientist to learn both bagging and boosting techniques for solving classification problems. Check my post on bagging – Bagging Classifier explained with Python example for learning more about bagging technique. The following represents some of the topics covered in this post: What is Boosting and Adaboost Algorithm? Adaboost algorithm Python example What is Boosting and Adaboost Algorithm? As …
Hard vs Soft Voting Classifier Python Example
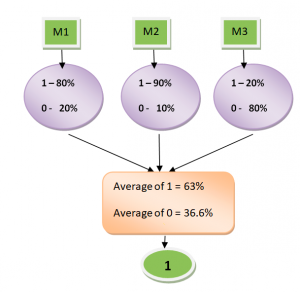
In this post, you will learn about one of the popular and powerful ensemble classifier called as Voting Classifier using Python Sklearn example. Voting classifier comes with multiple voting options such as hard and soft voting options. Hard vs Soft Voting classifier is illustrated with code examples. The following topic has been covered in this post: Voting classifier – Hard vs Soft voting options Voting classifier Python example Voting Classifier – Hard vs Soft Voting Options Voting Classifier is an estimator that combines models representing different classification algorithms associated with individual weights for confidence. The Voting classifier estimator built by combining different classification models turns out to be stronger meta-classifier that balances out the individual …
Keras Hello World Example
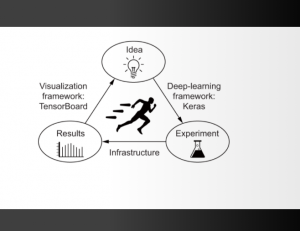
In this post, you will learn about how to set up Keras and get started with Keras, one of the most popular deep learning frameworks in current times which is built on top of TensorFlow 2.0 and can scale to large clusters of GPUs. You will also learn about getting started with hello world program with Keras code example. Here are some of the topics which will be covered in this post: Set up Keras with Anaconda Keras Hello World Program Set up Keras with Anaconda In this section, you will learn about how to set up Keras with Anaconda. Here are the steps: Go to Environments page in Anaconda App. …
PyTorch – How to Load & Predict using Resnet Model

In this post, you will learn about how to load and predict using pre-trained Resnet model using PyTorch library. Here is arxiv paper on Resnet. Before getting into the aspect of loading and predicting using Resnet (Residual neural network) using PyTorch, you would want to learn about how to load different pretrained models such as AlexNet, ResNet, DenseNet, GoogLenet, VGG etc. The PyTorch Torchvision projects allows you to load the models. Note that the torchvision package consists of popular datasets, model architectures, and common image transformations for computer vision. Here is the command: The output of above will list down all the pre-trained models available for loading and prediction. You may …
How to install PyTorch on Anaconda
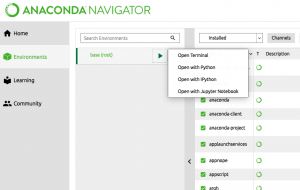
This is a quick post on how to install PyTorch on Anaconda and get started with deep learning projects. As a machine learning enthusiasts, this is the first step in getting started with PyTorch. I followed this steps on Mac Air and got started with PyTorch in no time. Here are the steps: Go to Anaconda tool. Click on “Environments” in the left navigation. Click on arrow marks on “base (root)” as shown in the diagram below. It will open up a small modal window as down. Click open terminal. This will open up a terminal window. Execute the following command to set up PyTorch. Once done, go to Jupyter Notebook window and …
Python – Nested Cross Validation for Algorithm Selection
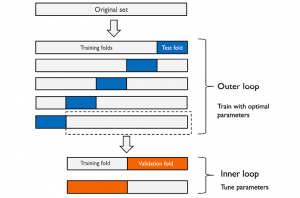
In this post, you will learn about nested cross validation technique and how you could use it for selecting the most optimal algorithm out of two or more algorithms used to train machine learning model. The usage of nested cross validation technique is illustrated using Python Sklearn example. When it is about selecting models trained with a particular algorithm with most optimal combination of hyper parameters, you can adopt the model tuning techniques such as some of the following: Grid search Randomized search Validation curve The following topics get covered in this post: Why nested cross-validation? Nested cross-validation with Python Sklearn example Why Nested Cross-Validation? Nested cross-validation technique is used for estimating …
Randomized Search Explained – Python Sklearn Example

In this post, you will learn about one of the machine learning model tuning technique called Randomized Search which is used to find the most optimal combination of hyper parameters for coming up with the best model. The randomized search concept will be illustrated using Python Sklearn code example. As a data scientist, you must learn some of these model tuning techniques to come up with most optimal models. You may want to check some of the other posts on tuning model parameters such as the following: Sklearn validation_curve for tuning model hyper parameters Sklearn GridSearchCV for tuning model hyper parameters In this post, the following topics will be covered: What and why …
Grid Search Explained – Python Sklearn Examples
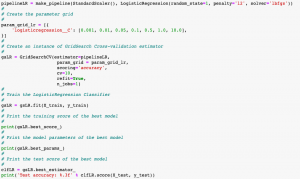
In this post, you will learn about another machine learning model hyperparameter optimization technique called as Grid Search with the help of Python Sklearn code examples. In one of the earlier posts, you learned about another hyperparamater optimization technique namely validation curve. As a data scientist, it will be useful to learn some of these model tuning techniques (tuning hyperparameters) as it would help us select most appropriate models with most appropriate parameters. The following are some of the topics covered in this post: What & Why of grid search? Grid search with Python Sklearn examples What & Why of Grid Search? Grid Search technique helps in performing exhaustive search over specified parameter (hyper parameters) values for …
Validation Curves Explained – Python Sklearn Example
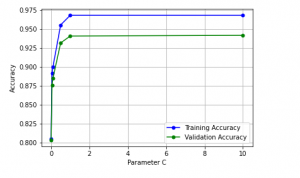
In this post, you will learn about validation curves with Python Sklearn example. You will learn about how validation curves can help diagnose or assess your machine learning models in relation to underfitting and overfitting. On the similar topic, I recommend you reading one of the previous post on assessing overfitting and underfitting titled Learning curves explained with Python Sklearn example. The following gets covered in this post: Why validation curves? Python Sklearn example for validation curves Why Validation Curves? As like learning curve, the validation curve also helps in diagnozing the model bias vs variance. The validation curve plot helps in selecting most appropriate model parameters (hyper-parameters). Unlike learning …
Logistic Regression Quiz Questions & Answers

In this post, you will learn about Logistic Regression terminologies / glossary with quiz / practice questions. For machine learning Engineers or data scientists wanting to test their understanding of Logistic regression or preparing for interviews, these concepts and related quiz questions and answers will come handy. Here is a related post, 30 Logistic regression interview practice questions I have posted earlier. Here are some of the questions and answers discussed in this post: What are different names / terms used in place of Logistic regression? Define Logistic regression in simple words? Define logistic regression in terms of logit? Define logistic function? What does training a logistic regression model mean? What are different types …
When to use LabelEncoder – Python Example

In this post, you will learn about when to use LabelEncoder. As a data scientist, you must have a clear understanding on when to use LabelEncoder and when to use other encoders such as One-hot Encoder. Using appropriate type of encoders is key part of data preprocessing in machine learning model building lifecycle. Here are some of the scenarios when you could use LabelEncoder without having impact on model. Use LabelEncoder when there are only two possible values of a categorical features. For example, features having value such as yes or no. Or, maybe, gender feature when there are only two possible values including male or female. Use LabelEncoder for …
Sklearn SelectFromModel for Feature Importance
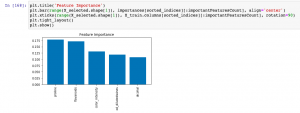
In this post, you will learn about how to use Sklearn SelectFromModel class for reducing the training / test data set to the new dataset which consists of features having feature importance value greater than a specified threshold value. This method is very important when one is using Sklearn pipeline for creating different stages and Sklearn RandomForest implementation (such as RandomForestClassifier) for feature selection. You may refer to this post to check out how RandomForestClassifier can be used for feature importance. The SelectFromModel usage is illustrated using Python code example. SelectFromModel Python Code Example Here are the steps and related python code for using SelectFromModel. Determine the feature importance using …
Sequential Forward Selection – Python Example
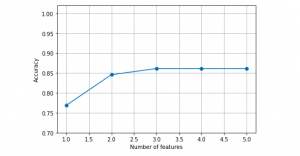
In this post, you will learn about one of feature selection techniques namely sequential forward selection with Python code example. Refer to my earlier post on sequential backward selection technique for feature selection. Sequential forward selection algorithm is a part of sequential feature selection algorithms. Some of the following topics will be covered in this post: Introduction to sequential feature selection algorithms Sequential forward selection algorithm Python example using sequential forward selection Introduction to Sequential Feature Selection Sequential feature selection algorithms including sequential forward selection algorithm belongs to the family of greedy search algorithms which are used to reduce an initial d-dimensional feature space to a k-dimensional feature subspace where k < d. …
Sequential Backward Feature Selection – Python Example
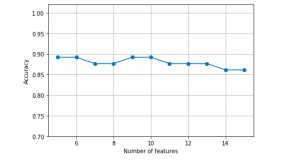
In this post, you will learn about a feature selection technique called as Sequential Backward Selection using Python code example. Feature selection is one of the key steps in training the most optimal model in order to achieve higher computational efficiency while training the model, and also reduce the the generalization error of the model by removing irrelevant features or noise. Some of the important feature selection techniques includes L-norm regularization and greedy search algorithms such as sequential forward or backward feature selection, especially for algorithms which don’t support regularization. It is of utmost importance for data scientists to learn these techniques in order to build optimal models. Sequential backward …
Pandas – Append Columns to Dataframe
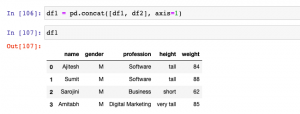
In this post, you will learn different techniques to append or add one column or multiple columns to Pandas Dataframe (Python). There are different scenarios where this could come very handy. For example, when there are two or more data frames created using different data sources, and you want to select a specific set of columns from different data frames to create one single data frame, the methods given below can be used to append or add one or more columns to create one single data frame. It will be good to know these methods as it helps in data preprocessing stage of building machine learning models. In this post, …
Pandas – Fillna method for replacing missing values
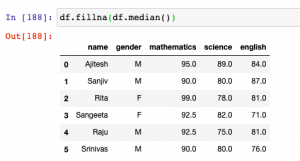
In this post, you will learn about how to use fillna method to replace or impute missing values of one or more feature column with central tendency measures in Pandas Dataframe (Python).The central tendency measures which are used to replace missing values are mean, median and mode. Here is a detailed post on how, what and when of replacing missing values with mean, median or mode. This will be helpful in the data preprocessing stage of building machine learning models. Other technique used for filling missing values is backfill or bfill and forward-fill or ffill. Before going further and learn about fillna method, here is the Pandas sample dataframe we will work with. It represents marks in …
I found it very helpful. However the differences are not too understandable for me