In this post, you will learn about another machine learning model hyperparameter optimization technique called as Grid Search with the help of Python Sklearn code examples. In one of the earlier posts, you learned about another hyperparamater optimization technique namely validation curve. As a data scientist, it will be useful to learn some of these model tuning techniques (tuning hyperparameters) as it would help us select most appropriate models with most appropriate parameters.
The following are some of the topics covered in this post:
- What & Why of grid search?
- Grid search with Python Sklearn examples
What & Why of Grid Search?
Grid Search technique helps in performing exhaustive search over specified parameter (hyper parameters) values for an estimator. One can use any kind of estimator such as sklearn.svm SVC, sklearn.linear_model LogisticRegression or sklearn.ensemble RandomForestClassifier.
The outcome of grid search is the optimal combination of one or more hyper parameters that gives the most optimal model complying to bias-variance tradeoff. This is owing to the fact that cross-validation techniques get applied in order to train and test model and come up with most optimal parameters combination. The manner in which grid search is different than validation curve technique is it allows you to search the parameters from the parameter grid. This is unlike validation curve where you can specify one parameter for optimization purpose.
Although Grid search is a very powerful approach for finding the optimal set of parameters, the evaluation of all possible parameter combinations is also computationally very expensive. An alternative approach for sampling different parameter combinations using sklearn is randomized search. This will be dealt in one of the future posts.
The grid search is implemented in Python Sklearn using the class, GridSearchCV. The class implements two methods such as fit, predict and score method.
In this post, the grid search is applied to the following estimators:
- RandomForestClassifier (Random forest): Grid search is applied on RandomForestClassifier to select the most appropriate value of hyper parameters such as max_depth and max_features.
- LogisticRegression (Logistic regression): Grid search is applied to select the most appropriate value of inverse regularization parameter, C. For this case, you could as well have used validation_curve (sklearn.model_selection) to select the most appropriate value of C.
- SVC (Support vector classifier): Grid search is applied to select the most appropriate parameters such as kernel (linear, rbf) and the values of gamma and C.
Grid Search with Python Sklearn Examples
In this section, you will see Python Sklearn code example of Grid Search algorithm applied to different estimators such as RandomForestClassifier, LogisticRegression and SVC. Pay attention to some of the following in the code given below:
- An instance of pipeline is created using make_pipeline method from sklearn.pipeline. The instance of pipeline is passed to GridSearchCV via estimator
- A JSON array of parameter grid is created for passing the same to GridSearchCV via param_grid
- Cross-validation generator is passed to GridSearchCV. In the example given in this post, the default such as StratifiedKFold is used by passing cv = 10
- Another parameter, refit = True, is used which refit the the best estimator to the whole training set automatically.
- The scoring parameter is set to ‘accuracy’ to calculate the accuracy score.
- Method, fit, is invoked on the instance of GridSearchCV with training data (X_train) and related label (y_train).
- Once the GridSearchCV estimator is fit, the following attributes are used to get vital information:
- best_score_: Gives the score of the best model which can be created using most optimal combination of hyper parameters
- best_params_: Gives the most optimal hyper parameters which can be used to get the best model
- best_estimator_: Gives the best model built using the most optimal hyperparameters
For example given below, Sklearn Breast Cancer data set is used. Here is the related code:
import pandas as pd
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
bc = datasets.load_breast_cancer()
X = bc.data
y = bc.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)
Grid Search and Random Forest Classifier
When applied to sklearn.ensemble RandomForestClassifier, one can tune the models against different paramaters such as max_features, max_depth etc. Here is an example demonstrating the usage of Grid Search for selection of most optimal values of max_depth and max_features hyper parameters. Note the parameter grid, param_grid_rfc
pipelineRFC = make_pipeline(StandardScaler(), RandomForestClassifier(criterion='gini', random_state=1))
#
# Create the parameter grid
#
param_grid_rfc = [{
'randomforestclassifier__max_depth':[2, 3, 4],
'randomforestclassifier__max_features':[2, 3, 4, 5, 6]
}]
#
# Create an instance of GridSearch Cross-validation estimator
#
gsRFC = GridSearchCV(estimator=pipelineRFC,
param_grid = param_grid_rfc,
scoring='accuracy',
cv=10,
refit=True,
n_jobs=1)
#
# Train the RandomForestClassifier
#
gsRFC = gsRFC.fit(X_train, y_train)
#
# Print the training score of the best model
#
print(gsRFC.best_score_)
#
# Print the model parameters of the best model
#
print(gsRFC.best_params_)
#
# Print the test score of the best model
#
clfRFC = gsRFC.best_estimator_
print('Test accuracy: %.3f' % clfRFC.score(X_test, y_test))
Grid Search and Support Vector Classifier (SVC)
When applied to sklearn.svm SVC, one can tune the models against different paramaters such as the following:
- The parameter kernel can be set as linear or rbf
- For kernel value set to linear, the inverse regularization parameter C is set to different values
- For kernel value set to rbf, the inverse regularization parameter C and other parameter gamma is set to different values.
Here is an example demonstrating the usage of Grid Search for selection of most optimal values of hyper parameters for SVC algorithm. Note the parameter grid, param_grid_svc
pipelineSVC = make_pipeline(StandardScaler(), SVC(random_state=1))
#
# Create the parameter grid
#
param_grid_svc = [{
'svc__C': [0.001, 0.01, 0.05, 0.1, 0.5, 1.0, 10.0],
'svc__kernel': ['linear']
},
{
'svc__C': [0.001, 0.01, 0.05, 0.1, 0.5, 1.0, 10.0],
'svc__gamma': [0.001, 0.01, 0.05, 0.1, 0.5, 1.0, 10.0],
'svc__kernel': ['rbf']
}]
#
# Create an instance of GridSearch Cross-validation estimator
#
gsSVC = GridSearchCV(estimator=pipelineSVC,
param_grid = param_grid_svc,
scoring='accuracy',
cv=10,
refit=True,
n_jobs=1)
#
# Train the SVM classifier
#
gsSVC.fit(X_train, y_train)
#
# Print the training score of the best model
#
print(gsSVC.best_score_)
#
# Print the model parameters of the best model
#
print(gsSVC.best_params_)
#
# Print the model score on the test data using GridSearchCV score method
#
print('Test accuracy: %.3f' % gsSVC.score(X_test, y_test))
#
# Print the model score on the test data using Best estimator instance
#
clfSVC = gsSVC.best_estimator_
print('Test accuracy: %.3f' % clfSVC.score(X_test, y_test))
Grid Search and Logistic Regression
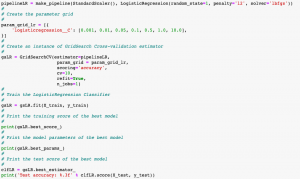
When applied to sklearn.linear_model LogisticRegression, one can tune the models against different paramaters such as inverse regularization parameter C. Note the parameter grid, param_grid_lr. Here is the sample Python sklearn code:
pipelineLR = make_pipeline(StandardScaler(), LogisticRegression(random_state=1, penalty='l2', solver='lbfgs'))
#
# Create the parameter grid
#
param_grid_lr = [{
'logisticregression__C': [0.001, 0.01, 0.05, 0.1, 0.5, 1.0, 10.0],
}]
#
# Create an instance of GridSearch Cross-validation estimator
#
gsLR = GridSearchCV(estimator=pipelineLR,
param_grid = param_grid_lr,
scoring='accuracy',
cv=10,
refit=True,
n_jobs=1)
#
# Train the LogisticRegression Classifier
#
gsLR = gsLR.fit(X_train, y_train)
#
# Print the training score of the best model
#
print(gsLR.best_score_)
#
# Print the model parameters of the best model
#
print(gsLR.best_params_)
#
# Print the test score of the best model
#
clfLR = gsLR.best_estimator_
print('Test accuracy: %.3f' % clfLR.score(X_test, y_test))
Conclusions
Here is the summary of what you learned in relation to Grid Search technique for finding most optimal combination of hyper parameters:
- As like sklearn.model_selection method validation_curve, GridSearchCV can be used to finding the optimal hyper parameters.
- Unlike validation_curve, GridSearchCV can be used to find optimal combination of hyper parameters which can be used to train the model with optimal score.
- Grid search is computationally very expensive. An alternative approach such as randomized search can be used for sampling different parameter combinations.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me