Last updated: 20th August, 2024
Self-supervised learning is an approach to training machine learning models primarily for large corpus of unlabeled dataset. It has gained significant traction due to its effectiveness in various applications related to text and image. Self-supervised learning differs from supervised learning, where models are trained using labeled data, and unsupervised learning, where models are trained using unlabeled data without any pre-defined objectives. Instead, self-supervised learning defines pretext tasks as training models to extract useful features from the data that can be later fine-tuned for specific downstream tasks.
The potential of self-supervised learning has already been demonstrated in many real-world applications, such as image classification, natural language processing, speech recognition, etc. The ability to train models without explicit human labeling makes self-supervised learning more scalable, cost-effective, and adaptable to various domains.
In this blog post, we will explore the key concepts of self-supervised learning witht help of real-world examples. We will also guide you on how to get started with self-supervised learning in Python programming. Whether you are a beginner data scientist or an experienced machine learning practitioner, this blog post will provide valuable insights into the world of self-supervised learning and how it can be used to solve complex real-world problems. I would recommend reading Machine Learning Q and AI by Sebastian Raschka for quick reference.
What is Self-supervised learning (SSL)?
Self-supervised learning (SSL) is a type of machine learning tasks which is similar to transfer learning. It consists of two stages.
- In first stage, we create a pre-trained model with labeled dataset where labels are generated by machine itself, and, not human labeled. In other words, at the outset, the dataset is unlabeled. As part of training task, the labels are generated or extracted by the machine (or program). This is why it is called self-supervised. This task is also called as pretext task or pre-training task. For example, a self-supervised learning task could be a missing-word prediction in an NLP context. For example, given the sentence “it is beautiful and sunny outside,” we can mask out the word “sunny”, feed the network the input “it is beautiful and [MASK] outside,” and have the network predict the missing word in the “[MASK]” location. Similarly, the image patches can be removed in a computer vision context and have the neural network fill in the blanks. The output of first stage is a pre-trained model. This is similar to transfer learning where the output of first stage is pre-trained model. The main difference between transfer learning and self-supervised learning lies in how we obtain the labels during this, first stage. In transfer learning, the labels are human-generated.
- In second stage, the pre-trained model (pretext task) is used to train with another dataset having labels and create the final model.
In pretext task, the objective is to learn useful, descriptive and intelligible representations (features) that can be used for downstream tasks (as in stage 2 mentioned above). For example, in a classical supervised learning for image classification, you would need labeled data set to train the model in order to predict an image belonging to specific class. However, in case of self-supervised learning, what is learned are representations of dataset such as images or text using self-generated labels as mentioned above in stage 1 which can then be used to classify or label images or text respectively belonging to that class in an accurate manner. Check out the details on self-supervised learning in this paper – A cookbook of self-supervised learning (SSL)
Here is a simplistic representation of self-supervised learning pretext tasks in NLP and its relevance for downstream tasks (Image courtesy):
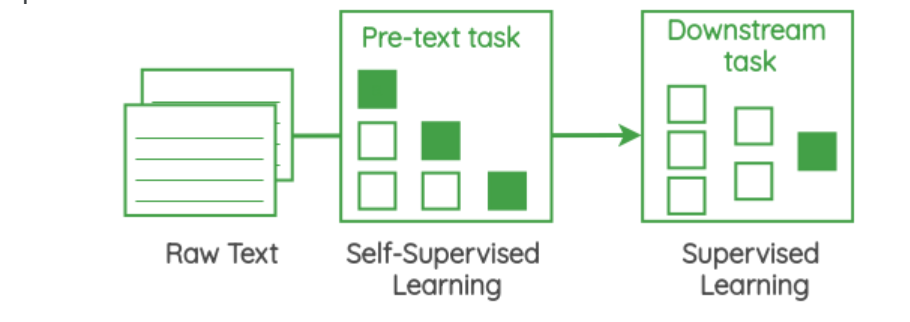
Let’s say, the image with a cat label and dissimilar images of few other animals is provided to be trained using self-supervised learning method. The model learns the representations of the cat in such a manner that it can discriminate the image of cat with other animals’ images with a very high accuracy. This can then be used to identify all the cat images in a large volume of images and label them appropriately.
To summarize, self-supervised learning tasks can be defined as pretext tasks which are used to learn meaningful representations from unlabeled data, without the need for explicit human supervision or labels. These tasks are designed to provide a learning signal to the model that encourages it to extract useful representations of the data, which can later be fine-tuned for specific downstream business tasks across a range of domains and related applications.
The following represents some of the core pretext tasks which can be performed using self-supervised learning methods:
Restoring missing or distorted parts of an input
One of the core objectives of modern self-supervised learning (SSL) methods is to restore missing or distorted parts of an input. This is achieved by training the model to predict the missing or distorted parts of an input, given the remaining intact parts. For example, in image processing, the model might be trained to restore missing parts of an image by predicting the missing pixels based on the surrounding pixels. The most common example of information restoration use case is to mask or remove, a part of an image and then train a neural network to in paint the missing pixel values. This task is known as inpainting and is a common pretext task in SSL for image processing.
The objective of this pretext task is to learn to capture complex relationships among the data and to fill in missing information based on the surrounding context. This can be useful for a wide range of applications, including image restoration, image editing, and video processing. By restoring missing or distorted parts of an input, modern SSL methods can learn to extract useful features that can be applied to various downstream tasks, such as object detection or image classification.
Note that SSL methods for information restoration are particularly useful for videos because videos have lots of different kinds of information or modalities.
Contrasting two views of the same image
Another core objective of modern self-supervised learning (SSL) methods is to contrast two views of the same image. This is achieved by training the model to predict whether two views of the same image are the same or different. This task is known as contrastive learning and is a common pretext task in SSL for computer vision.
The objective of this pretext task is to learn to capture invariant features of the data that are not dependent on the specific view or angle of the input. By contrasting two views of the same image, modern SSL methods can learn to extract robust and invariant features that can be used for various downstream tasks, such as object detection or image classification. This approach has been shown to be highly effective in learning representations that are useful for transfer learning and can improve the performance of models on downstream tasks by leveraging large amounts of unlabeled data.
Generative modeling
Self-supervised learning methods can be useful for generative models, which are used to create new images, videos, or other types of data. There are a couple of methods which can be used to extract intelligible representations. One early SSL method called greedy layer-wise pretraining was used to train deep networks one layer at a time using an autoencoder loss. Another method called generative adversarial networks (GANs) consists of an image generator and a discriminator that can both be trained without supervision. Both of these methods can be used to learn useful representations of the data that can be used for transfer learning. For example, GANs have been used for downstream image classification, and specialized feature learning routines have been developed to improve transfer learning. Overall, SSL methods can help generative models learn to create new and more realistic data by extracting useful features / representations from unlabeled data.
Learning Spatial Context
A class of self-supervised learning methods are used to learn where things are in a picture or scene. For example, one method called RotNet rotates an image and asks the computer to figure out how much it was rotated. Another method called jigsaw breaks a picture into pieces and asks the computer to put the pieces back together in the right way. Yet another method helps with counting how many objects are in a picture. These methods can be useful to learn about the spatial context of pictures, which is important for many different types of downstream tasks.
Differences: Self-supervised, Supervised & Unsupervised Learning
Here are some of the key differences between self-supervised, supervised and unsupervised learning. I would create detailed blog on these differences while providing examples.
| Self-supervised learning | Supervised learning | Unsupervised learning | |
| Data | Unlabeled data | Labeled data | Unlabeled data |
| Objective | Accomplish pretext tasks | Accomplish specific tasks | No predefined objective |
| Use cases | Good for features / representations learning | Good for prediction | Good for clustering / segmentation tasks |
| Example | Predicting context surrounding a word | Predicting house prices | Customer segmentation |
Different Techniques for Self-supervised Learning
In this section, we will look at different techniques of self-supervised learning which are used for learning a latent representation of the data that can be used to solve downstream tasks, without requiring manual labeling of data.
- Leverage data co-occurrences: In this technique, the model learns from the patterns within the same data sample or across different time points in the data. Specifically, the model analyzes co-occurring events, objects, or data points and identifies relationships or correlations between them. By understanding these co-occurrences, the model can learn more about the structure and patterns present in the data, leading to better predictive models or more accurate classifications. An example of this could be predicting the next word in a sentence. The model could look at a large amount of text and try to guess what word might come next in a sentence. By doing this, the model is using the co-occurrences within the same data sample (text) to learn more about the language and how words are used together. Another examples of leveraging co-occurrences within the same data sample can be image colorization, video frame interpolation.
- Leverage co-occurring modality of data: In this technique, the model learns by looking at different things together, like a picture and some words that describe it. For example, if the model is fed with a picture of a dog and the related text modal as “This is a cute puppy!”, it can learn that the word “puppy” means a young dog, and that it is something cute.
- Leverage relationships between the data: In this technique, simply speaking, the model learns about the data by looking at pairs of related data together. For example, the model can be fed a set of related images and it can learn how they are similar or different.
Conclusion
self-supervised learning is a promising approach to machine learning that can leverage large amounts of unlabeled data to extract useful features that can be applied to a wide range of downstream tasks. By training models on pretext tasks, such as restoring missing parts of an input or contrasting two views of the same image, self-supervised learning can learn to capture complex relationships among the data and extract robust and invariant features that are useful for transfer learning.
We discussed several examples of self-supervised learning applications, such as image processing, natural language processing, and generative models, and explored the core objectives of modern SSL methods, including restoring missing parts of an input and learning spatial context. While self-supervised learning is still an active area of research, it has already shown significant promise in improving the performance of machine learning models and enabling the use of large amounts of unlabeled data. As the field continues to evolve, we can expect self-supervised learning to play an increasingly important role in machine learning and artificial intelligence. If you’re interested in learning more about self-supervised learning or want to explore how it can be applied to your specific domain, I encourage you to reach out for further discussion or training.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me