Category Archives: Data Science
Machine Learning Terminologies for Beginners
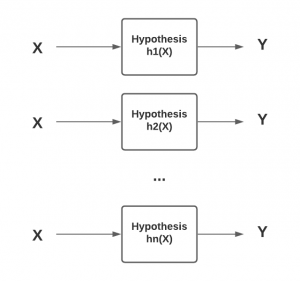
When starting on the journey of learning machine learning and data science, we come across several different terminologies when going through different articles/posts, books & video lectures. Getting a good understanding of these terminologies and related concepts will help us understand these concepts in a nice manner. At a senior level, it gets tricky at times when the team of data scientists / ML engineers explain their projects and related outcomes. With this in context, this post lists down a set of commonly used machine learning terminologies that will help us get a good understanding of ML concepts and also engage with the DS / AI / ML team in …
Machine Learning Free Course at Univ Wisconsin Madison

In this post, you will learn about the free course on machine learning (STAT 451) recently taught at University of Wisconsin-Madison by Dr. Sebastian Raschka. Dr. Sebastian Raschka in currently working as an assistant Professor of Statistics at the University of Wisconsin-Madison while focusing on deep learning and machine learning research. The course is titled as “Introduction to Machine Learning”. The recording of the course lectures can be found on the page – Introduction to machine learning. The course covers some of the following topics: What is machine learning? Nearest neighbour methods Computational foundation Python Programming (concepts) Machine learning in Scikit-learn Tree-based methods Decision trees Ensemble methods Model evaluation techniques Concepts of …
MIT Free Course on Machine Learning (New)

In this post, the information regarding new free course on machine learning launched by MIT OpenCourseware. In case, you are a beginner data scientist or ML Engineer, you will find this course to be very useful. Here is the URL to the free course on machine learning: https://bit.ly/37iNNAA. This course, titled as Introduction to Machine Learning, introduces principles, algorithms, and applications of machine learning from the point of view of modeling and prediction. It includes formulation of learning problems and concepts of representation, over-fitting, and generalization. These concepts are exercised in supervised learning and reinforcement learning, with applications to images and to temporal sequences. Here are some of the key topics for which lectures can be found: …
Gradient Boosting Regression Python Examples
In this post, you will learn about the concepts of Gradient Boosting Regression with the help of Python Sklearn code example. Gradient Boosting algorithm is one of the key boosting machine learning algorithms apart from AdaBoost and XGBoost. What is Gradient Boosting Regression? Gradient Boosting algorithm is used to generate an ensemble model by combining the weak learners or weak predictive models. Gradient boosting algorithm can be used to train models for both regression and classification problem. Gradient Boosting Regression algorithm is used to fit the model which predicts the continuous value. Gradient boosting builds an additive mode by using multiple decision trees of fixed size as weak learners or …
Data Quality Challenges for Analytics Projects

In this post, you will learn about some of the key data quality challenges which you may need to tackle with, if you are working on data analytics projects or planning to get started on data analytics initiatives. If you represent key stakeholders in analytics team, you may find this post to be useful in understanding the data quality challenges. Here are the key challenges in relation to data quality which when taken care would result in great outcomes from analytics projects related to descriptive, predictive and prescriptive analytics: Data accuracy / validation Data consistency Data availability Data discovery Data usability Data SLA Cos-effective data Data Accuracy One of the most important …
Data Science vs Data Engineering Team – Have Both?

In this post, you will learn about different aspects of data science and data engineering team and also understand the key differences between them. As data science / engineering stakeholders, it is very important to understand whether we need to have one or both the teams to achieve high quality dataset & data pipelines as well as high-performant machine learning models. Background When an organization starts on the journey of building data analytics products, primarily based on predictive analytics, it goes on to set up a centralized (mostly) data science team consisting of data scientists. The data science team works with the product team or multiple product teams to gather the …
500+ Machine Learning Interview Questions

This post consists of all the posts on this website in relation to interview questions / quizzes related to data science / machine learning topics. These questions can prove to be helpful for the following: Product managers Data scientists Product Managers Interview Questions Find the questions for product managers on this page – Machine learning interview questions for product managers Data Scientists Interview Questions Here are posts representing 500+ interview questions which will be helpful for data scientists / machine learning engineers. You will find it useful as practise questions and answers while preparing for machine learning interview. Decision tree questions Machine learning validation techniques questions Neural networks questions – …
Spacy Tokenization Python Example

In this post, you will quickly learn about how to use Spacy for reading and tokenising a document read from text file or otherwise. As a data scientist starting on NLP, this is one of those first code which you will be writing to read the text using spaCy. First and foremost, make sure you have got set up with Spacy, and, loaded English tokenizer. The following commands help you set up in Jupyter notebook. Reading text using spaCy: Once you are set up with Spacy and loaded English tokenizer, the following code can be used to read the text from the text file and tokenize the text into words. Pay attention …
Geometric Distribution Explained with Python Examples
In this post, you will learn about the concepts of Geometric probability distribution with the help of real-world examples and Python code examples. It is of utmost importance for data scientists to understand and get an intuition of different kinds of probability distribution including geometric distribution. You may want to check out some of my following posts on other probability distribution. Normal distribution explained with Python examples Binomial distribution explained with 10+ examples Hypergeometric distribution explained with 10+ examples In this post, the following topics have been covered: Geometric probability distribution concepts Geometric distribution python examples Geometric distribution real-world examples Geometric Probability Distribution Concepts Geometric probability distribution is a discrete …
Top 10 Analytics Strategies for Great Data Products
In this post, you will learn about the top 10 data analytics strategies which will help you create successful data products. These strategies will be helpful in case you are setting up a data analytics practice or center of excellence (COE). As an AI / Machine Learning / Data Science stakeholders, it will be important to understand these strategies in order to deliver analytics solution which creates business value having positive business impact. Here are the top 10 data analytics strategies: Identify top 2-3 business problems Identify related business / engineering organizations Create measurement plan by identifying right KPIs Identify analytics deliverables such as analytics reports, predictions etc Gather data …
Keras CNN Image Classification Example
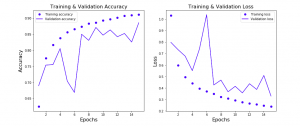
In this post, you will learn about how to train a Keras Convolution Neural Network (CNN) for image classification. Before going ahead and looking at the Python / Keras code examples and related concepts, you may want to check my post on Convolution Neural Network – Simply Explained in order to get a good understanding of CNN concepts. Keras CNN Image Classification Code Example First and foremost, we will need to get the image data for training the model. In this post, Keras CNN used for image classification uses the Kaggle Fashion MNIST dataset. Fashion-MNIST is a dataset of Zalando’s article images—consisting of a training set of 60,000 examples and a …
Data Quality Challenges for Machine Learning Models

In this post, you will learn about some of the key data quality challenges which need to be dealt with in a consistent and sustained manner to ensure high quality machine learning models. Note that high quality models can be termed as models which generalizes better (lower true error with predictions) with unseen data or data derived from larger population. As a data science architect or quality assurance (QA) professional dealing with quality of machine learning models, you must learn some of these challenges and plan appropriate development processes to deal with these challenges. Here are some of the key data quality challenges which need to be tackled appropriately in …
Data Quality Assessment Frameworks – Machine Learning

In this post, you will learn about data quality assessment frameworks / techniques in relation to machine learning and why one needs to assess data quality for building high-performance machine learning models? As a data science architect or development manager, you must get a sense of the importance of data quality in relation to building high-performance machine learning models. The idea is to understand what is the value of data set. The goal is to determine whether the value of data can be quantised. This is because it is important to understand whether the data contains rich information which could be valuable for building models and inform stakeholders on data …
Keras Neural Network for Regression Problem
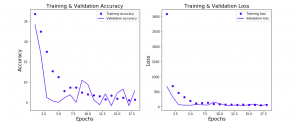
In this post, you will learn about how to train neural network for regression machine learning problems using Python Keras. Regression problems are those which are related to predicting numerical continuous value based on input parameters / features. You may want to check out some of the following posts in relation to how to use Keras to train neural network for classification problems: Keras – How to train neural network to solve multi-class classification Keras – How to use learning curve to select most optimal neural network configuration for training classification model In this post, the following topics are covered: Design Keras neural network architecture for regression Keras neural network …
Keras – Categorical Cross Entropy Loss Function
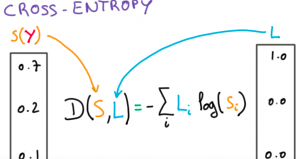
In this post, you will learn about when to use categorical cross entropy loss function when training neural network using Python Keras. Generally speaking, the loss function is used to compute the quantity that the the model should seek to minimize during training. For regression models, the commonly used loss function used is mean squared error function while for classification models predicting the probability, the loss function most commonly used is cross entropy. In this post, you will learn about different types of cross entropy loss function which is used to train the Keras neural network model. Cross entropy loss function is an optimization function which is used in case …
Python Keras – Learning Curve for Classification Model
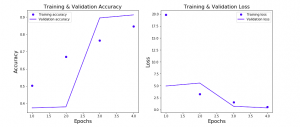
In this post, you will learn about how to train an optimal neural network using Learning Curves and Python Keras. As a data scientist, it is good to understand the concepts of learning curve vis-a-vis neural network classification model to select the most optimal configuration of neural network for training high-performance neural network. In this post, the following topics have been covered: Concepts related to training a classification model using a neural network Python Keras code for creating the most optimal neural network using a learning curve Training a Classification Neural Network Model using Keras Here are some of the key aspects of training a neural network classification model using Keras: …
I found it very helpful. However the differences are not too understandable for me