Tag Archives: machine learning
Data Preprocessing Steps in Machine Learning

Data preprocessing is an essential step in any machine learning project. By cleaning and preparing your data, you can ensure that your machine learning model is as accurate as possible. In this blog post, we’ll cover some of the important and most common data preprocessing steps that every data scientist should know. Replace/remove missing data Before building a machine learning model, it is important to preprocess the data and remove or replace any missing values. Missing data can cause problems with the model, such as biased results or inaccurate predictions. There are a few different ways to handle missing data, but the best approach depends on the situation. In some …
Supply chain management & Machine Learning
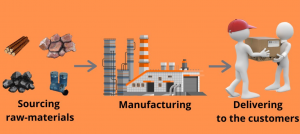
As supply chains become more complex, businesses are looking for new ways to optimize and automate their supply chain operations. One area that is seeing a lot of growth is the use of artificial intelligence (AI) and machine learning in supply chain management. There are many different applications for these technologies in supply chain management, from forecasting demand to optimizing inventory levels. In this blog post, we will explore some of the most interesting use cases for AI and machine learning in supply chain management. What is supply chain management and what are its key components? Supply chain management is the process of coordinating and controlling the flow of goods, …
Car Insurance & Machine Learning Use Cases

The car insurance industry is one of the many sectors that have been disrupted by the advent of machine learning. In the past, car insurance companies have relied on historical data to set premiums. However, machine learning / AI has enabled insurers to better predict risk and price insurance policies more accurately. As a result, AI / machine learning is transforming the car insurance industry by making it more efficient and customer-centric. In this blog, you will learn about some key car insurance use cases which can be dealt using machine learning. Detecting fraudulent car insurance claims Fraudulent car insurance claims are a problem for both insurers and policyholders. They …
Bagging vs Boosting Machine Learning Methods
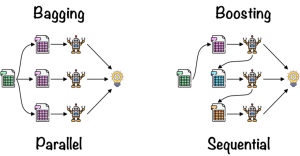
In machine learning, there are a variety of methods that can be used to improve the performance of your models. Two of the most popular methods are bagging and boosting. In this blog post, we’ll take a look at what these methods are and how they work with the help of examples. What is Bagging? Bagging, short for “bootstrap aggregating”, is a method that can be used to improve the accuracy of your machine learning models. The idea behind bagging is to train multiple models on different subsets of the data and then combine the predictions of those models. The data is split into a number of smaller datasets, or …
Weak Supervised Learning: Concepts & Examples
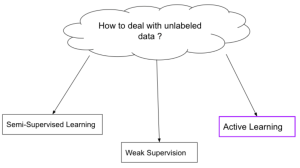
Supervised learning is a type of machine learning algorithm that uses a labeled dataset to learn and generalize from. The labels act as supervisors, providing the algorithm with feedback so it can learn to map input data to the correct output labels. In this blog post, we’ll be focusing on weak supervised learning, a subset of supervised learning that uses only partially labeled or unlabeled data. We’ll cover some of the most common weak supervision techniques and provide examples of each. What is Weak Supervised Learning? Weak supervised learning is a type of machine learning where the learner is only given a few labels to work with. Weak supervision is …
Diabetes Detection & Machine Learning / AI

Diabetes is a chronic disease that affects millions of people worldwide. The early detection of diabetes is crucial to preventing the development of serious complications. However, traditional methods of diabetes detection are often inaccurate and invasive. Machine learning / AI offers a promising solution for the early detection of diabetes. Machine learning algorithms can automatically detect patterns in data and use those patterns to make predictions. Machine learning is well suited for the detection of diabetes because it can handle the large amount of data required for accurate predictions. In addition, machine learning algorithms can automatically identify patterns that are too subtle for humans to discern. Quick Overview on Machine …
Healthcare Claims Processing AI Use Cases
In recent years, artificial intelligence (AI) / machine learning (ML) has begun to revolutionize many industries – and healthcare is no exception. Hospitals and insurance companies are now using AI to automate various tasks in the healthcare claims processing workflow. Claims processing is a complex and time-consuming task that often requires manual intervention. By using AI to automate claims processing, healthcare organizations can reduce costs, improve accuracy, and speed up the claims adjudication process. In this blog post, we will explore some of the most common use cases for healthcare claims processing AI / machine learning. Automated Data Entry One of the most time-consuming tasks in the claims process is …
ESG & AI / Machine Learning Use Cases

Environmental, social, and governance (ESG) factors are a set of standards used to evaluate a company’s performance on issues that have an impact on society and the environment. AI or machine learning can be used to help identify these factors. In this blog post, we will explore some use cases for how AI / machine learning can be used in conjunction with ESG factors. The following is a list of AI use cases related ESG. This list will be updated from time-to-time. Predict ESG ratings using fundamental dataset: Investors (asset managers and asset owners) started to assess companies based on how they handle sustainability issues. To do this assessment, investors …
Machine Learning with Limited Labeled Data
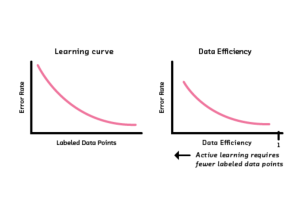
One of the biggest challenges in machine learning is having enough labeled data to train a model. This is especially true for supervised learning tasks such as image classification, where a large dataset is often required. However, what do you do when you only have limited labeled data? In this blog post, we will discuss some of the following techniques that can be used to train machine learning models when you only have limited labeled data. Self-supervised learning Semi-supervised learning Weakly-supervised learning Active learning Few/zero-shot learning Transfer learning Challenges with Machine Learning models trained with limited labeled data When a machine learning model is trained with limited labeled data, it …
List of Machine Learning Topics for Learning

Are you looking for a list of machine learning topics to learn more about? If so, you’ve come to the right place. In this post, we will share a variety of machine learning topics that you can explore to boost your knowledge and skills. So, whether you’re a data scientist or machine learning engineer, there’s something here for everyone. The following represents a list of topics which can be taken up for learning and mastering artificial intelligence / machine learning: Introduction to data science Introduction to machine learning Check out this detailed post on machine learning concepts & examples. Introduction to deep learning Introduction to reinforcement learning Introduction to linear …
Model Compression Techniques – Machine Learning
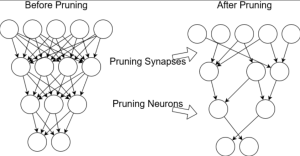
In recent years, there has been an explosion of interest in machine learning (ML). This is due in large part to the availability of powerful and affordable hardware, as well as the development of new ML algorithms that are able to achieve state-of-the-art results on a variety of tasks. However, one of the challenges of using ML is that many algorithms require a large amount of data and computational resources in order to train a model that generalizes well to new data. To address this challenge, a number of model compression techniques have been developed that allow for the training of smaller, more efficient models that still achieve good performance …
What are Features in Machine Learning?
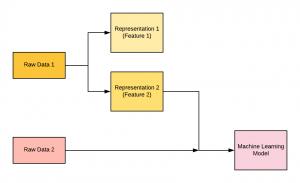
Machine learning is a field of machine intelligence concerned with the design and development of algorithms and models that allow computers to learn without being explicitly programmed. Machine learning has many applications including those related to regression, classification, clustering, natural language processing, audio and video related, computer vision, etc. Machine learning requires training one or more models using different algorithms. Check out this detailed post in relation to learning machine learning concepts – What is Machine Learning? Concepts & Examples. One of the most important aspects of the machine learning model is identifying the features which will help create a great model, the model that performs well on unseen data. …
K-Nearest Neighbors (KNN) Python Examples
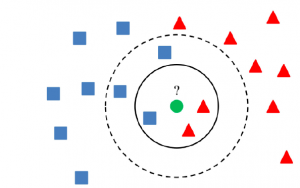
If you’re working with data analytics projects including building machine learning (ML) models, you’ve probably heard of the K-nearest neighbors (KNN) algorithm. But what is it, exactly? And more importantly, how can you use it in your own AI / ML projects? In this post, we’ll take a closer look at the KNN algorithm and walk through a simple Python example. You will learn about the K-nearest neighbors algorithm with Python Sklearn examples. K-nearest neighbors algorithm is used for solving both classification and regression machine learning problems. Stay tuned! Introduction to K-Nearest Neighbors (K-NN) Algorithm K-nearest neighbors is a supervised machine learning algorithm for classification and regression. In both cases, the input consists …
How to Identify Use Cases for AI / Machine Learning
As artificial intelligence (AI ) and machine learning (ML) solutions and technologies continue to evolve, more and more businesses are looking for ways to incorporate them into their operations to realize a greater business impact. But with so many potential applications, it can be difficult to know where to start. In this blog post, we’ll outline some tips for identifying AI / ML use cases. We’ll also provide a few examples of how AI & machine learning can be used in business settings. So if you’re thinking about adding AI or machine learning to your toolkit, read on! This blog post will be appropriate for product managers, business analysts, data science …
Predicting Customer Churn with Machine Learning

Customer churn, also known as customer attrition, is a major problem for businesses that rely on recurring revenue. Customer churn costs businesses billions of dollars every year, and it’s only getting worse as customers become more and more fickle. In fact, it’s been estimated that the average company loses 10-15% of its customers each year. That number may seem small, but it can have a huge impact on a company’s bottom line. Fortunately, there’s a way to combat churn: by using machine learning to predict which customers are likely to churn. In this blog post, we’ll discuss how customer churn prediction works and why it’s so important. We’ll also provide …
Stacking Classifier Sklearn Python Example

In this blog post, we will be going over a very simple example of how to train a stacking classifier machine learning model in Python using the Sklearn library and learn the concepts of stacking classifier. A stacking classifier is an ensemble learning method that combines multiple classification models to create one “super” model. This can often lead to improved performance, since the combined model can learn from the strengths of each individual model. What are Stacking Classifiers? Stacking is a machine learning ensemble technique that combines multiple models to form a single powerful model. The individual models are trained on different subsets of the data using some type of …
I found it very helpful. However the differences are not too understandable for me