Tag Archives: machine learning
Boston Housing Dataset Linear Regression: Predicting House Prices
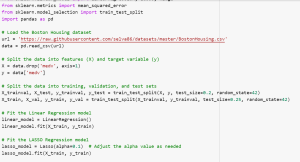
Predicting house prices accurately is crucial in the real estate industry. However, it can be challenging to determine the factors that significantly impact house prices. Without a clear understanding of these factors, accurate predictions are difficult to achieve. The Boston Housing Dataset addresses this problem by providing a comprehensive set of variables that influence house prices in the Boston area. However, effectively utilizing this dataset and building robust predictive models require appropriate techniques and evaluation methods. In this blog, we will provide an overview of the Boston Housing Dataset and explore linear regression, LASSO, and Ridge regression as potential models for predicting house prices. Each model has its unique properties …
ChatGPT Cheat Sheet for Data Scientists

With the explosion of data being generated, data scientists are facing increased pressure to analyze and interpret large amounts of text data effectively. However, this can be a challenging task, especially when dealing with unstructured data. Additionally, data scientists often spend a significant amount of time manually generating text and answering complex questions, which can be a time-consuming process. Welcome ChatGPT! ChatGPT offer a powerful solution to these challenges. By learning different ChatGPT prompts, data scientists can significantly become super productive while generating relevant insights, answer complex questions, and perform machine learning tasks with ease such as data preprocessing, hypothesis testing, training models, etc. In this blog, I will provide …
How does Dall-E 2 Work? Concepts, Examples
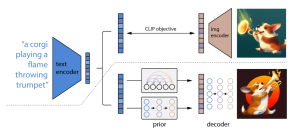
Have you ever wondered how generative AI is converting words into images? Or how generative AI models create a picture of something you’ve only described in words? Creating high-quality images from textual descriptions has long been a challenge for artificial intelligence (AI) researchers. That’s where DALL-E and DALL-E 2 comes in. In this blog, we will look into the details related to Dall-E 2. Developed by OpenAI, DALL-E 2 is a cutting-edge AI model that can generate highly realistic images from textual descriptions. So how does DALL-E 2 work, and what makes it so special? In this blog post, we’ll explore the key concepts and techniques behind DALL-E 2, including …
Gaussian Mixture Models: What are they & when to use?
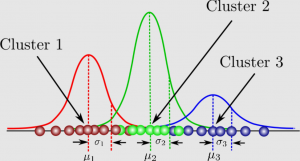
In machine learning and data analysis, it is often necessary to identify patterns and clusters within large sets of data. However, traditional clustering algorithms such as k-means clustering have limitations when it comes to identifying clusters with different shapes and sizes. This is where Gaussian mixture models (GMMs) come in. But what exactly are GMMs and when should you use them? Gaussian mixture models (GMMs) are a type of machine learning algorithm. They are used to classify data into different categories based on the probability distribution. Gaussian mixture models can be used in many different areas, including finance, marketing and so much more! In this blog, an introduction to gaussian …
NLP: Huggingface Transformers Code Examples
Do you want to build cutting-edge NLP models? Have you heard of Huggingface Transformers? Huggingface Transformers is a popular open-source library for NLP, which provides pre-trained machine learning models and tools to build custom NLP models. These models are based on Transformers architecture, which has revolutionized the field of NLP by enabling state-of-the-art performance on a range of NLP tasks. In this blog post, I will provide Python code examples for using Huggingface Transformers for various NLP tasks such as text classification (sentiment analysis), named entity recognition, question answering, text summarization, and text generation. I used Google Colab for testing my code. Before getting started, get set up with transformers …
Sklearn Algorithms Cheat Sheet with Examples

The Sklearn library, short for Scikit-learn, is one of the most popular and widely-used libraries for machine learning in Python. It offers a comprehensive set of tools for data analysis, preprocessing, model selection, and evaluation. As a beginner data scientist, it can be overwhelming to navigate the various algorithms and functions within Sklearn. This is where the Sklearn Algorithms Cheat Sheet comes in handy. This cheat sheet provides a quick reference guide for beginners to easily understand and select the appropriate algorithm for their specific task. In this cheat sheet, I have compiled a list of common supervised and unsupervised learning algorithms, along with their Sklearn classes and example use …
Supervised & Unsupervised Learning Difference
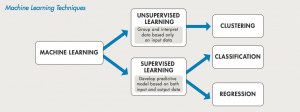
Supervised and unsupervised learning are two different common types of machine learning tasks that are used to solve many different types of business problems. Supervised learning uses training data with labels to create supervised models, which can be used to predict outcomes for future datasets. Unsupervised learning is a type of machine learning task where the training data is not labeled or categorized in any way. For beginner data scientists, it is very important to get a good understanding of the difference between supervised and unsupervised learning. In this post, we will discuss how supervised and unsupervised algorithms work and what is difference between them. You may want to check …
Machine Learning: Inference & Prediction Difference

In machine learning, prediction and inference are two different concepts. Prediction is the process of using a model to make a prediction about something that is yet to happen. The inference is the process of evaluating the relationship between the predictor and response variables. In this blog post, you will learn about the differences between prediction and inference with the help of examples. Before getting into the details related to inference & prediction, let’s quickly recall the machine learning basic concepts. What is machine learning and how is it related with inference & prediction? Machine learning is about learning an approximate function that can be used to predict the value …
Sklearn Neural Network Example – MLPRegressor
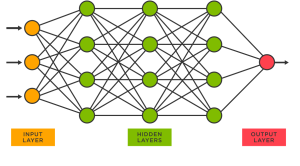
Are you interested in using neural networks to solve complex regression problems, but not sure where to start? Sklearn’s MLPRegressor can help you get started with building neural network models for regression tasks. While the packages from Keras, Tensorflow or PyTorch are powerful and widely used in deep learning, Sklearn’s MLPRegressor is still an excellent choice for building neural network models for regression tasks when you are starting on. Recall that Python Sklearn library is one of the most popular machine learning libraries, and it provides a wide range of algorithms for classification, regression, clustering, dimensionality reduction, and more. In this blog post, we will be focusing on training a …
Neural Networks Interview Questions – Quiz #45

Are you preparing for a job interview in the field of deep learning or neural networks? If so, you’re likely aware of how complex and technical these topics can be. In order to help you prepare, we’ve put together a list of common neural network interview questions and answers in form of multiple-choice quiz. The quiz in this blog post covers basic concepts related to neural network layers, perceptron, multilayer perceptron, activation functions, feedforward networks, backpropagation, and more. We’ve included 15 multiple-choice questions, as well as 5 additional questions specifically focused on the backpropagation algorithm. I will be posting many more quizzes on the neural networks in time to come, …
Google’s Free Machine Learning Courses: Learn from the Best

Machine learning has become a fundamental part of almost every industry today. With the increasing demand for data scientists and machine learning engineers, it has become imperative for professionals to keep themselves updated with the latest tools and techniques. Fortunately, Google offers a range of free machine learning courses that cater to professionals of all expertise levels. In this blog, we will explore the top Google machine learning courses that will help learners enhance their skills and stay ahead of the game. List of Free Machine Learning Courses by Google The following is a list of free machine learning courses from Google which you can take online. These courses can …
Lung Disease Prediction using Machine Learning
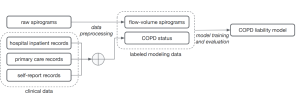
Lung diseases, including chronic obstructive pulmonary disease (COPD), are a leading cause of death worldwide. Early detection and treatment are critical for improving patient outcomes, but diagnosing lung diseases can be challenging. Machine learning (ML) models are transforming the field of pulmonology by enabling faster and more accurate prediction of lung diseases including COPD. In this blog, we’ll discuss the challenges of detecting / predicting lung diseases using machine learning, the clinical dataset used in research, supervised learning method used for building machine learning models. Challenges in Detecting Lung Diseases with Machine Learning Detecting and predicting lung diseases using machine learning can be challenging due to a lack of labeled …
KMeans Silhouette Score Python Example
If you’re building machine learning models for solving different prediction problems, you’ve probably heard of clustering. Clustering is a popular unsupervised learning technique used to group data points with similar features into distinct clusters. One of the most widely used clustering algorithms is KMeans, which is popular due to its simplicity and efficiency. However, one major challenge in clustering is determining the optimal number of clusters that should be used to group the data points. This is where the Silhouette Score comes into play, as it helps us measure the quality of clustering and determine the optimal number of clusters. Silhouette score helps us get further clarity for the following …
ChatGPT Prompt for Job Interview Preparation

Preparing for a job interview can be a nerve-wracking experience. It’s natural to feel a sense of pressure as you try to impress your potential employer and secure the job you’ve been dreaming of. However, with the right preparation, you can increase your chances of acing the interview and landing the job. That’s where ChatGPT comes in. As a powerful language model trained by OpenAI, ChatGPT is equipped with the knowledge and expertise to provide you with valuable insights and prompts to help you prepare for your job interview. In this blog, we’ll explore some of the ways that ChatGPT can assist you in your job interview preparation. Whether you’re …
Why & When to use Eigenvalues & Eigenvectors?

Eigenvalues and eigenvectors are important concepts in linear algebra that have numerous applications in data science. They provide a way to analyze the structure of linear transformations and matrices, and are used extensively in many areas of machine learning, including feature extraction, dimensionality reduction, and clustering. In simple terms, eigenvalues and eigenvectors are the building blocks of linear transformations. Eigenvalues represent the scaling factor by which a vector is transformed when a linear transformation is applied, while eigenvectors represent the directions in which the transformation occurs. In this post, you will learn about why and when you need to use Eigenvalues and Eigenvectors? As a data scientist/machine learning Engineer, one must …
Amazon Bedrock to Democratize Generative AI
Amazon Web Services (AWS) has announced the launch of Amazon Bedrock and Amazon Titan foundational models (FMs), making it easier for customers to build and scale generative AI applications with foundation models. According to AWS, they received feedback from their select customers that there are a few big things standing in their way today in relation to different AI use cases. First, they need a straightforward way to find and access high-performing FMs that give outstanding results and are best-suited for their purposes. Second, customers want integration into applications to be seamless, without having to manage huge clusters of infrastructure or incur large costs. Finally, customers want it to be …
I found it very helpful. However the differences are not too understandable for me