
In this blog post, we will be going over a very simple example of how to train a stacking classifier machine learning model in Python using the Sklearn library and learn the concepts of stacking classifier. A stacking classifier is an ensemble learning method that combines multiple classification models to create one “super” model. This can often lead to improved performance, since the combined model can learn from the strengths of each individual model.
What are Stacking Classifiers?
Stacking is a machine learning ensemble technique that combines multiple models to form a single powerful model. The individual models are trained on different subsets of the data using some type of cross-validation technique, such as k-fold cross-validation, and then the predictions from each model are combined to make the final prediction. This approach can often lead to improved performance, as the different models can learn complementary information. Stacking is also useful for dealing with imbalanced datasets, as it can reduce the variance of the predictions. In addition, stacking can be used to combine different types of models, such as decision trees and neural networks. However, stacking is a more complex approach than some other machine learning techniques, and so it is important to carefully tune the individual models and the way in which they are combined.
A stacking classifier is a type of stacking that uses classification models. The basic idea behind a stacking classifier is to use a combination of different types of classifiers to improve the accuracy of the final predictions. For example, a stacking classifier could combine the predictions of a logistic regression model with those of a support vector machine. The individual models are trained on different subsets of the data, and then the predictions are combined using a meta-classifier.
There are many reasons why you might want to use a stacking classifier. First, it can help to improve the predictive power of your model. If your individual classifiers are not strong enough on their own, then stacking them together can help to create a more accurate prediction. Second, stacking can help to reduce overfitting. By training each classifier on a different subset of the data, you can reduce the chance of overfitting your model to the training data. Third, stacking can be used to improve the interpretability of your model. If you are using a complex ensemble technique like boosting or deep learning, then it can be difficult to understand how the final predictions are being made. However, if you stack together a number of simpler models, then it can be easier to understand how the final predictions are being made.
Stacking Classifier Python Example using Sklearn library
First and foremost, we’ll need to import the necessary libraries. We’ll be using Sklearn for this example, so we’ll need to import the “StackingClassifier” module from Sklearn.
Next, we’ll define our data. For this example, we’ll be using the Sklearn.datasets IRIS dataset. The iris dataset consists of 150 samples of different types of flowers, each with 4 features (sepal length, sepal width, petal length, and petal width). We have 3 classes in this dataset (Iris Setosa, Iris Versicolor, and Iris Virginica), so this will be a 3-class classification problem.
Now that we have our data loaded and our libraries imported, we can define our models. For this example, we’ll be using 3 different models: a logistic regression, an XGBoost classifier, and a Random forest classifier model.
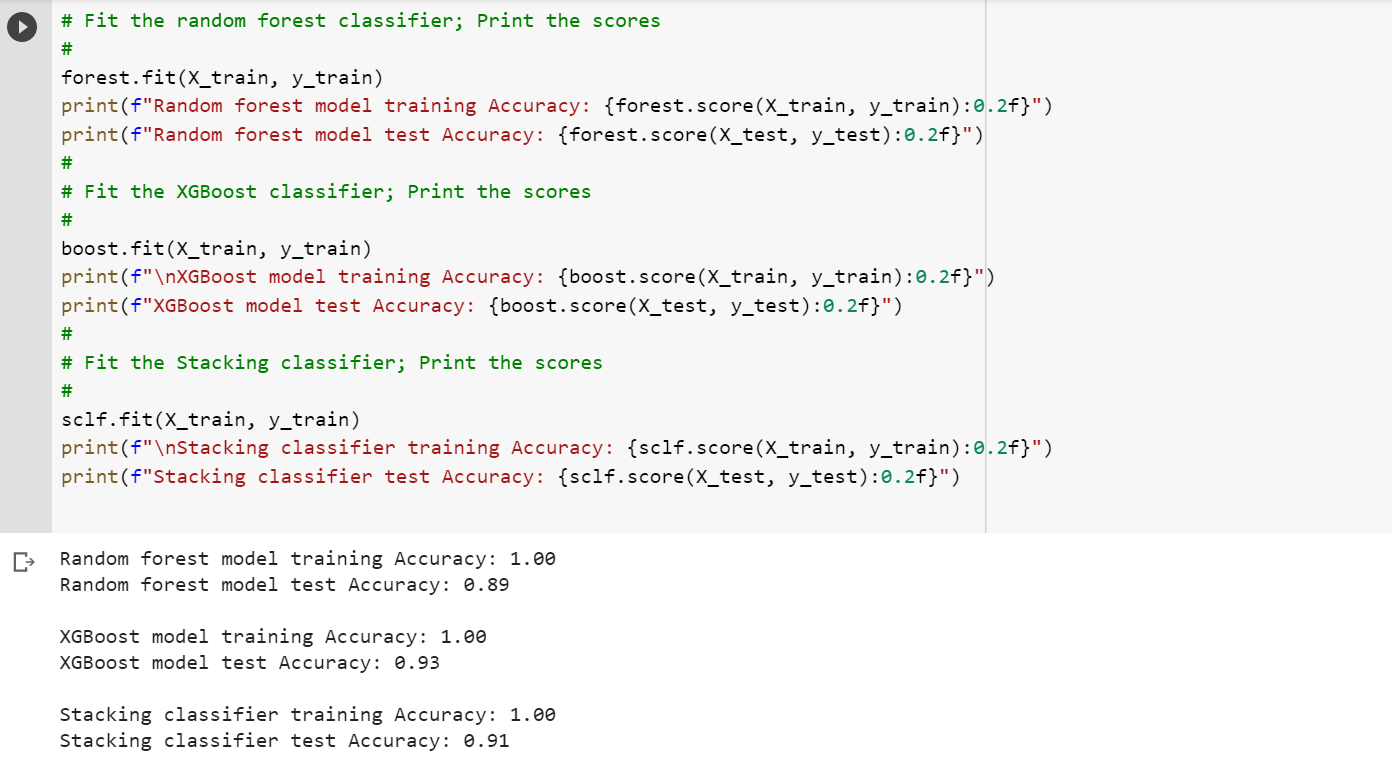
Once we have our models defined, we can fit them to our data and make predictions. For each model, we’ll print out the accuracy score on the test set to see how well it performs.
Finally, we’ll create our stacking classifier by initializing it with our individual models. Then, we’ll fit it to our data and make predictions on the test set. Again, we’ll print out the accuracy score to see how well it performs. The code below represents the above steps.
from sklearn.ensemble import RandomForestClassifier
from xgboost import XGBClassifier
from sklearn.ensemble import StackingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn import datasets
#
# Load the IRIS dataset
#
iris = datasets.load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42, stratify=y)
#
# Create a Randomforest classifier
#
forest = RandomForestClassifier(n_estimators=100,
random_state=123)
#
# Create a XGBoost classifier
#
boost = XGBClassifier(random_state=123, verbosity=0, use_label_encoder=False)
#
# Create a Logistic regression classifier
#
lgclassifier = LogisticRegression(random_state=123)
#
# Create a stacking classifier
#
estimators = [
('rf', forest),
('xgb', boost)
]
sclf = StackingClassifier(estimators=estimators,
final_estimator=lgclassifier,
cv=10)
#
# Fit the random forest classifier; Print the scores
#
forest.fit(X_train, y_train)
print(f"Random forest model training Accuracy: {forest.score(X_train, y_train):0.2f}")
print(f"Random forest model test Accuracy: {forest.score(X_test, y_test):0.2f}")
#
# Fit the XGBoost classifier; Print the scores
#
boost.fit(X_train, y_train)
print(f"\nXGBoost model training Accuracy: {boost.score(X_train, y_train):0.2f}")
print(f"XGBoost model test Accuracy: {boost.score(X_test, y_test):0.2f}")
#
# Fit the Stacking classifier; Print the scores
#
sclf.fit(X_train, y_train)
print(f"\nStacking classifier training Accuracy: {sclf.score(X_train, y_train):0.2f}")
print(f"Stacking classifier test Accuracy: {sclf.score(X_test, y_test):0.2f}"
Conclusion
Stacking classifiers are a powerful ensemble learning method that can often lead to improved performance over individual models. In this blog post, we went over a very simple example of how to use a stacking classifier in Python using the Sklearn library. Try experimenting with different datasets and different types of models to see how well they stack up!

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
- What is Embodied AI? Explained with Examples - May 11, 2025
- Retrieval Augmented Generation (RAG) & LLM: Examples - February 15, 2025
I found it very helpful. However the differences are not too understandable for me