One of the biggest challenges in machine learning is having enough labeled data to train a model. This is especially true for supervised learning tasks such as image classification, where a large dataset is often required. However, what do you do when you only have limited labeled data? In this blog post, we will discuss some of the following techniques that can be used to train machine learning models when you only have limited labeled data.
- Self-supervised learning
- Semi-supervised learning
- Weakly-supervised learning
- Active learning
- Few/zero-shot learning
- Transfer learning
Challenges with Machine Learning models trained with limited labeled data
When a machine learning model is trained with limited labeled data, it can be more challenging to achieve accurate results. This is because the model has a smaller data set to learn from, and so it may not be able to accurately identify all of the patterns in the data. As a result, the model may be more likely to make mistakes when predicting outcomes. Additionally, limited labeled data can also lead to a decreased ability to generalize, or apply what is learned in one situation to another situations. This is because the model has less information to rely on when making decisions, and so is less likely to be able to generalize appropriately. Finally, limited labeled data can also lead to overfitting, which occurs when a model has been trained on too few data points and begins to “learn” the noise in the data instead of the actual patterns. This leads to inaccurate predictions, as the model is not able to account for variations in the data that may not have been observed during training.
Self-supervised learning with limited labeled data
Self-supervised learning is a machine learning technique for building models with limited labeled data. It is an unsupervised learning technique that generates labels automatically from the data. The labels are then used to train the model. Self-supervised learning has been shown to be effective in many tasks such as image classification, text classification, and speech recognition. In self-supervised learning, the model is not given any labeled data. Instead, it tries to learn from the data itself. This makes self-supervised learning very powerful when there is limited labeled data available.
Semi-supervised learning with limited labeled data
Semi-supervised learning is a technique for building models with limited labeled data. The goal is to use both the labeled and unlabeled data to learn a model that generalizes well to new data. Semi-supervised learning is often used in machine learning applications where it is difficult or expensive to label data. For example, imagine you want to build a model to classify images of animals. If you only have a few labeled examples of each animal, you can use semi-supervised learning to learn from both the labeled and unlabeled data.
Weakly supervised learning with limited labeled data
Weakly supervised learning is a machine learning technique that can be used to build models with limited labeled data. This technique relies on weak labels, which are labels that are not necessarily accurate or complete. Weakly supervised learning algorithms can learn from these labels by making assumptions about the underlying structure of the data. For example, they may assume that all instances with the same label are similar. By making these assumptions, weakly supervised learning algorithms can learn from less data than traditional supervised learning algorithms. This can be especially helpful when labeled data is scarce or expensive to obtain.
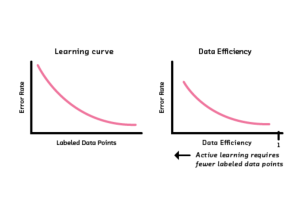
Active learning with limited labeled data
Active learning is a machine learning methodology that can be used to train models with limited labeled data. The active learning process begins with a small amount of labeled data, which is then used to train a model. The model is then used to label new data, which is added to the labeled dataset. This process is repeated until the model converges on a reliable solution. Active learning can be used to build models for a variety of tasks, including classification, regression, and clustering. Active learning is particularly well suited for tasks that are difficult to label, such as image recognition and text classification. Active learning can also help to reduce the cost of labeling by reducing the number of labels that need to be generated.
Conclusion
When you only have limited labeled data, it can be challenging to train a machine learning model. However, there are several ways that you can overcome this challenge. Some of the ways are to use transfer learning, active learning, self-supervised learning, semi-supervised learning and weakly supervised learning. One can use of these techniques based on the different scenarios.

Check out my latest book titled as First Principles Thinking: Building winning products using first principles thinking.
- Mathematics Topics for Machine Learning Beginners - July 6, 2025
- Questions to Ask When Thinking Like a Product Leader - July 3, 2025
- Three Approaches to Creating AI Agents: Code Examples - June 27, 2025
I found it very helpful. However the differences are not too understandable for me